正在加载图片...
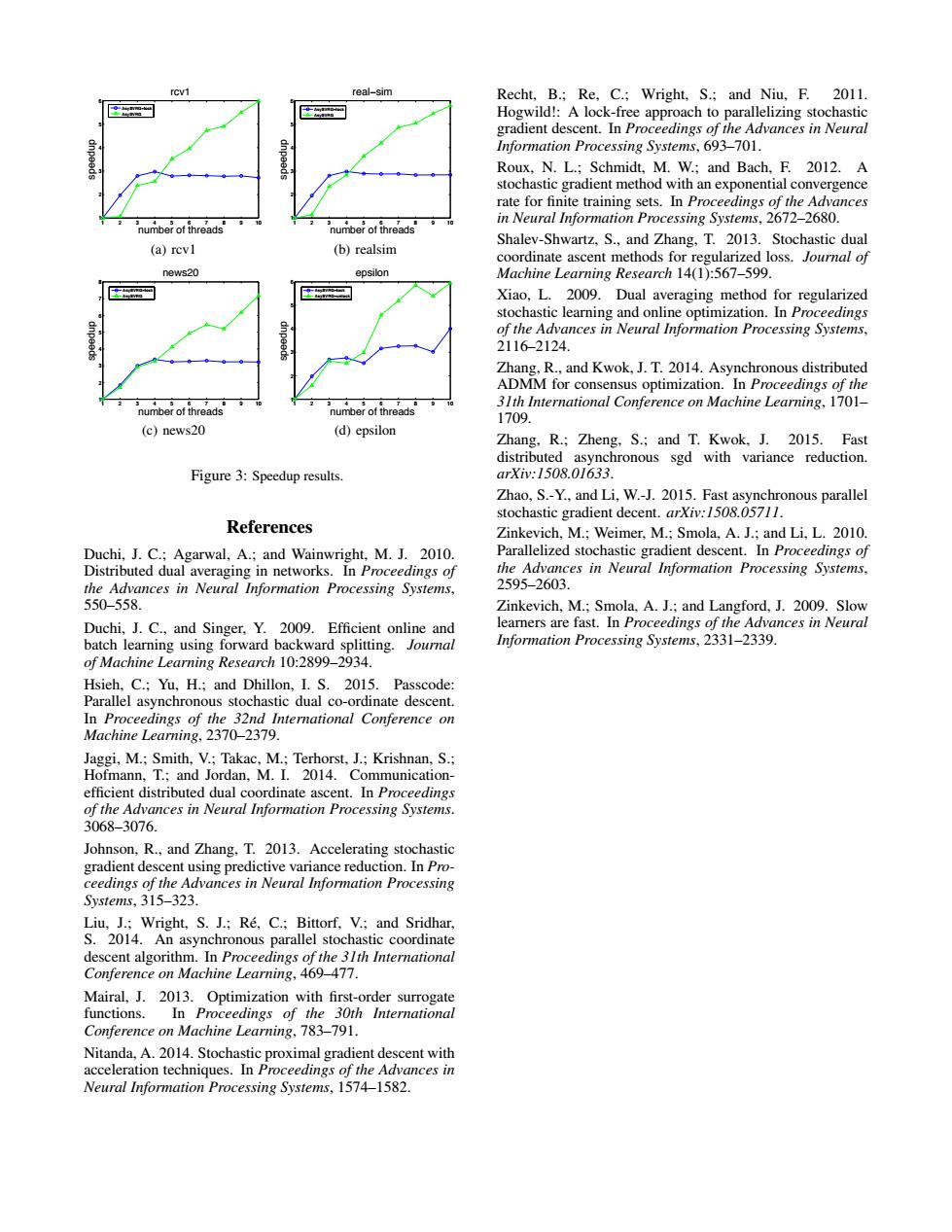
rcv1 real-sim Recht,B.;Re,C.;Wright,S.;and Niu,F.2011. Hogwild!:A lock-free approach to parallelizing stochastic gradient descent.In Proceedings of the Advances in Neural Information Processing Systems,693-701. Roux,N.L.;Schmidt,M.W.;and Bach,F.2012.A stochastic gradient method with an exponential convergence rate for finite training sets.In Proceedings of the Advances number of threads in Neural Information Processing Systems,2672-2680. (a)rev1 (b)realsim Shalev-Shwartz,S.,and Zhang,T.2013.Stochastic dual coordinate ascent methods for regularized loss.Journal of news20 epsilon Machine Learning Research 14(1):567-599. Xiao,L.2009.Dual averaging method for regularized stochastic learning and online optimization.In Proceedings of the Advances in Neural Information Processing Systems, 2116-2124 Zhang,R.,and Kwok,J.T.2014.Asynchronous distributed ADMM for consensus optimization.In Proceedings of the number of threads 31th International Conference on Machine Learning,1701- number of threads 1709 (c)news20 (d)epsilon Zhang,R.;Zheng,S.;and T.Kwok,J.2015.Fast distributed asynchronous sgd with variance reduction. Figure 3:Speedup results. arXi:1508.01633. Zhao,S.-Y.,and Li,W.-J.2015.Fast asynchronous parallel stochastic gradient decent.arXiv:1508.05711. References Zinkevich,M.;Weimer,M.;Smola,A.J.;and Li,L.2010. Duchi,J.C.;Agarwal,A.;and Wainwright,M.J.2010. Parallelized stochastic gradient descent.In Proceedings of Distributed dual averaging in networks.In Proceedings of the Advances in Neural Information Processing Systems, the Advances in Neural Information Processing Systems, 2595-2603. 550-558. Zinkevich,M.;Smola,A.J.;and Langford,J.2009.Slow Duchi,J.C.,and Singer,Y.2009.Efficient online and learners are fast.In Proceedings of the Advances in Neural batch learning using forward backward splitting.Journal Information Processing Systems,2331-2339. of Machine Learning Research 10:2899-2934. Hsieh,C.;Yu,H.;and Dhillon,I.S.2015.Passcode: Parallel asynchronous stochastic dual co-ordinate descent. In Proceedings of the 32nd International Conference on Machine Learning,2370-2379. Jaggi,M.;Smith,V.;Takac,M.;Terhorst,J.;Krishnan,S.; Hofmann.T.:and Jordan.M.I.2014.Communication- efficient distributed dual coordinate ascent.In Proceedings of the Advances in Neural Information Processing Systems. 3068-3076. Johnson,R.,and Zhang,T.2013.Accelerating stochastic gradient descent using predictive variance reduction.In Pro- ceedings of the Advances in Neural Information Processing Systems,315-323. Liu,J.;Wright,S.J.;Re,C.;Bittorf,V.;and Sridhar, S.2014.An asynchronous parallel stochastic coordinate descent algorithm.In Proceedings of the 31th International Conference on Machine Learning,469-477. Mairal,J.2013.Optimization with first-order surrogate functions. In Proceedings of the 30th International Conference on Machine Learning,783-791. Nitanda,A.2014.Stochastic proximal gradient descent with acceleration techniques.In Proceedings of the Advances in Neural Information Processing Systems,1574-1582.1 2 3 4 5 6 7 8 9 10 1 2 3 4 5 6 number of threads speedup rcv1 AsySVRG−lock AsySVRG (a) rcv1 1 2 3 4 5 6 7 8 9 10 1 2 3 4 5 6 number of threads speedup real−sim AsySVRG−lock AsySVRG (b) realsim 1 2 3 4 5 6 7 8 9 10 1 2 3 4 5 6 7 8 number of threads speedup news20 AsySVRG−lock AsySVRG (c) news20 1 2 3 4 5 6 7 8 9 10 1 2 3 4 5 6 number of threads speedup epsilon AsySVRG−lock AsySVRG−unlock (d) epsilon Figure 3: Speedup results. References Duchi, J. C.; Agarwal, A.; and Wainwright, M. J. 2010. Distributed dual averaging in networks. In Proceedings of the Advances in Neural Information Processing Systems, 550–558. Duchi, J. C., and Singer, Y. 2009. Efficient online and batch learning using forward backward splitting. Journal of Machine Learning Research 10:2899–2934. Hsieh, C.; Yu, H.; and Dhillon, I. S. 2015. Passcode: Parallel asynchronous stochastic dual co-ordinate descent. In Proceedings of the 32nd International Conference on Machine Learning, 2370–2379. Jaggi, M.; Smith, V.; Takac, M.; Terhorst, J.; Krishnan, S.; Hofmann, T.; and Jordan, M. I. 2014. Communicationefficient distributed dual coordinate ascent. In Proceedings of the Advances in Neural Information Processing Systems. 3068–3076. Johnson, R., and Zhang, T. 2013. Accelerating stochastic gradient descent using predictive variance reduction. In Proceedings of the Advances in Neural Information Processing Systems, 315–323. Liu, J.; Wright, S. J.; Re, C.; Bittorf, V.; and Sridhar, ´ S. 2014. An asynchronous parallel stochastic coordinate descent algorithm. In Proceedings of the 31th International Conference on Machine Learning, 469–477. Mairal, J. 2013. Optimization with first-order surrogate functions. In Proceedings of the 30th International Conference on Machine Learning, 783–791. Nitanda, A. 2014. Stochastic proximal gradient descent with acceleration techniques. In Proceedings of the Advances in Neural Information Processing Systems, 1574–1582. Recht, B.; Re, C.; Wright, S.; and Niu, F. 2011. Hogwild!: A lock-free approach to parallelizing stochastic gradient descent. In Proceedings of the Advances in Neural Information Processing Systems, 693–701. Roux, N. L.; Schmidt, M. W.; and Bach, F. 2012. A stochastic gradient method with an exponential convergence rate for finite training sets. In Proceedings of the Advances in Neural Information Processing Systems, 2672–2680. Shalev-Shwartz, S., and Zhang, T. 2013. Stochastic dual coordinate ascent methods for regularized loss. Journal of Machine Learning Research 14(1):567–599. Xiao, L. 2009. Dual averaging method for regularized stochastic learning and online optimization. In Proceedings of the Advances in Neural Information Processing Systems, 2116–2124. Zhang, R., and Kwok, J. T. 2014. Asynchronous distributed ADMM for consensus optimization. In Proceedings of the 31th International Conference on Machine Learning, 1701– 1709. Zhang, R.; Zheng, S.; and T. Kwok, J. 2015. Fast distributed asynchronous sgd with variance reduction. arXiv:1508.01633. Zhao, S.-Y., and Li, W.-J. 2015. Fast asynchronous parallel stochastic gradient decent. arXiv:1508.05711. Zinkevich, M.; Weimer, M.; Smola, A. J.; and Li, L. 2010. Parallelized stochastic gradient descent. In Proceedings of the Advances in Neural Information Processing Systems, 2595–2603. Zinkevich, M.; Smola, A. J.; and Langford, J. 2009. Slow learners are fast. In Proceedings of the Advances in Neural Information Processing Systems, 2331–2339