正在加载图片...
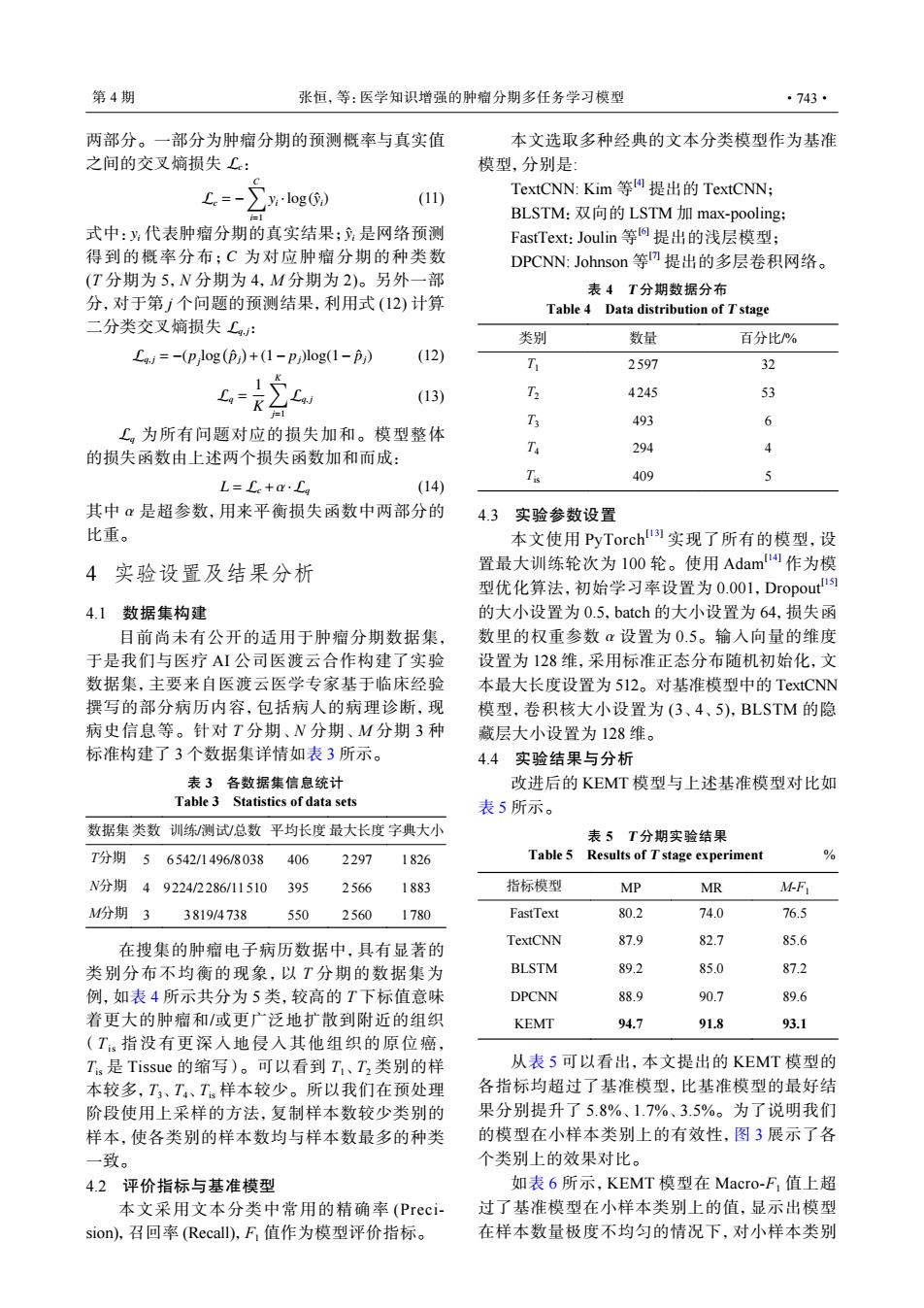
第4期 张恒,等:医学知识增强的肿瘤分期多任务学习模型 ·743· 两部分。一部分为肿瘤分期的预测概率与真实值 本文选取多种经典的文本分类模型作为基准 之间的交叉嫡损失£: 模型,分别是 C=- ∑log) TextCNN:Kim等提出的TextCNN; (11) I BLSTM:双向的LSTM加max-pooling; 式中:代表肿瘤分期的真实结果;是网络预测 FastText:Joulin等提出的浅层模型; 得到的概率分布:C为对应肿瘤分期的种类数 DPCNN:Johnson等提出的多层卷积网络。 (T分期为5,N分期为4,M分期为2)。另外一部 表4T分期数据分布 分,对于第j个问题的预测结果,利用式(12)计算 Table 4 Data distribution of T stage 二分类交叉嫡损失C: 类别 数量 百分比% Laj=-(p log()+(1-pj)log(1-pj) (12) 分 2597 32 Lo= (13) T 4245 3 T 493 6 £,为所有问题对应的损失加和。模型整体 294 的损失函数由上述两个损失函数加和而成: Tis 409 5 L=C+a·C (14) 其中α是超参数,用来平衡损失函数中两部分的 4.3实验参数设置 比重。 本文使用PyTorch)实现了所有的模型,设 4实验设置及结果分析 置最大训练轮次为100轮。使用Adam作为模 型优化算法,初始学习率设置为0.001,Dropout 4.1数据集构建 的大小设置为0.5,batch的大小设置为64,损失函 目前尚未有公开的适用于肿瘤分期数据集, 数里的权重参数α设置为0.5。输入向量的维度 于是我们与医疗AI公司医渡云合作构建了实验 设置为128维,采用标准正态分布随机初始化,文 数据集,主要来自医渡云医学专家基于临床经验 本最大长度设置为512。对基准模型中的TextCNN 撰写的部分病历内容,包括病人的病理诊断,现 模型,卷积核大小设置为(3、4、5),BLSTM的隐 病史信息等。针对T分期、N分期、M分期3种 藏层大小设置为128维。 标准构建了3个数据集详情如表3所示。 4.4实验结果与分析 表3各数据集信息统计 改进后的KEMT模型与上述基准模型对比如 Table 3 Statistics of data sets 表5所示。 数据集类数训练测试总数平均长度最大长度字典大小 表5T分期实验结果 T分期56542/1496/8038 406 2297 1826 Table 5 Results of Tstage experiment % N分期49224/2286/11510 395 2566 1883 指标模型 MP MR M-F M分期3 3819/4738 550 2560 1780 FastText 80.2 74.0 76.5 