正在加载图片...
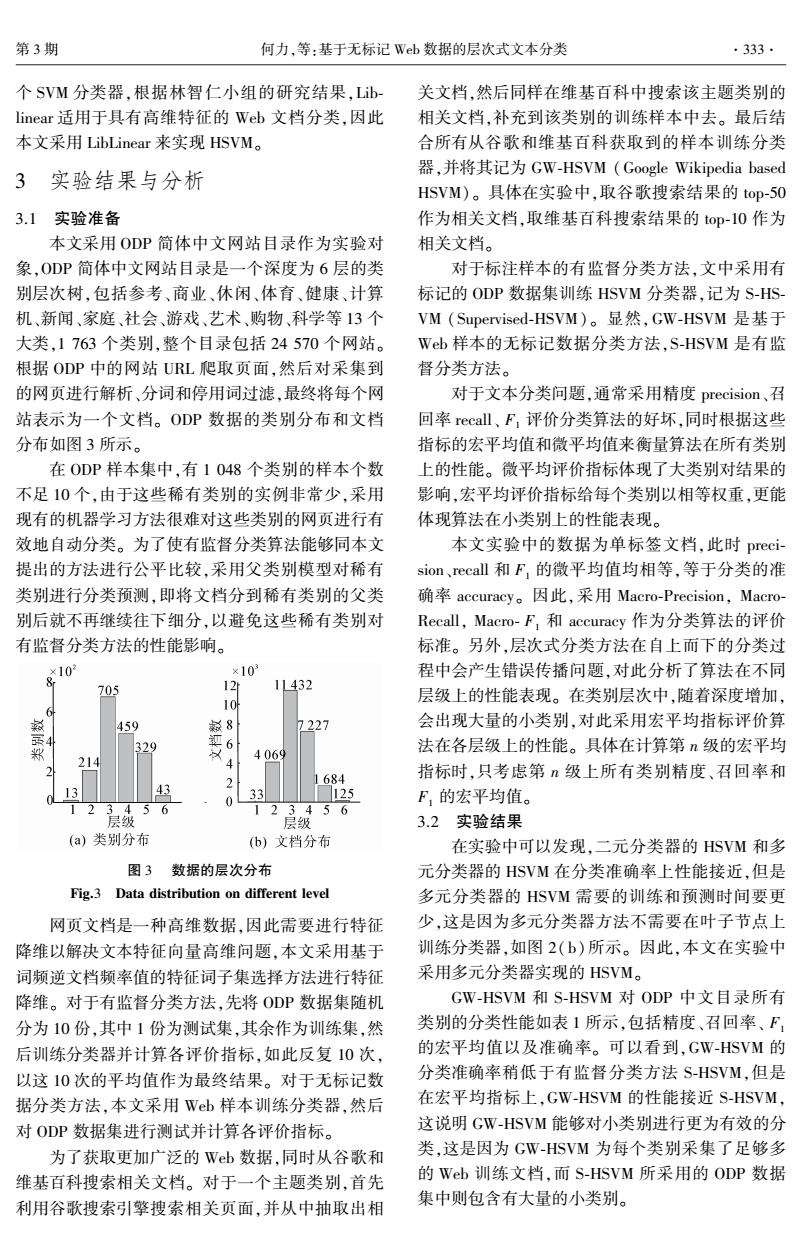
第3期 何力,等:基于无标记Wb数据的层次式文本分类 ·333· 个SVM分类器,根据林智仁小组的研究结果,Lib 关文档,然后同样在维基百科中搜索该主题类别的 linear适用于具有高维特征的Web文档分类,因此 相关文档,补充到该类别的训练样本中去。最后结 本文采用LibLinear来实现HSVM。 合所有从谷歌和维基百科获取到的样本训练分类 3实验结果与分析 器,并将其记为GW-HsVM(Google Wikipedia based HSVM)。具体在实验中,取谷歌搜索结果的top-50 3.1实验准备 作为相关文档,取维基百科搜索结果的top-10作为 本文采用ODP简体中文网站目录作为实验对 相关文档。 象,ODP简体中文网站目录是一个深度为6层的类 对于标注样本的有监督分类方法,文中采用有 别层次树,包括参考、商业、休闲、体育、健康、计算 标记的ODP数据集训练HSVM分类器,记为S-HS- 机、新闻、家庭、社会、游戏、艺术、购物、科学等13个 VM(Supervised-HSVM)。显然,GW-HSVM是基于 大类,1763个类别,整个目录包括24570个网站。 Wb样本的无标记数据分类方法,S-HSVM是有监 根据ODP中的网站URL爬取页面,然后对采集到 督分类方法。 的网页进行解析、分词和停用词过滤,最终将每个网 对于文本分类问题,通常采用精度precision、召 站表示为一个文档。ODP数据的类别分布和文档 回率recall、F,评价分类算法的好坏,同时根据这些 分布如图3所示。 指标的宏平均值和微平均值来衡量算法在所有类别 在ODP样本集中,有1048个类别的样本个数 上的性能。微平均评价指标体现了大类别对结果的 不足10个,由于这些稀有类别的实例非常少,采用 影响,宏平均评价指标给每个类别以相等权重,更能 现有的机器学习方法很难对这些类别的网页进行有 体现算法在小类别上的性能表现。 效地自动分类。为了使有监督分类算法能够同本文 本文实验中的数据为单标签文档,此时preci- 提出的方法进行公平比较,采用父类别模型对稀有 sion、,recall和F,的微平均值均相等,等于分类的准 类别进行分类预测,即将文档分到稀有类别的父类 确率accuracy。因此,采用Macro-Precision,Macro- 别后就不再继续往下细分,以避免这些稀有类别对 Recall,Macro-F,和accuracy作为分类算法的评价 有监督分类方法的性能影响。 标准。另外,层次式分类方法在自上而下的分类过 ×10 ×10 程中会产生错误传播问题,对此分析了算法在不同 705 12 1L432 层级上的性能表现。在类别层次中,随着深度增加, 6 10 459 8 7227 会出现大量的小类别,对此采用宏平均指标评价算 郑 329 6 4069 法在各层级上的性能。具体在计算第n级的宏平均 214 4 2 1684 指标时,只考虑第n级上所有类别精度、召回率和 13 3 0 33 125 F,的宏平均值。 