正在加载图片...
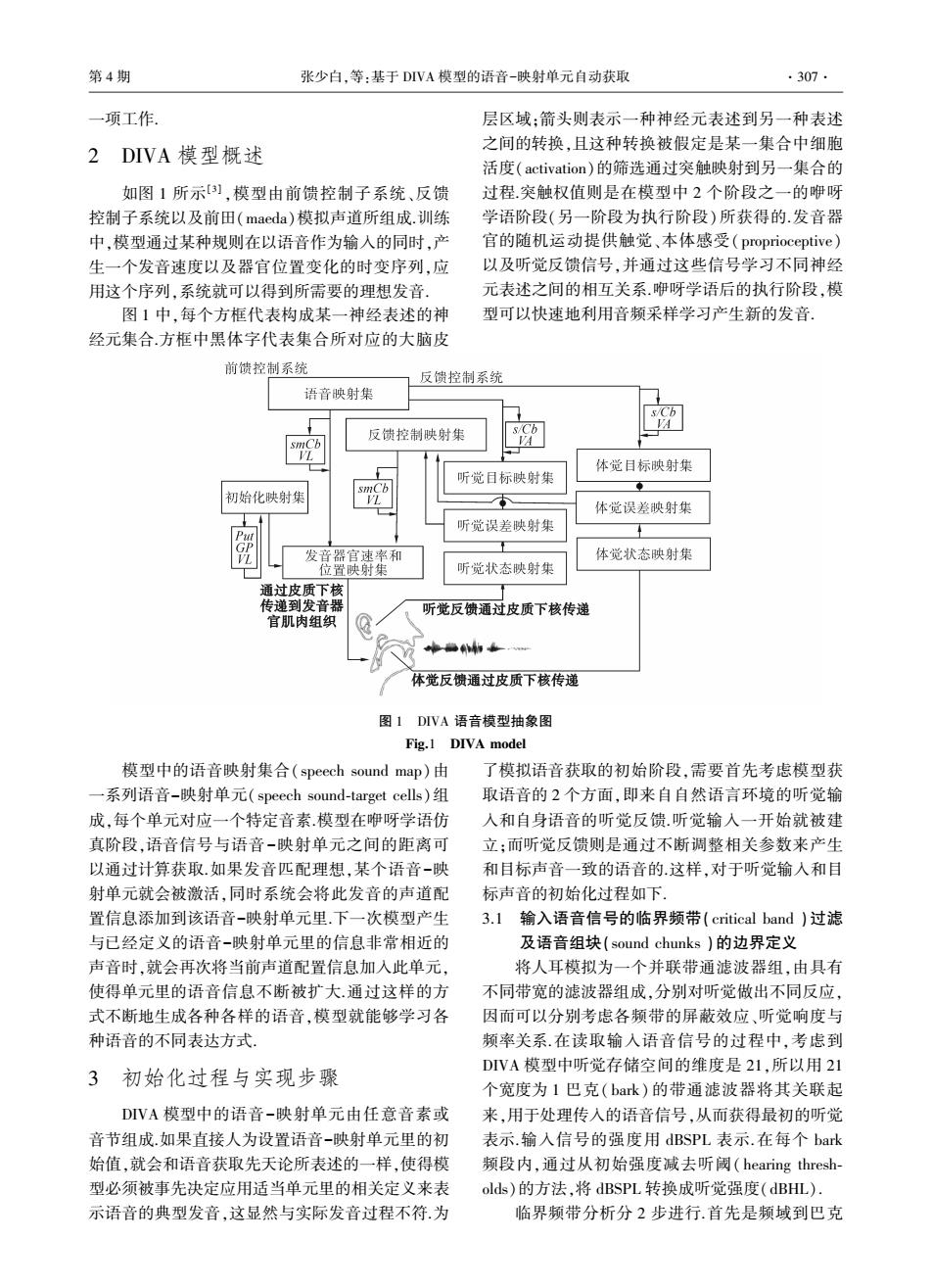
第4期 张少白,等:基于DVA模型的语音-映射单元自动获取 ·307. 一项工作 层区域:箭头则表示一种神经元表述到另一种表述 2DIVA模型概述 之间的转换,且这种转换被假定是某一集合中细胞 活度(activation)的筛选通过突触映射到另一集合的 如图1所示】,模型由前馈控制子系统、反馈 过程突触权值则是在模型中2个阶段之一的咿呀 控制子系统以及前田(maeda)模拟声道所组成.训练 学语阶段(另一阶段为执行阶段)所获得的.发音器 中,模型通过某种规则在以语音作为输入的同时,产 官的随机运动提供触觉、本体感受(proprioceptive) 生一个发音速度以及器官位置变化的时变序列,应 以及听觉反馈信号,并通过这些信号学习不同神经 用这个序列,系统就可以得到所需要的理想发音. 元表述之间的相互关系.咿呀学语后的执行阶段,模 图1中,每个方框代表构成某一神经表述的神 型可以快速地利用音频采样学习产生新的发音. 经元集合方框中黑体字代表集合所对应的大脑皮 前馈控制系统 反馈控制系统 语音映射集 反馈控制映射集 L 体觉目标映射集 听觉日标映射集 初始化映射集 L 体觉误差映射集 听觉误差映射集 发音器官速率和 体觉状态映射集 位置映射集 听觉状态映射集 通过皮质下核 传递到发音器 听觉反馈通过皮质下核传递 官肌肉组织 中●补物4 体觉反馈通过皮质下核传递 图1DVA语音模型抽象图 Fig.1 DIVA model 模型中的语音映射集合(speech sound map)由 了模拟语音获取的初始阶段,需要首先考虑模型获 一系列语音-映射单元(speech sound-target cells)组 取语音的2个方面,即来自自然语言环境的听觉输 成,每个单元对应一个特定音素模型在咿呀学语仿 入和自身语音的听觉反馈.听觉输入一开始就被建 真阶段,语音信号与语音-映射单元之间的距离可 立;而听觉反馈则是通过不断调整相关参数来产生 以通过计算获取.如果发音匹配理想,某个语音-映 和目标声音一致的语音的.这样,对于听觉输入和目 射单元就会被激活,同时系统会将此发音的声道配 标声音的初始化过程如下 置信息添加到该语音-映射单元里.下一次模型产生 3.1输入语音信号的临界频带(critical band)过滤 与已经定义的语音-映射单元里的信息非常相近的 及语音组块(sound chunks)的边界定义 声音时,就会再次将当前声道配置信息加入此单元, 将人耳模拟为一个并联带通滤波器组,由具有 使得单元里的语音信息不断被扩大.通过这样的方 不同带宽的滤波器组成,分别对听觉做出不同反应, 式不断地生成各种各样的语音,模型就能够学习各 因而可以分别考虑各频带的屏蔽效应、听觉响度与 种语音的不同表达方式。 频率关系.在读取输入语音信号的过程中,考虑到 3初始化过程与实现步骤 DVA模型中听觉存储空间的维度是21,所以用21 个宽度为1巴克(bark)的带通滤波器将其关联起 DIVA模型中的语音-映射单元由任意音素或 来,用于处理传入的语音信号,从而获得最初的听觉 音节组成.如果直接人为设置语音-映射单元里的初 表示.输入信号的强度用dBSPL表示.在每个bark 始值,就会和语音获取先天论所表述的一样,使得模 频段内,通过从初始强度减去听阈(hearing thresh- 型必须被事先决定应用适当单元里的相关定义来表 olds)的方法,将dBSPL转换成听觉强度(dBHL). 