正在加载图片...
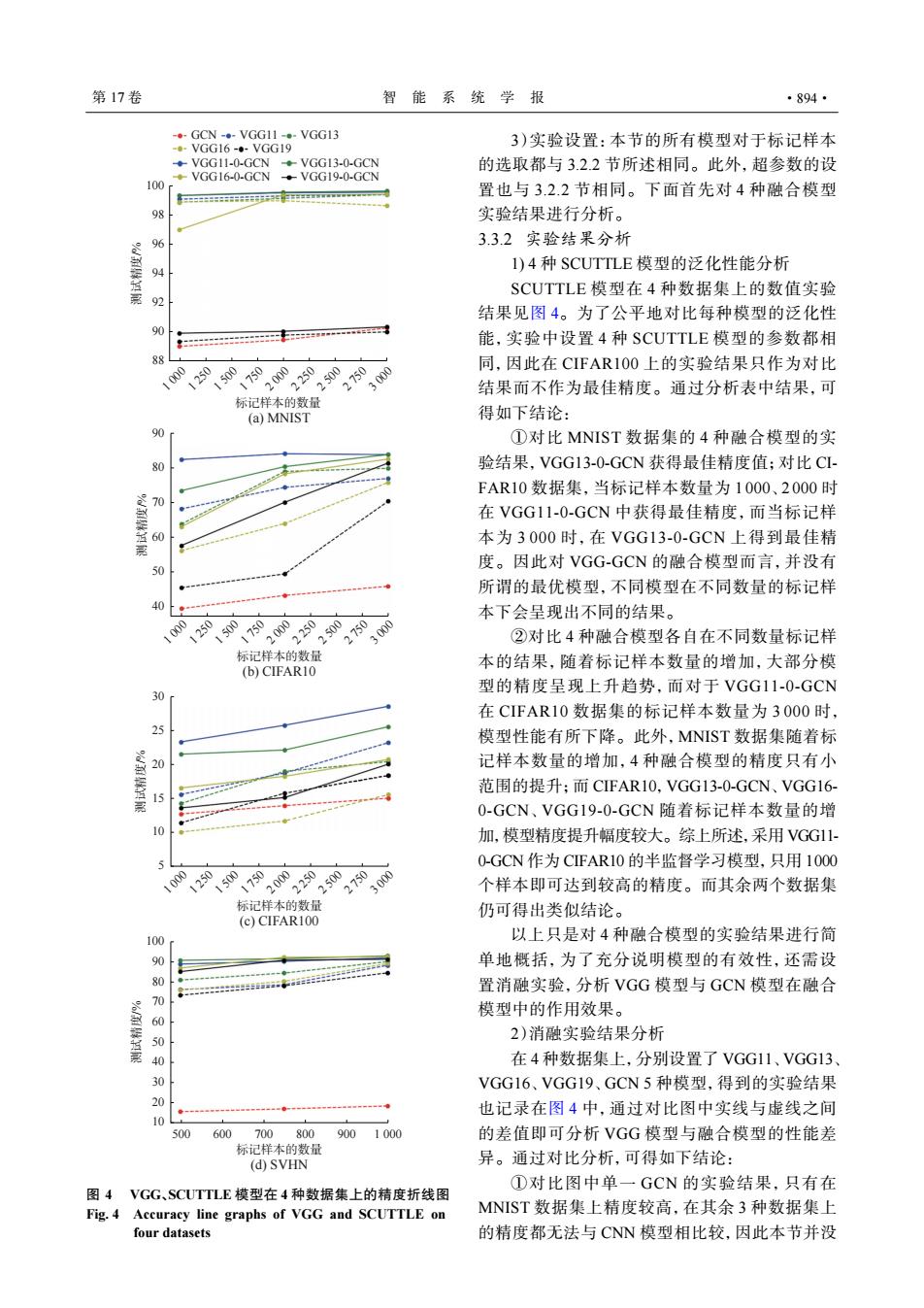
第17卷 智能系统学报 ·894· -。-GCN-。-VGG11--VGG13 -.-VGG16-.-VGG19 3)实验设置:本节的所有模型对于标记样本 ◆VGG11-0-GCN -VGG13-0-GCN 的选取都与3.2.2节所述相同。此外,超参数的设 VGG16-0-GCN -VGG19-0-GCN 100 置也与3.2.2节相同。下面首先对4种融合模型 实验结果进行分析。 96 3.3.2实验结果分析 1)4种SCUTTLE模型的泛化性能分析 SCUTTLE模型在4种数据集上的数值实验 92 结果见图4。为了公平地对比每种模型的泛化性 能,实验中设置4种SCUTTLE模型的参数都相 10 1250 同,因此在CIFAR100上的实验结果只作为对比 结果而不作为最佳精度。通过分析表中结果,可 标记样本的数量 (a)MNIST 得如下结论: 90 ①对比MNIST数据集的4种融合模型的实 80 验结果,VGG13-0-GCN获得最佳精度值;对比CI- FAR10数据集,当标记样本数量为1000、2000时 在VGG11-0-GCN中获得最佳精度,而当标记样 60 本为3000时,在VGG13-0-GCN上得到最佳精 50 度。因此对VGG-GCN的融合模型而言,并没有 所谓的最优模型,不同模型在不同数量的标记样 本下会呈现出不同的结果。 ②对比4种融合模型各自在不同数量标记样 标记样本的数量 本的结果,随着标记样本数量的增加,大部分模 (b)CIFAR10 型的精度呈现上升趋势,而对于VGG11-0-GCN 在CIFAR10数据集的标记样本数量为3000时, 模型性能有所下降。此外,MNST数据集随着标 20 记样本数量的增加,4种融合模型的精度只有小 范围的提升;而CIFAR10,VGG13-0-GCN、VGG16- 0-GCN、VGG19-0-GCN随着标记样本数量的增 加,模型精度提升幅度较大。综上所述,采用VGG11 0-GCN作为CFAR10的半监督学习模型,只用1000 个样本即可达到较高的精度。而其余两个数据集 标记样本的数量 仍可得出类似结论。 (c)CIFAR100 100 以上只是对4种融合模型的实验结果进行简 % 单地概括,为了充分说明模型的有效性,还需设 置消融实验,分析VGG模型与GCN模型在融合 70 模型中的作用效果。 60 50 2)消融实验结果分析 40 在4种数据集上,分别设置了VGG11、VGG13 吃 VGG16、VGG19、GCN5种模型,得到的实验结果 20 也记录在图4中,通过对比图中实线与虚线之间 10 500 600700800 9001000 的差值即可分析VGG模型与融合模型的性能差 标记样本的数量 (d)SVHN 异。通过对比分析,可得如下结论: ①对比图中单一GCN的实验结果,只有在 图4VGG、SCUTTLE模型在4种数据集上的精度折线图 Fig.4 Accuracy line graphs of VGG and SCUTTLE on MNIST数据集上精度较高,在其余3种数据集上 four datasets 的精度都无法与CNN模型相比较,因此本节并没100 98 96 94 92 90 88 1 000 1 250 1 500 1 750 2 000 2 250 2 500 2 750 3 000 测试精度/% 标记样本的数量 90 100 80 70 60 50 20 10 30 40 500 600 