正在加载图片...
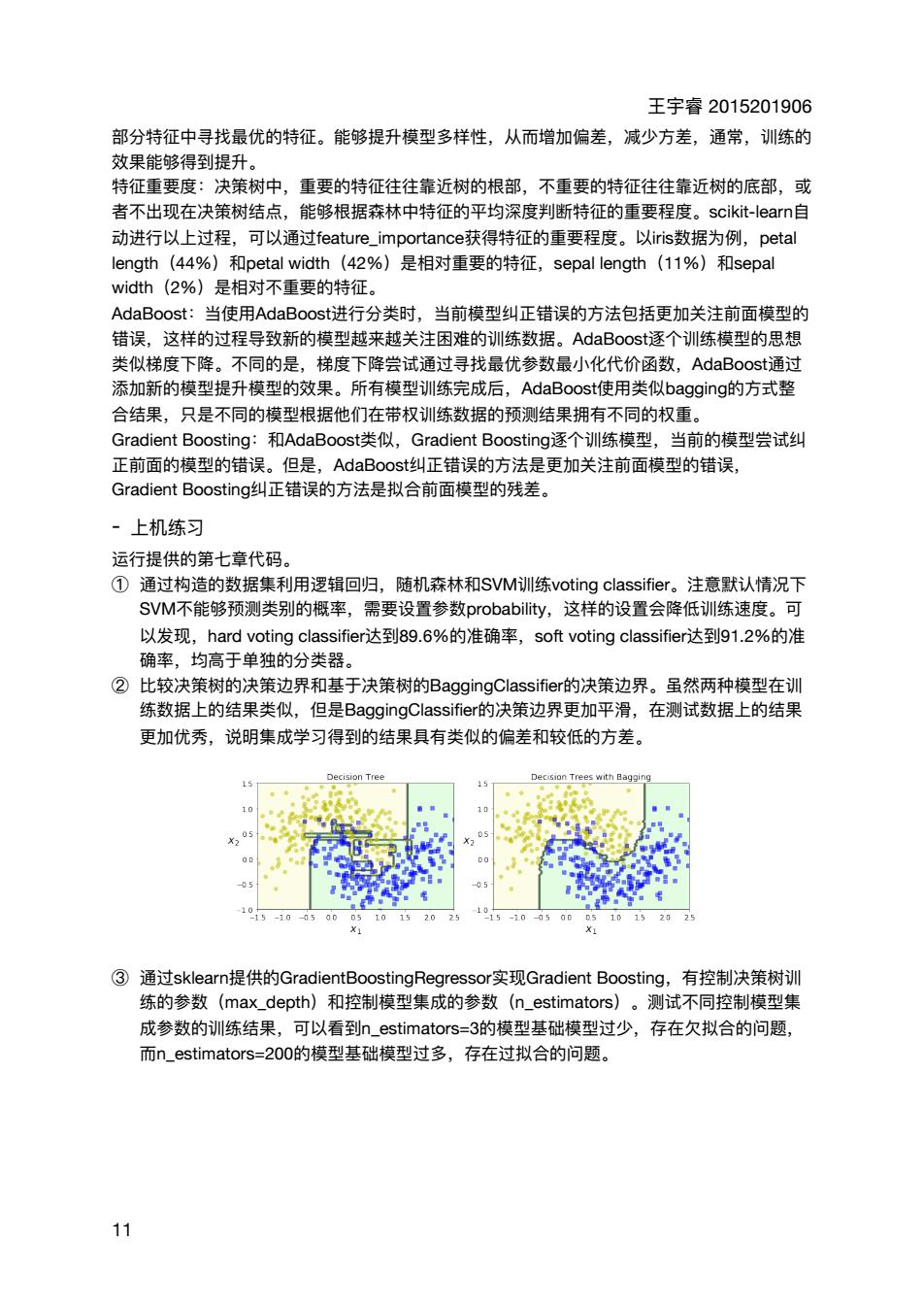
王字春2015201906 部分特征中寻找最优的特征。能够提升模型多样性,从而增加偏差,减少方差,通常,训练的 敏里能得到提升 特征重要度:决策树中,重要的特征往往靠近树的根部,不重要的特征往往靠近树的底部,或 者不出现在决策树结点,能够根据森林中特征的平均深度判断特征的重要程度。scikit---learn自 动进行以上过程,可以通过feature_.importance获得特征的重要程度。以iris数据为例,petal length (44%) tal widt (42%)是相对重要的特征,sepal length(11%)和sepa width(2%)是相对不重要的特征。 AdaBoost:当使用AdaBoosti进行分类时,当前模型纠正错误的方法包括更加关注前面模型的 错误,这样的过程导致新的模型越来越关注困难的训练数据。AdaBoosti逐个训练模型的思想 类似梯度下降。不同的是,梯度下降尝试通过寻找最优参数最小化代价函数,AdaBoosti通过 添加新的模型提升模型的效果。所有模型训练完成后,AdaBoostf使用类似bagging的方式整 合结果。只是不同的模型根据他们在带权训川练数据的预测结果拥有不同的权重 Gradi nt Boo osting 和AdaBoost类似,Gradient Boosting逐个训练模型, 当前的模型尝试红 正前面的模型的错误。但是,AdaBoost纠正错误的方法是更加关注前面模型的错误, Gradient Boosting纠正错误的方法是拟合前面模型的残差。 。上机练习 运行提供的第十音代码 ①通过构造的数据集利用逻辑回归,随机森林和SVM训练v ting classifier。注意默认情况下 SVM不能够预测类别的概率,需要设置参数probability,这样的设置会降低训练速度。可 以发现,hard voting classifier达到89.6%的准确率,soft voting classifieri达到91.2%的准 确率,均高于单独的分类器」 ②比较决策树的决策边界和基于决策树的BaggingC1的决策边界。虽然两种模型在训 练数据上的结果类以,但是BaggingClassifier的决策边界更加平滑,在测试数据上的结果 更加优秀,说明集成学习得到的结果具有类似的偏差和较低的方差。 Decsion Trees with B 10 10、1。 ③通过sklearn提供的GradientBoostingRegressor3实现Gradient Boosting,有控制决策树训 练的参数(max depth)和控制模型集成的参数(n_estimators)。测试不同控制模型集 成参数的训练结果, 可以看到n_estimatd 3的模型基础模型过少,存在欠拟合的问题, 而n estimators=200的模型基础模型过多,存在过拟合的问题。 