正在加载图片...
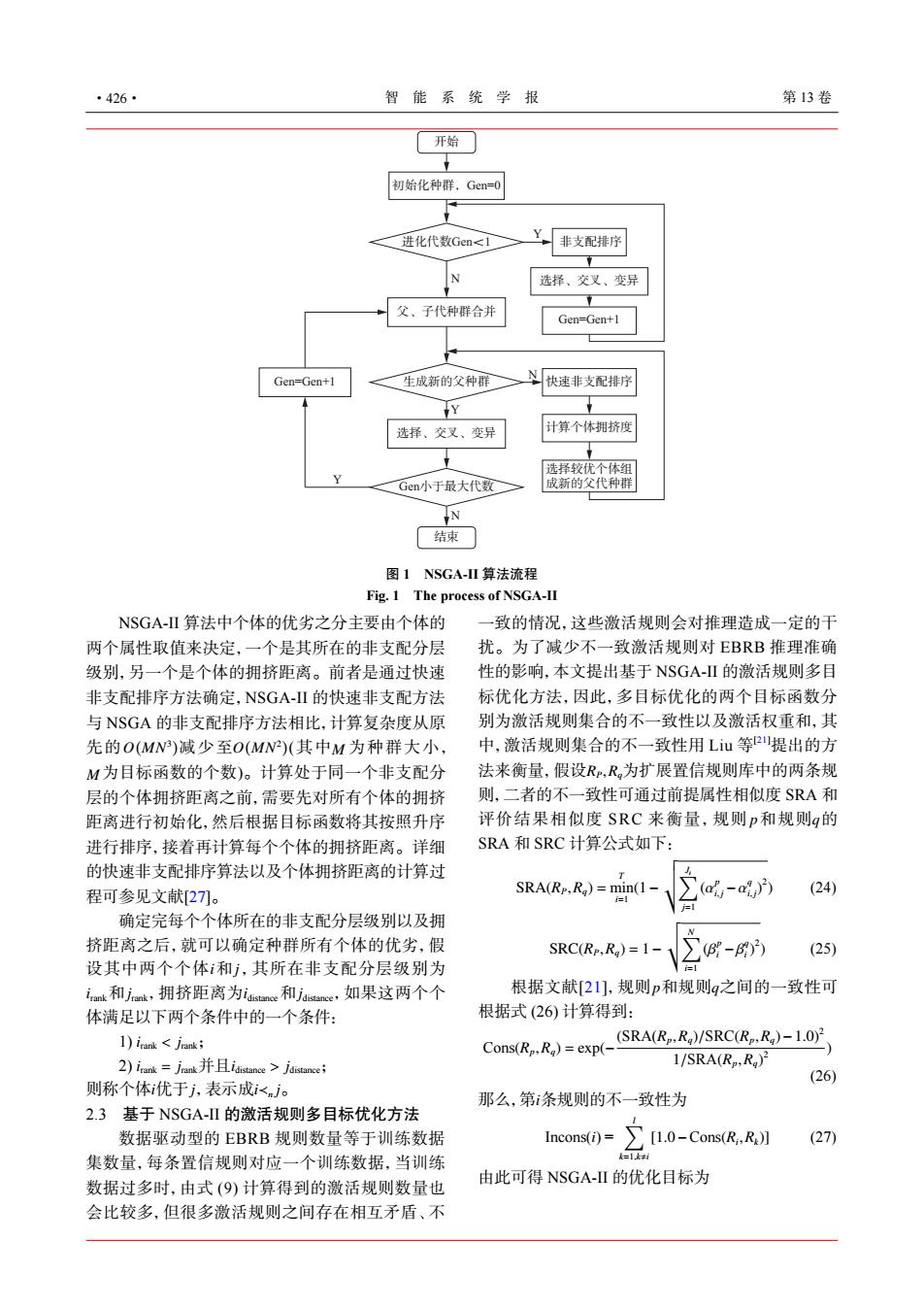
·426· 智能系统学报 第13卷 开始 初始化种群,Gen=0 进化代数Gen<1 Y非支配排序 N 选择、交叉、变异 父、子代种群合并 Gen=Gen+1 Gen=Gen+1 生成新的父种群 N 快速非支配排序 P 选择、交叉、变异 计算个体拥挤度 选择较优个体组 Gen小于最大代数 成新的父代种群 N 结束 图1NSGA-I算法流程 Fig.1 The process of NSGA-II NSGA-Ⅱ算法中个体的优劣之分主要由个体的 一致的情况,这些激活规则会对推理造成一定的干 两个属性取值来决定,一个是其所在的非支配分层 扰。为了减少不一致激活规则对EBRB推理准确 级别,另一个是个体的拥挤距离。前者是通过快速 性的影响,本文提出基于NSGA-Ⅱ的激活规则多目 非支配排序方法确定,NSGA-Ⅱ的快速非支配方法 标优化方法,因此,多目标优化的两个目标函数分 与NSGA的非支配排序方法相比,计算复杂度从原 别为激活规则集合的不一致性以及激活权重和,其 先的O(MN)减少至O(MN2)(其中M为种群大小, 中,激活规则集合的不一致性用Lu等2提出的方 M为目标函数的个数)。计算处于同一个非支配分 法来衡量,假设R,R为扩展置信规则库中的两条规 层的个体拥挤距离之前,需要先对所有个体的拥挤 则,二者的不一致性可通过前提属性相似度SRA和 距离进行初始化,然后根据目标函数将其按照升序 评价结果相似度SRC来衡量,规则p和规则q的 进行排序,接着再计算每个个体的拥挤距离。详细 SRA和SRC计算公式如下: 的快速非支配排序算法以及个体拥挤距离的计算过 程可参见文献27。 SRA(Rp,Rg)=min(1 (a-a)) (24) =1 确定完每个个体所在的非支配分层级别以及拥 挤距离之后,就可以确定种群所有个体的优劣,假 SRC(Rp.Ra)=1- (25) 设其中两个个体和j,其所在非支配分层级别为 irank和jrnk,拥挤距离为st和jisne,如果这两个个 根据文献[21],规则p和规则g之间的一致性可 体满足以下两个条件中的一个条件: 根据式(26)计算得到: 1)irank <jranki Cons(Rp.Ra)=exp(- (SRA(Rp:Ra)/SRC(Rp:Rg)-1.0)2 2)irank=jrank并且distance>jdistance 1/SRA(Rp,R)2 (26) 则称个体优于j,表示成i<nj。 那么,第条规则的不一致性为 2.3基于NSGA-Ⅱ的激活规则多目标优化方法 数据驱动型的EBRB规则数量等于训练数据 Incons(i)= 10-CosR,R】 (27) 集数量,每条置信规则对应一个训练数据,当训练 k=1k村 数据过多时,由式(9)计算得到的激活规则数量也 由此可得NSGA-Ⅱ的优化目标为 会比较多,但很多激活规则之间存在相互矛盾、不O ( MN3 ) O ( MN2 ) M M NSGA-II 算法中个体的优劣之分主要由个体的 两个属性取值来决定,一个是其所在的非支配分层 级别,另一个是个体的拥挤距离。