正在加载图片...
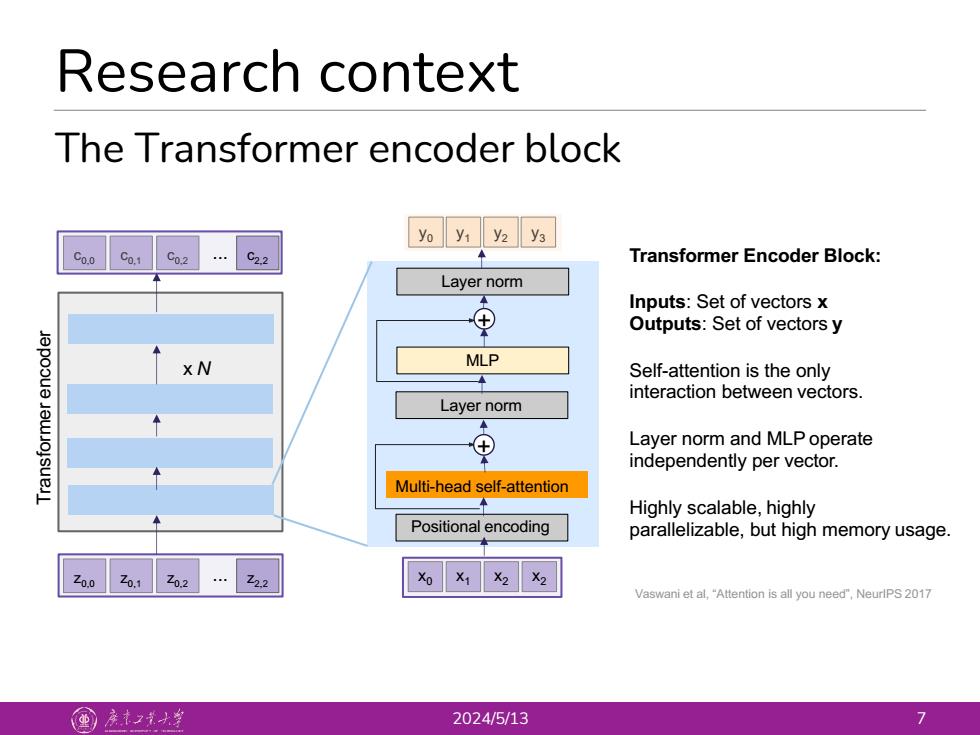
Research context The Transformer encoder block yo y1 y2 y3 C0.0 Co.1 C02…C2.2 Transformer Encoder Block: Layer norm Inputs:Set of vectors x ⊕ Outputs:Set of vectors y X N MLP Self-attention is the only 一 interaction between vectors. Layer norm ⊕ Layer norm and MLP operate independently per vector. Multi-head self-attention 二 Highly scalable,highly Positional encoding parallelizable,but high memory usage. Zo.o Z02…2.2 Vaswani et al,"Attention is all you need",NeurlPS 2017 国产大 2024/5/13 7 Research context 2024/5/13 7 The Transformer encoder block Multi-head self-attention Layer norm Layer norm MLP y0 y1 y2 y3 c0,2 c0,1 c0,0 c2,2 ... Transformer encoder Positional encoding parallelizable, but high memory usage. z ... 0,0 z0,1 z0,2 z2,2 x0 x1 x2 x2 Vaswani et al, “Attention is all you need”, NeurIPS 2017 x N Transformer Encoder Block: Inputs: Set of vectors x Outputs: Set of vectors y Self-attention is the only interaction between vectors. Layer norm and MLP operate independently per vector. Highly scalable, highly + +