正在加载图片...
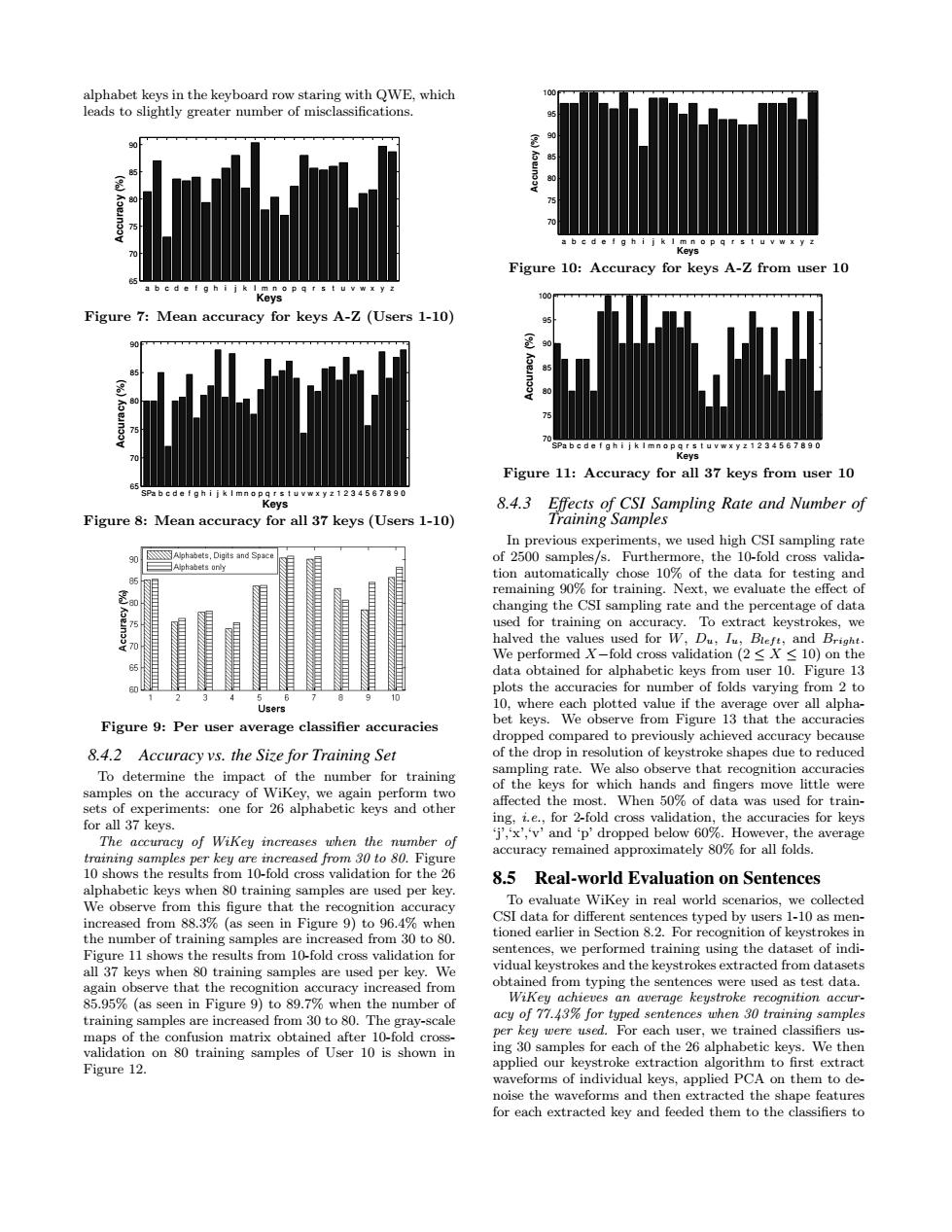
alphabet keys in the keyboard row staring with QWE,which 100 leads to slightly greater number of misclassifications 7 n p g r s t u v w xz Keys Figure 10:Accuracy for keys A-Z from user 10 a b c d e f g h i j k I m n o p q r s t u v w x y z Keys Figure 7:Mean accuracy for keys A-Z(Users 1-10) SPa bc d e Keys Figure 11:Accuracy for all 37 keys from user 10 SPabedefgh i j k I mno pq rs tuvwxy z1234567890 Keys 8.4.3 Effects of CSI Sampling Rate and Number of Figure 8:Mean accuracy for all 37 keys(Users 1-10) Training Samples In previous experiments,we used high CSI sampling rate Alphabets,Digits and Space of 2500 samples/s.Furthermore,the 10-fold cross valida- tion automatically chose 10%of the data for testing and remaining 90%for training.Next,we evaluate the effect of changing the CSI sampling rate and the percentage of data used for training on accuracy.To extract keystrokes,we halved the values used for W,Du,Iu,Bieft,and Bright. We performed X-fold cross validation (2<X<10)on the data obtained for alphabetic keys from user 10.Figure 13 60 plots the accuracies for number of folds varying from 2 to 10 Users 10,where each plotted value if the average over all alpha- Figure 9:Per user average classifier accuracies bet keys.We observe from Figure 13 that the accuracies dropped compared to previously achieved accuracy because 8.4.2 Accuracy vs.the Size for Training Set of the drop in resolution of keystroke shapes due to reduced To determine the impact of the number for training sampling rate.We also observe that recognition accuracies samples on the accuracy of WiKey,we again perform two of the keys for which hands and fingers move little were affected the most.When 50%of data was used for train- sets of experiments:one for 26 alphabetic keys and other for all 37 keys. ing,i.e.,for 2-fold cross validation,the accuracies for keys The accuracy of Wikey increases when the number of j','x','v'and 'p'dropped below 60%.However,the average training samples per key are increased from 30 to 80.Figure accuracy remained approximately 80%for all folds. 10 shows the results from 10-fold cross validation for the 26 8.5 Real-world Evaluation on Sentences alphabetic keys when 80 training samples are used per key. We observe from this figure that the recognition accuracy To evaluate WiKey in real world scenarios,we collected increased from 88.3%(as seen in Figure 9)to 96.4%when CSI data for different sentences typed by users 1-10 as men- the number of training samples are increased from 30 to 80 tioned earlier in Section 8.2.For recognition of keystrokes in Figure 11 shows the results from 10-fold cross validation for sentences,we performed training using the dataset of indi- all 37 keys when 80 training samples are used per key.We vidual keystrokes and the keystrokes extracted from datasets again observe that the recognition accuracy increased from obtained from typing the sentences were used as test data. 85.95%(as seen in Figure 9)to 89.7%when the number of Wikey achieves an average keystroke recognition accur- training samples are increased from 30 to 80.The gray-scale acy of 77.43%for typed sentences when 30 training samples maps of the confusion matrix obtained after 10-fold cross- per key were used.For each user,we trained classifiers us- validation on 80 training samples of User 10 is shown in ing 30 samples for each of the 26 alphabetic keys.We then Figure 12. applied our keystroke extraction algorithm to first extract waveforms of individual keys,applied PCA on them to de- noise the waveforms and then extracted the shape features for each extracted key and feeded them to the classifiers toalphabet keys in the keyboard row staring with QWE, which leads to slightly greater number of