TextCNN 87.9 在搜集的肿瘤电子病历数据中,具有显著的 82.7 85.6 类别分布不均衡的现象,以T分期的数据集为 BLSTM 89.2 85.0 87.2 例,如表4所示共分为5类,较高的T下标值意味 DPCNN 88.9 90.7 89.6 着更大的肿瘤和/或更广泛地扩散到附近的组织 KEMT 94.7 91.8 93.1 (T指没有更深人地侵入其他组织的原位癌, T.是Tissue的缩写)。可以看到T、T2类别的样 从表5可以看出,本文提出的KEMT模型的 本较多,T、T、T.样本较少。所以我们在预处理 各指标均超过了基准模型,比基准模型的最好结 阶段使用上采样的方法,复制样本数较少类别的 果分别提升了5.8%、1.7%、3.5%。为了说明我们 样本,使各类别的样本数均与样本数最多的种类 的模型在小样本类别上的有效性,图3展示了各 一致。 个类别上的效果对比。 4.2评价指标与基准模型 如表6所示,KEMT模型在Macro-F,值上超 本文采用文本分类中常用的精确率(Preci- 过了基准模型在小样本类别上的值,显示出模型 sion),召回率(Recall)),F,值作为模型评价指标。 在样本数量极度不均匀的情况下,对小样本类别Lc 两部分。一部分为肿瘤分期的预测概率与真实值 之间的交叉熵损失 : Lc = − ∑C i=1 yi ·log(yˆi) (11) yi yˆi C Lq, j 式中: 代表肿瘤分期的真实结果; 是网络预测 得到的概率分布; 为对应肿瘤分期的种类数 (T 分期为 5,N 分期为 4,M 分期为 2)。另外一部 分,对于第 j 个问题的预测结果,利用式 (12) 计算 二分类交叉熵损失 : Lq, j = −(pj log( pˆj ) +(1− pj)log(1− pˆj) (12) Lq = 1 K ∑K j=1 Lq, j (13) Lq 为所有问题对应的损失加和。模型整体 的损失函数由上述两个损失函数加和而成: L = Lc +α· Lq (14) 其中 α 是超参数,用来平衡损失函数中两部分的 比重。 4 实验设置及结果分析 4.1 数据集构建 目前尚未有公开的适用于肿瘤分期数据集, 于是我们与医疗 AI 公司医渡云合作构建了实验 数据集,主要来自医渡云医学专家基于临床经验 撰写的部分病历内容,包括病人的病理诊断,现 病史信息等。针对 T 分期、N 分期、M 分期 3 种 标准构建了 3 个数据集详情如表 3 所示。 表 3 各数据集信息统计 Table 3 Statistics of data sets 数据集 类数 训练/测试/总数 平均长度 最大长度 字典大小 T分期 5 6 542/1 496/8038 406 2 297 1826 N分期 4 9 224/2 286/11510 395 2 566 1883 M分期 3 3 819/4738 550 2 560 1780 在搜集的肿瘤电子病历数据中,具有显著的 类别分布不均衡的现象,以 T 分期的数据集为 例,如表 4 所示共分为 5 类,较高的 T 下标值意味 着更大的肿瘤和/或更广泛地扩散到附近的组织 ( Tis 指没有更深入地侵入其他组织的原位癌, Tis 是 Tissue 的缩写)。