正在加载图片...
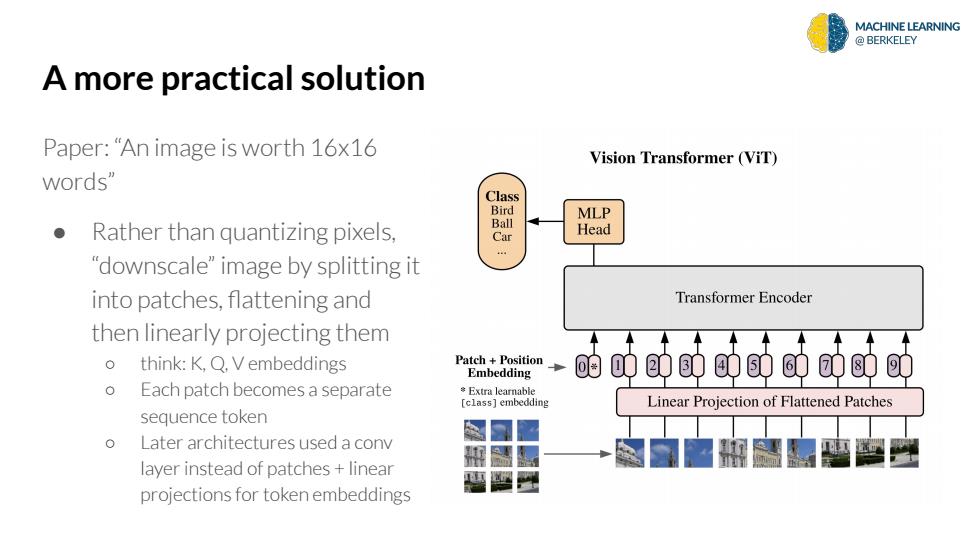
MACHINE LEARNING BERKELEY A more practical solution Paper:"An image is worth 16x16 Vision Transformer (ViT) words" Class Bird MLP Rather than quantizing pixels, Ball Car Head "downscale"image by splitting it into patches,flattening and Transformer Encoder then linearly projecting them 0 think:K,Q.V embeddings Patch Position Embedding 的〔 0欧助的的的的0的 o Each patch becomes a separate Extra learnable [class]embedding Linear Projection of Flattened Patches sequence token o Later architectures used a conv layer instead of patches+linear projections for token embeddingsA more practical solution Paper: “An image is worth 16x16 words” ● Rather than quantizing pixels, “downscale” image by splitting it into patches, flattening and then linearly projecting them ○ think: K, Q, V embeddings ○ Each patch becomes a separate sequence token ○ Later architectures used a conv layer instead of patches + linear projections for token embeddings