前者是通过快速 非支配排序方法确定,NSGA-II 的快速非支配方法 与 NSGA 的非支配排序方法相比,计算复杂度从原 先的 减少至 (其中 为种群大小, 为目标函数的个数)。计算处于同一个非支配分 层的个体拥挤距离之前,需要先对所有个体的拥挤 距离进行初始化,然后根据目标函数将其按照升序 进行排序,接着再计算每个个体的拥挤距离。详细 的快速非支配排序算法以及个体拥挤距离的计算过 程可参见文献[27]。 i j irank jrank idistance jdistance 确定完每个个体所在的非支配分层级别以及拥 挤距离之后,就可以确定种群所有个体的优劣,假 设其中两个个体 和 ,其所在非支配分层级别为 和 ,拥挤距离为 和 ,如果这两个个 体满足以下两个条件中的一个条件: irank < j 1) rank; irank = j 2) rank并且 idistance > jdistance; 则称个体 i 优于 j ,表示成 i≺n j。 2.3 基于 NSGA-II 的激活规则多目标优化方法 数据驱动型的 EBRB 规则数量等于训练数据 集数量,每条置信规则对应一个训练数据,当训练 数据过多时,由式 (9) 计算得到的激活规则数量也 会比较多,但很多激活规则之间存在相互矛盾、不 RP,Rq p q 一致的情况,这些激活规则会对推理造成一定的干 扰。为了减少不一致激活规则对 EBRB 推理准确 性的影响,本文提出基于 NSGA-II 的激活规则多目 标优化方法,因此,多目标优化的两个目标函数分 别为激活规则集合的不一致性以及激活权重和,其 中,激活规则集合的不一致性用 Liu 等 [21]提出的方 法来衡量,假设 为扩展置信规则库中的两条规 则,二者的不一致性可通过前提属性相似度 SRA 和 评价结果相似度 SRC 来衡量,规则 和规则 的 SRA 和 SRC 计算公式如下: SRA(RP,Rq) = T min i=1 (1− vut∑Ji j=1 (α p i, j −α q i, j ) 2 ) (24) SRC(RP,Rq) = 1− vt∑N i=1 (β p i −β q i ) 2 ) (25) 根据文献[21],规则 p 和规则 q 之间的一致性可 根据式 (26) 计算得到: Cons(Rp,Rq) = exp(− (SRA(Rp ,Rq)/SRC(Rp ,Rq)−1.0)2 1/SRA(Rp,Rq) 2 ) (26) 那么,第 i 条规则的不一致性为 Incons(i) = ∑l k=1,k,i [1.0−Cons(Ri ,Rk)] (27) 由此可得 NSGA-II 的优化目标为 ᐬ ݉ࡂ㓐喏Gen=0 䔇ࡂЏGen喟1 Y 䲊ᩛ䙹ᢾᎻ 䔵᠕ȟϐࣵȟऄᐮ Gen=Gen+1 ❢ȟၼЏ㓐ऴᎢ ᔗ䕋䲊ᩛ䙹ᢾᎻ 䃍ッ͖ѿ᠑ᡐᏒ 䔵᠕䒯ф͖ѿ㏰ ⮰❢Џ㓐 ㏿ N Genᄻκᰬ๓Џ Y 䔵᠕ȟϐࣵȟऄᐮ Gen=Gen+1 ⩋⮰❢㓐 N N Y 图 1 NSGA-II 算法流程 Fig. 1 The process of NSGA-II ·426· 智 能 系 统 学 报 第 13 卷