层级6 2 123456 层级 3.2实验结果 (a)类别分布 b)文档分布 在实验中可以发现,二元分类器的HSVM和多 图3数据的层次分布 元分类器的HSVM在分类准确率上性能接近,但是 Fig.3 Data distribution on different level 多元分类器的HSVM需要的训练和预测时间要更 网页文档是一种高维数据,因此需要进行特征 少,这是因为多元分类器方法不需要在叶子节点上 降维以解决文本特征向量高维问题,本文采用基于 训练分类器,如图2(b)所示。因此,本文在实验中 词频逆文档频率值的特征词子集选择方法进行特征 采用多元分类器实现的HSVM。 降维。对于有监督分类方法,先将ODP数据集随机 GW-HSVM和S-HSVM对ODP中文目录所有 分为10份,其中1份为测试集,其余作为训练集,然 类别的分类性能如表1所示,包括精度、召回率、F 后训练分类器并计算各评价指标,如此反复10次, 的宏平均值以及准确率。可以看到,GW-HSVM的 以这10次的平均值作为最终结果。对于无标记数 分类准确率稍低于有监督分类方法S-HSVM,但是 据分类方法,本文采用Wb样本训练分类器,然后 在宏平均指标上,GW-HSVM的性能接近S-HSVM, 对ODP数据集进行测试并计算各评价指标。 这说明GW-HSVM能够对小类别进行更为有效的分 为了获取更加广泛的Web数据,同时从谷歌和 类,这是因为GW-HSVM为每个类别采集了足够多 维基百科搜索相关文档。对于一个主题类别,首先 的Wb训练文档,而S-HSVM所采用的ODP数据 利用谷歌搜索引擎搜索相关页面,并从中抽取出相 集中则包含有大量的小类别。个 SVM 分类器,根据林智仁小组的研究结果,Lib⁃ linear 适用于具有高维特征的 Web 文档分类,因此 本文采用 LibLinear 来实现 HSVM。 3 实验结果与分析 3.1 实验准备 本文采用 ODP 简体中文网站目录作为实验对 象,ODP 简体中文网站目录是一个深度为 6 层的类 别层次树,包括参考、商业、休闲、体育、健康、计算 机、新闻、家庭、社会、游戏、艺术、购物、科学等 13 个 大类,1 763 个类别,整个目录包括 24 570 个网站。 根据 ODP 中的网站 URL 爬取页面,然后对采集到 的网页进行解析、分词和停用词过滤,最终将每个网 站表示为一个文档。 ODP 数据的类别分布和文档 分布如图 3 所示。 在 ODP 样本集中,有 1 048 个类别的样本个数 不足 10 个,由于这些稀有类别的实例非常少,采用 现有的机器学习方法很难对这些类别的网页进行有 效地自动分类。 为了使有监督分类算法能够同本文 提出的方法进行公平比较,采用父类别模型对稀有 类别进行分类预测,即将文档分到稀有类别的父类 别后就不再继续往下细分,以避免这些稀有类别对 有监督分类方法的性能影响。 图 3 数据的层次分布 Fig.3 Data distribution on different level 网页文档是一种高维数据,因此需要进行特征 降维以解决文本特征向量高维问题,本文采用基于 词频逆文档频率值的特征词子集选择方法进行特征 降维。 