正在加载图片...
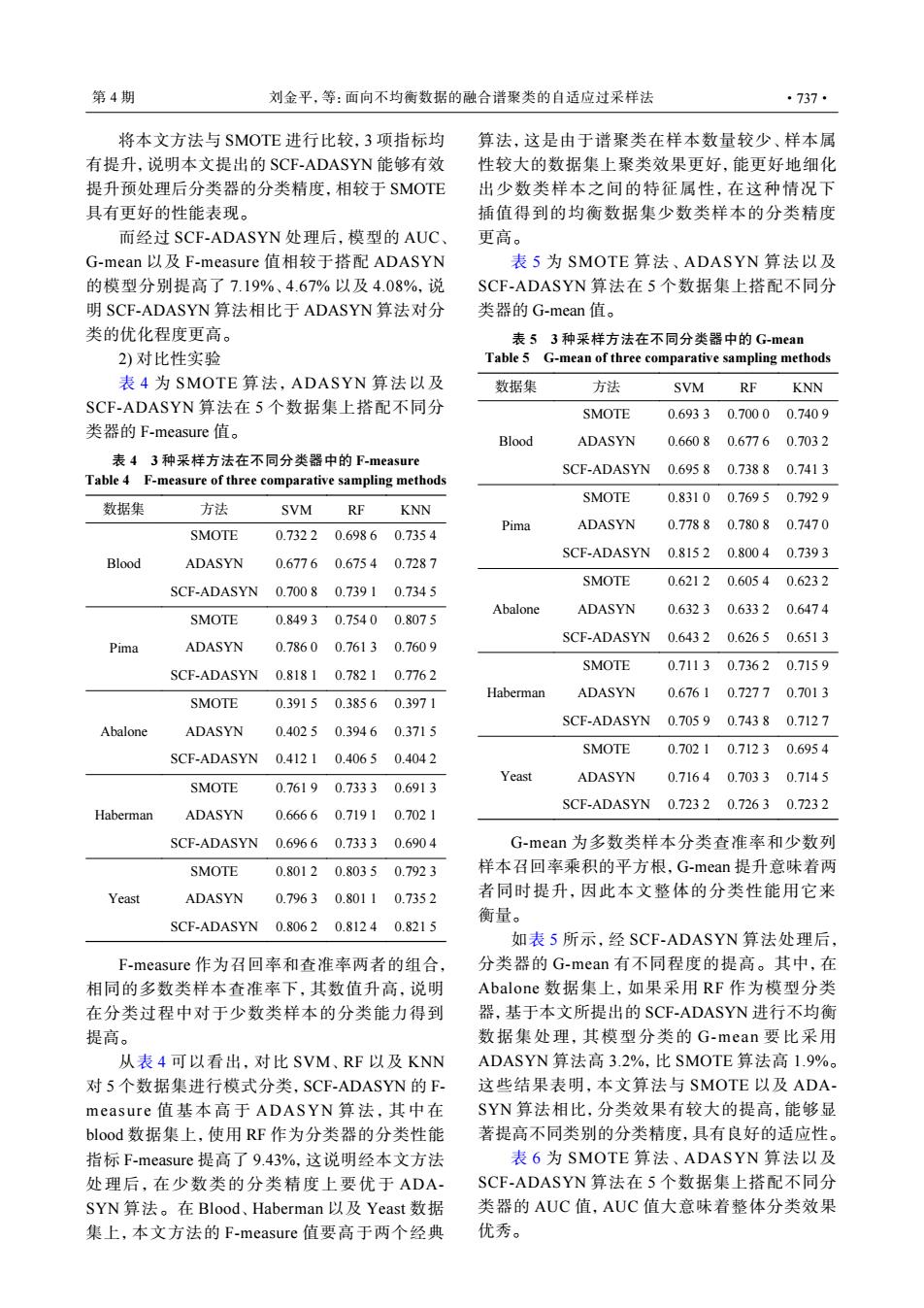
第4期 刘金平,等:面向不均衡数据的融合谱聚类的自适应过采样法 ·737· 将本文方法与SMOTE进行比较,3项指标均 算法,这是由于谱聚类在样本数量较少、样本属 有提升,说明本文提出的SCF-ADASYN能够有效 性较大的数据集上聚类效果更好,能更好地细化 提升预处理后分类器的分类精度,相较于SMOTE 出少数类样本之间的特征属性,在这种情况下 具有更好的性能表现。 插值得到的均衡数据集少数类样本的分类精度 而经过SCF-ADASYN处理后,模型的AUC、 更高。 G-mean以及F-measure值相较于搭配ADASYN 表5为SMOTE算法、ADASYN算法以及 的模型分别提高了7.19%、4.67%以及4.08%,说 SCF-ADASYN算法在5个数据集上搭配不同分 明SCF-ADASYN算法相比于ADASYN算法对分 类器的G-mean值。 类的优化程度更高。 表53种采样方法在不同分类器中的G-mean 2)对比性实验 Table 5 G-mean of three comparative sampling methods 表4为SMOTE算法,ADASYN算法以及 数据集 方法 SVM RF KNN SCF-ADASYN算法在5个数据集上搭配不同分 SMOTE 0.69330.7000 0.7409 类器的F-measure值。 Blood ADASYN 0.66080.6776 0.7032 表43种采样方法在不同分类器中的F-measure SCF-ADASYN 0.695 8 0.73880.7413 Table 4 F-measure of three comparative sampling methods SMOTE 0.83100.76950.7929 数据集 方法 SVM RF KNN Pima ADASYN 0.77880.78080.7470 SMOTE 0.7322 0.69860.7354 SCF-ADASYN 0.8152 0.8004 0.7393 Blood ADASYN 0.67760.67540.7287 SMOTE 0.62120.6054 0.6232 SCF-ADASYN 0.700 8 0.73910.7345 Abalone ADASYN 0.63230.6332 0.6474 SMOTE 0.8493 0.7540 0.8075 SCF-ADASYN 0.643 2 0.62650.6513 Pima ADASYN 0.7860 0.7613 0.7609 SMOTE 0.71130.73620.7159 SCF-ADASYN 0.818 1 0.78210.7762 Haberman ADASYN 0.67610.72770.7013 SMOTE 0.39150.38560.3971 SCF-ADASYN0.70590.74380.7127 Abalone ADASYN 0.40250.39460.3715 SMOTE 0.70210.7123 0.6954 SCF-ADASYN0.41210.40650.4042 Yeast ADASYN 0.71640.7033 0.7145 SMOTE 0.76190.7333 0.6913 SCF-ADASYN0.72320.72630.7232 Haberman ADASYN 0.6666 0.7191 0.7021 SCF-ADASYN 0.6966 0.7333 0.6904 G-mean为多数类样本分类查准率和少数列 SMOTE 0.8012 0.80350.7923 样本召回率乘积的平方根,G-mean提升意味着两 Yeast ADASYN 0.7963 0.80110.7352 者同时提升,因此本文整体的分类性能用它来 衡量。 