700 800 900 1 000 测试精度/% 标记样本的数量 80 90 70 60 50 40 1 000 1 250 1 500 1 750 2 000 2 250 2 500 2 750 3 000 测试精度/% 标记样本的数量 25 30 20 15 5 10 1 000 1 250 1 500 1 750 2 000 2 250 2 500 2 750 3 000 测试精度/% 标记样本的数量 GCN VGG11 VGG13 VGG19 VGG11-0-GCN VGG16 VGG13-0-GCN VGG16-0-GCN VGG19-0-GCN (a) MNIST (b) CIFAR10 (c) CIFAR100 (d) SVHN 图 4 VGG、SCUTTLE 模型在 4 种数据集上的精度折线图 Fig. 4 Accuracy line graphs of VGG and SCUTTLE on four datasets 3)实验设置:本节的所有模型对于标记样本 的选取都与 3.2.2 节所述相同。此外,超参数的设 置也与 3.2.2 节相同。下面首先对 4 种融合模型 实验结果进行分析。 3.3.2 实验结果分析 1) 4 种 SCUTTLE 模型的泛化性能分析 SCUTTLE 模型在 4 种数据集上的数值实验 结果见图 4。为了公平地对比每种模型的泛化性 能,实验中设置 4 种 SCUTTLE 模型的参数都相 同,因此在 CIFAR100 上的实验结果只作为对比 结果而不作为最佳精度。通过分析表中结果,可 得如下结论: ①对比 MNIST 数据集的 4 种融合模型的实 验结果,VGG13-0-GCN 获得最佳精度值;对比 CIFAR10 数据集,当标记样本数量为 1 000、2 000 时 在 VGG11-0-GCN 中获得最佳精度,而当标记样 本为 3 000 时,在 VGG13-0-GCN 上得到最佳精 度。因此对 VGG-GCN 的融合模型而言,并没有 所谓的最优模型,不同模型在不同数量的标记样 本下会呈现出不同的结果。 ②对比 4 种融合模型各自在不同数量标记样 本的结果,随着标记样本数量的增加,大部分模 型的精度呈现上升趋势,而对于 VGG11-0-GCN 在 CIFAR10 数据集的标记样本数量为 3 000 时, 模型性能有所下降。此外,MNIST 数据集随着标 记样本数量的增加,4 种融合模型的精度只有小 范围的提升;而 CIFAR10,VGG13-0-GCN、VGG16- 0-GCN、VGG19-0-GCN 随着标记样本数量的增 加,模型精度提升幅度较大。综上所述,采用 VGG11- 0-GCN 作为 CIFAR10 的半监督学习模型,只用 1000 个样本即可达到较高的精度。而其余两个数据集 仍可得出类似结论。 以上只是对 4 种融合模型的实验结果进行简 单地概括,为了充分说明模型的有效性,还需设 置消融实验,分析 VGG 模型与 GCN 模型在融合 模型中的作用效果。 2)消融实验结果分析 在 4 种数据集上,分别设置了 VGG11、VGG13、 VGG16、VGG19、GCN 5 种模型,得到的实验结果 也记录在图 4 中,通过对比图中实线与虚线之间 的差值即可分析 VGG 模型与融合模型的性能差 异。通过对比分析,可得如下结论: ①对比图中单一 GCN 的实验结果,只有在 MNIST 数据集上精度较高,在其余 3 种数据集上 的精度都无法与 CNN 模型相比较,因此本节并没 第 17 卷 智 能 系 统 学 报 ·894·