misclassifications. a b c d e f g h i j k l m n o p q r s t u v w x y z 65 70 75 80 85 90 Keys Accuracy (%) Figure 7: Mean accuracy for keys A-Z (Users 1-10) SPa b c d e f g h i j k l m n o p q r s t u v w x y z 1 2 3 4 5 6 7 8 9 0 65 70 75 80 85 90 Keys Accuracy (%) Figure 8: Mean accuracy for all 37 keys (Users 1-10) Figure 9: Per user average classifier accuracies 8.4.2 Accuracy vs. the Size for Training Set To determine the impact of the number for training samples on the accuracy of WiKey, we again perform two sets of experiments: one for 26 alphabetic keys and other for all 37 keys. The accuracy of WiKey increases when the number of training samples per key are increased from 30 to 80. Figure 10 shows the results from 10-fold cross validation for the 26 alphabetic keys when 80 training samples are used per key. We observe from this figure that the recognition accuracy increased from 88.3% (as seen in Figure 9) to 96.4% when the number of training samples are increased from 30 to 80. Figure 11 shows the results from 10-fold cross validation for all 37 keys when 80 training samples are used per key. We again observe that the recognition accuracy increased from 85.95% (as seen in Figure 9) to 89.7% when the number of training samples are increased from 30 to 80. The gray-scale maps of the confusion matrix obtained after 10-fold crossvalidation on 80 training samples of User 10 is shown in Figure 12. a b c d e f g h i j k l m n o p q r s t u v w x y z 70 75 80 85 90 95 100 Keys Accuracy (%) Figure 10: Accuracy for keys A-Z from user 10 SPa b c d e f g h i j k l m n o p q r s t u v w x y z 1 2 3 4 5 6 7 8 9 0 70 75 80 85 90 95 100 Keys Accuracy (%) Figure 11: Accuracy for all 37 keys from user 10 8.4.3 Effects of CSI Sampling Rate and Number of Training Samples In previous experiments, we used high CSI sampling rate of 2500 samples/s. Furthermore, the 10-fold cross validation automatically chose 10% of the data for testing and remaining 90% for training. Next, we evaluate the effect of changing the CSI sampling rate and the percentage of data used for training on accuracy. To extract keystrokes, we halved the values used for W, Du, Iu, Blef t, and Bright. We performed X−fold cross validation (2 ≤ X ≤ 10) on the data obtained for alphabetic keys from user 10. Figure 13 plots the accuracies for number of folds varying from 2 to 10, where each plotted value if the average over all alphabet keys. We observe from Figure 13 that the accuracies dropped compared to previously achieved accuracy because of the drop in resolution of keystroke shapes due to reduced sampling rate. We also observe that recognition accuracies of the keys for which hands and fingers move little were affected the most. When 50% of data was used for training, i.e., for 2-fold cross validation, the accuracies for keys ‘j’,‘x’,‘v’ and ‘p’ dropped below 60%. However, the average accuracy remained approximately 80% for all folds. 8.5 Real-world Evaluation on Sentences To evaluate WiKey in real world scenarios, we collected CSI data for different sentences typed by users 1-10 as mentioned earlier in Section 8.2. For recognition of keystrokes in sentences, we performed training using the dataset of individual keystrokes and the keystrokes extracted from datasets obtained from typing the sentences were used as test data. WiKey achieves an average keystroke recognition accuracy of 77.43% for typed sentences when 30 training samples per key were used. For each user, we trained classifiers using 30 samples for each of the 26 alphabetic keys. We then applied our keystroke extraction algorithm to first extract waveforms of individual keys, applied PCA on them to denoise the waveforms and then extracted the shape features for each extracted key and feeded them to the classifiers to