SCF-ADASYN0.80620.81240.8215 如表5所示,经SCF-ADASYN算法处理后, F-measure作为召回率和查准率两者的组合, 分类器的G-mean有不同程度的提高。其中,在 相同的多数类样本查准率下,其数值升高,说明 Abalone数据集上,如果采用RF作为模型分类 在分类过程中对于少数类样本的分类能力得到 器,基于本文所提出的SCF-ADASYN进行不均衡 提高。 数据集处理,其模型分类的G-mean要比采用 从表4可以看出,对比SVM、RF以及KNN ADASYN算法高3.2%,比SMOTE算法高1.9%。 对5个数据集进行模式分类,SCF-ADASYN的F- 这些结果表明,本文算法与SMOTE以及ADA- measure值基本高于ADASYN算法,其中在 SYN算法相比,分类效果有较大的提高,能够显 blood数据集上,使用RF作为分类器的分类性能 著提高不同类别的分类精度,具有良好的适应性。 指标F-measure提高了9.43%,这说明经本文方法 表6为SMOTE算法、ADASYN算法以及 处理后,在少数类的分类精度上要优于ADA- SCF-ADASYN算法在5个数据集上搭配不同分 SYN算法。在Blood、Haberman以及Yeast数据 类器的AUC值,AUC值大意味着整体分类效果 集上,本文方法的F-measure值要高于两个经典 优秀。将本文方法与 SMOTE 进行比较,3 项指标均 有提升,说明本文提出的 SCF-ADASYN 能够有效 提升预处理后分类器的分类精度,相较于 SMOTE 具有更好的性能表现。 而经过 SCF-ADASYN 处理后,模型的 AUC、 G-mean 以及 F-measure 值相较于搭配 ADASYN 的模型分别提高了 7.19%、4.67% 以及 4.08%,说 明 SCF-ADASYN 算法相比于 ADASYN 算法对分 类的优化程度更高。 2) 对比性实验 表 4 为 SMOTE 算法,ADASYN 算法以及 SCF-ADASYN 算法在 5 个数据集上搭配不同分 类器的 F-measure 值。 表 4 3 种采样方法在不同分类器中的 F-measure Table 4 F-measure of three comparative sampling methods 数据集 方法 SVM RF KNN Blood SMOTE 0.732 2 0.698 6 0.735 4 ADASYN 0.677 6 0.675 4 0.728 7 SCF-ADASYN 0.700 8 0.739 1 0.734 5 Pima SMOTE 0.849 3 0.754 0 0.807 5 ADASYN 0.786 0 0.761 3 0.760 9 SCF-ADASYN 0.818 1 0.782 1 0.776 2 Abalone SMOTE 0.391 5 0.385 6 0.397 1 ADASYN 0.402 5 0.394 6 0.371 5 SCF-ADASYN 0.412 1 0.406 5 0.404 2 Haberman SMOTE 0.761 9 0.733 3 0.691 3 ADASYN 0.666 6 0.719 1 0.702 1 SCF-ADASYN 0.696 6 0.733 3 0.690 4 Yeast SMOTE 0.801 2 0.803 5 0.792 3 ADASYN 0.796 3 0.801 1 0.735 2 SCF-ADASYN 0.806 2 0.812 4 0.821 5 F-measure 作为召回率和查准率两者的组合, 相同的多数类样本查准率下,其数值升高,说明 在分类过程中对于少数类样本的分类能力得到 提高。 