正在加载图片...
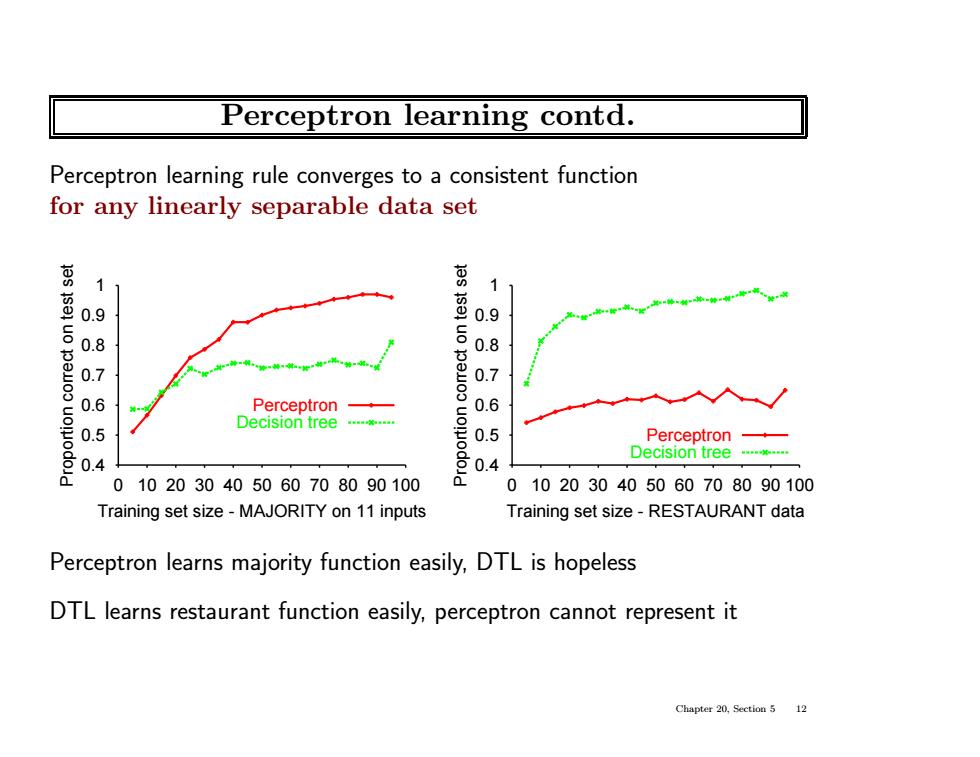
Perceptron learning contd. Perceptron learning rule converges to a consistent function for any linearly separable data set 11 1 0.9 0.9 0.8 0.7 0.7 0.6 Perceptron 0.5 Decision tree 0.5 Perceptron 0.4 0.4 Decision tree 0102030405060708090100 0102030405060708090100 Training set size-MAJORITY on 11 inputs Training set size-RESTAURANT data Perceptron learns majority function easily,DTL is hopeless DTL learns restaurant function easily,perceptron cannot represent it Chapter 20,Section 5 12 Perceptron learning contd. Perceptron learning rule converges to a consistent function for any linearly separable data set 0.4 0.5 0.6 0.7 0.8 0.9 1 Proportion correct on test set 0 10 20 30 40 50 60 70 80 90 100 Training set size - MAJORITY on 11 inputs Perceptron Decision tree 0.4 0.5 0.6 0.7 0.8 0.9 1 Proportion correct on test set 0 10 20 30 40 50 60 70 80 90 100 Training set size - RESTAURANT data Perceptron Decision tree Perceptron learns majority function easily, DTL is hopeless DTL learns restaurant function easily, perceptron cannot represent it Chapter 20, Section 5 12