对于有监督分类方法,先将 ODP 数据集随机 分为 10 份,其中 1 份为测试集,其余作为训练集,然 后训练分类器并计算各评价指标,如此反复 10 次, 以这 10 次的平均值作为最终结果。 对于无标记数 据分类方法,本文采用 Web 样本训练分类器,然后 对 ODP 数据集进行测试并计算各评价指标。 为了获取更加广泛的 Web 数据,同时从谷歌和 维基百科搜索相关文档。 对于一个主题类别,首先 利用谷歌搜索引擎搜索相关页面,并从中抽取出相 关文档,然后同样在维基百科中搜索该主题类别的 相关文档,补充到该类别的训练样本中去。 最后结 合所有从谷歌和维基百科获取到的样本训练分类 器,并将其记为 GW⁃HSVM (Google Wikipedia based HSVM)。 具体在实验中,取谷歌搜索结果的 top⁃50 作为相关文档,取维基百科搜索结果的 top⁃10 作为 相关文档。 对于标注样本的有监督分类方法,文中采用有 标记的 ODP 数据集训练 HSVM 分类器,记为 S⁃HS⁃ VM (Supervised⁃HSVM)。 显然,GW⁃HSVM 是基于 Web 样本的无标记数据分类方法,S⁃HSVM 是有监 督分类方法。 对于文本分类问题,通常采用精度 precision、召 回率 recall、 F1 评价分类算法的好坏,同时根据这些 指标的宏平均值和微平均值来衡量算法在所有类别 上的性能。 微平均评价指标体现了大类别对结果的 影响,宏平均评价指标给每个类别以相等权重,更能 体现算法在小类别上的性能表现。 本文实验中的数据为单标签文档,此时 preci⁃ sion、recall 和 F1 的微平均值均相等,等于分类的准 确率 accuracy。 因此,采用 Macro⁃Precision, Macro⁃ Recall, Macro⁃ F1 和 accuracy 作为分类算法的评价 标准。 另外,层次式分类方法在自上而下的分类过 程中会产生错误传播问题,对此分析了算法在不同 层级上的性能表现。 在类别层次中,随着深度增加, 会出现大量的小类别,对此采用宏平均指标评价算 法在各层级上的性能。 具体在计算第 n 级的宏平均 指标时,只考虑第 n 级上所有类别精度、召回率和 F1 的宏平均值。 3.2 实验结果 在实验中可以发现,二元分类器的 HSVM 和多 元分类器的 HSVM 在分类准确率上性能接近,但是 多元分类器的 HSVM 需要的训练和预测时间要更 少,这是因为多元分类器方法不需要在叶子节点上 训练分类器,如图 2( b)所示。 因此,本文在实验中 采用多元分类器实现的 HSVM。 GW⁃HSVM 和 S⁃HSVM 对 ODP 中文目录所有 类别的分类性能如表 1 所示,包括精度、召回率、 F1 的宏平均值以及准确率。 可以看到,GW⁃HSVM 的 分类准确率稍低于有监督分类方法 S⁃HSVM,但是 在宏平均指标上,GW⁃HSVM 的性能接近 S⁃HSVM, 这说明 GW⁃HSVM 能够对小类别进行更为有效的分 类,这是因为 GW⁃HSVM 为每个类别采集了足够多 的 Web 训练文档,而 S⁃HSVM 所采用的 ODP 数据 集中则包含有大量的小类别。 第 3 期 何力,等:基于无标记 Web 数据的层次式文本分类 ·333·