从表 4 可以看出,对比 SVM、RF 以及 KNN 对 5 个数据集进行模式分类,SCF-ADASYN 的 Fmeasur e 值基本高 于 ADASYN 算法,其中 在 blood 数据集上,使用 RF 作为分类器的分类性能 指标 F-measure 提高了 9.43%,这说明经本文方法 处理后,在少数类的分类精度上要优于 ADASYN 算法。在 Blood、Haberman 以及 Yeast 数据 集上,本文方法的 F-measure 值要高于两个经典 算法,这是由于谱聚类在样本数量较少、样本属 性较大的数据集上聚类效果更好,能更好地细化 出少数类样本之间的特征属性,在这种情况下 插值得到的均衡数据集少数类样本的分类精度 更高。 表 5 为 SMOTE 算法、ADASYN 算法以及 SCF-ADASYN 算法在 5 个数据集上搭配不同分 类器的 G-mean 值。 表 5 3 种采样方法在不同分类器中的 G-mean Table 5 G-mean of three comparative sampling methods 数据集 方法 SVM RF KNN Blood SMOTE 0.693 3 0.700 0 0.740 9 ADASYN 0.660 8 0.677 6 0.703 2 SCF-ADASYN 0.695 8 0.738 8 0.741 3 Pima SMOTE 0.831 0 0.769 5 0.792 9 ADASYN 0.778 8 0.780 8 0.747 0 SCF-ADASYN 0.815 2 0.800 4 0.739 3 Abalone SMOTE 0.621 2 0.605 4 0.623 2 ADASYN 0.632 3 0.633 2 0.647 4 SCF-ADASYN 0.643 2 0.626 5 0.651 3 Haberman SMOTE 0.711 3 0.736 2 0.715 9 ADASYN 0.676 1 0.727 7 0.701 3 SCF-ADASYN 0.705 9 0.743 8 0.712 7 Yeast SMOTE 0.702 1 0.712 3 0.695 4 ADASYN 0.716 4 0.703 3 0.714 5 SCF-ADASYN 0.723 2 0.726 3 0.723 2 G-mean 为多数类样本分类查准率和少数列 样本召回率乘积的平方根,G-mean 提升意味着两 者同时提升,因此本文整体的分类性能用它来 衡量。 如表 5 所示,经 SCF-ADASYN 算法处理后, 分类器的 G-mean 有不同程度的提高。其中,在 Abalone 数据集上,如果采用 RF 作为模型分类 器,基于本文所提出的 SCF-ADASYN 进行不均衡 数据集处理,其模型分类的 G-mean 要比采用 ADASYN 算法高 3.2%,比 SMOTE 算法高 1.9%。 这些结果表明,本文算法与 SMOTE 以及 ADASYN 算法相比,分类效果有较大的提高,能够显 著提高不同类别的分类精度,具有良好的适应性。 表 6 为 SMOTE 算法、ADASYN 算法以及 SCF-ADASYN 算法在 5 个数据集上搭配不同分 类器的 AUC 值,AUC 值大意味着整体分类效果 优秀。 第 4 期 刘金平,等:面向不均衡数据的融合谱聚类的自适应过采样法 ·737·