示语音的典型发音,这显然与实际发音过程不符.为 临界频带分析分2步进行.首先是频域到巴克一项工作. 2 DIVA 模型概述 如图 1 所示[3] ,模型由前馈控制子系统、反馈 控制子系统以及前田(maeda)模拟声道所组成.训练 中,模型通过某种规则在以语音作为输入的同时,产 生一个发音速度以及器官位置变化的时变序列,应 用这个序列,系统就可以得到所需要的理想发音. 图 1 中,每个方框代表构成某一神经表述的神 经元集合.方框中黑体字代表集合所对应的大脑皮 层区域;箭头则表示一种神经元表述到另一种表述 之间的转换,且这种转换被假定是某一集合中细胞 活度(activation)的筛选通过突触映射到另一集合的 过程.突触权值则是在模型中 2 个阶段之一的咿呀 学语阶段(另一阶段为执行阶段)所获得的.发音器 官的随机运动提供触觉、本体感受( proprioceptive) 以及听觉反馈信号,并通过这些信号学习不同神经 元表述之间的相互关系.咿呀学语后的执行阶段,模 型可以快速地利用音频采样学习产生新的发音. 图 1 DIVA 语音模型抽象图 Fig.1 DIVA model 模型中的语音映射集合(speech sound map)由 一系列语音-映射单元(speech sound⁃target cells)组 成,每个单元对应一个特定音素.模型在咿呀学语仿 真阶段,语音信号与语音-映射单元之间的距离可 以通过计算获取.如果发音匹配理想,某个语音-映 射单元就会被激活,同时系统会将此发音的声道配 置信息添加到该语音-映射单元里.下一次模型产生 与已经定义的语音-映射单元里的信息非常相近的 声音时,就会再次将当前声道配置信息加入此单元, 使得单元里的语音信息不断被扩大.通过这样的方 式不断地生成各种各样的语音,模型就能够学习各 种语音的不同表达方式. 3 初始化过程与实现步骤 DIVA 模型中的语音-映射单元由任意音素或 音节组成.如果直接人为设置语音-映射单元里的初 始值,就会和语音获取先天论所表述的一样,使得模 型必须被事先决定应用适当单元里的相关定义来表 示语音的典型发音,这显然与实际发音过程不符.为 了模拟语音获取的初始阶段,需要首先考虑模型获 取语音的 2 个方面,即来自自然语言环境的听觉输 入和自身语音的听觉反馈.听觉输入一开始就被建 立;而听觉反馈则是通过不断调整相关参数来产生 和目标声音一致的语音的.这样,对于听觉输入和目 标声音的初始化过程如下. 3.1 输入语音信号的临界频带(critical band )过滤 及语音组块(sound chunks )的边界定义 将人耳模拟为一个并联带通滤波器组,由具有 不同带宽的滤波器组成,分别对听觉做出不同反应, 因而可以分别考虑各频带的屏蔽效应、听觉响度与 频率关系.在读取输入语音信号的过程中,考虑到 DIVA 模型中听觉存储空间的维度是 21,所以用 21 个宽度为 1 巴克( bark) 的带通滤波器将其关联起 来,用于处理传入的语音信号,从而获得最初的听觉 表示.输入信号的强度用 dBSPL 表示.在每个 bark 频段内,通过从初始强度减去听阈( hearing thresh⁃ olds)的方法,将 dBSPL 转换成听觉强度(dBHL). 临界频带分析分 2 步进行.首先是频域到巴克 第 4 期 张少白,等:基于 DIVA 模型的语音-映射单元自动获取 ·307·