可以看到 T1、T2 类别的样 本较多,T3、T4、Tis 样本较少。所以我们在预处理 阶段使用上采样的方法,复制样本数较少类别的 样本,使各类别的样本数均与样本数最多的种类 一致。 4.2 评价指标与基准模型 本文采用文本分类中常用的精确率 (Precision),召回率 (Recall),F1 值作为模型评价指标。 本文选取多种经典的文本分类模型作为基准 模型,分别是: TextCNN: Kim 等 [4] 提出的 TextCNN; BLSTM:双向的 LSTM 加 max-pooling; FastText:Joulin 等 [6] 提出的浅层模型; DPCNN: Johnson 等 [7] 提出的多层卷积网络。 表 4 T 分期数据分布 Table 4 Data distribution of T stage 类别 数量 百分比/% T1 2597 32 T2 4245 53 T3 493 6 T4 294 4 Tis 409 5 4.3 实验参数设置 α 本文使用 PyTorch[13] 实现了所有的模型,设 置最大训练轮次为 100 轮。使用 Adam[14] 作为模 型优化算法,初始学习率设置为 0.001,Dropout[15] 的大小设置为 0.5,batch 的大小设置为 64,损失函 数里的权重参数 设置为 0.5。输入向量的维度 设置为 128 维,采用标准正态分布随机初始化,文 本最大长度设置为 512。对基准模型中的 TextCNN 模型,卷积核大小设置为 (3、4、5),BLSTM 的隐 藏层大小设置为 128 维。 4.4 实验结果与分析 改进后的 KEMT 模型与上述基准模型对比如 表 5 所示。 表 5 T 分期实验结果 Table 5 Results of T stage experiment % 指标模型 MP MR M-F1 FastText 80.2 74.0 76.5 TextCNN 87.9 82.7 85.6 BLSTM 89.2 85.0 87.2 DPCNN 88.9 90.7 89.6 KEMT 94.7 91.8 93.1 从表 5 可以看出,本文提出的 KEMT 模型的 各指标均超过了基准模型,比基准模型的最好结 果分别提升了 5.8%、1.7%、3.5%。为了说明我们 的模型在小样本类别上的有效性,图 3 展示了各 个类别上的效果对比。 如表 6 所示,KEMT 模型在 Macro-F1 值上超 过了基准模型在小样本类别上的值,显示出模型 在样本数量极度不均匀的情况下,对小样本类别 第 4 期 张恒,等:医学知识增强的肿瘤分期多任务学习模型 ·743·