11 王宇睿 2015201906 部分特征中寻找最优的特征。能够提升模型多样性,从⽽增加偏差,减少⽅差,通常,训练的 效果能够得到提升。 特征᯿要度:决策树中,᯿要的特征往往靠近树的根部,不᯿要的特征往往靠近树的底部,或 者不出现在决策树结点,能够根据森林中特征的平均深度判断特征的᯿要程度。scikit-learn⾃ 动进⾏以上过程,可以通过feature_importance获得特征的᯿要程度。以iris数据为例,petal length(44%)和petal width(42%)是相对᯿要的特征,sepal length(11%)和sepal width(2%)是相对不᯿要的特征。 AdaBoost:当使⽤AdaBoost进⾏分类时,当前模型纠正错误的⽅法包括更加关注前⾯模型的 错误,这样的过程导致新的模型越来越关注困难的训练数据。AdaBoost逐个训练模型的思想 类似梯度下降。不同的是,梯度下降尝试通过寻找最优参数最⼩化代价函数,AdaBoost通过 添加新的模型提升模型的效果。所有模型训练完成后,AdaBoost使⽤类似bagging的⽅式整 合结果,只是不同的模型根据他们在带权训练数据的预测结果拥有不同的权᯿。 Gradient Boosting:和AdaBoost类似,Gradient Boosting逐个训练模型,当前的模型尝试纠 正前⾯的模型的错误。但是,AdaBoost纠正错误的⽅法是更加关注前⾯模型的错误, Gradient Boosting纠正错误的⽅法是拟合前⾯模型的残差。 - 上机练习 运⾏提供的第七章代码。 ① 通过构造的数据集利⽤逻辑回归,随机森林和SVM训练voting classifier。注意默认情况下 SVM不能够预测类别的概率,需要设置参数probability,这样的设置会降低训练速度。可 以发现,hard voting classifier达到89.6%的准确率,soft voting classifier达到91.2%的准 确率,均⾼于单独的分类器。 ② ⽐较决策树的决策边界和基于决策树的BaggingClassifier的决策边界。虽然两种模型在训 练数据上的结果类似,但是BaggingClassifier的决策边界更加平滑,在测试数据上的结果 更加优秀,说明集成学习得到的结果具有类似的偏差和较低的⽅差。 ③ 通过sklearn提供的GradientBoostingRegressor实现Gradient Boosting,有控制决策树训 练的参数(max_depth)和控制模型集成的参数(n_estimators)。测试不同控制模型集 成参数的训练结果,可以看到n_estimators=3的模型基础模型过少,存在⽋拟合的问题, ⽽n_estimators=200的模型基础模型过多,存在过拟合的问题。 11