正在加载图片...
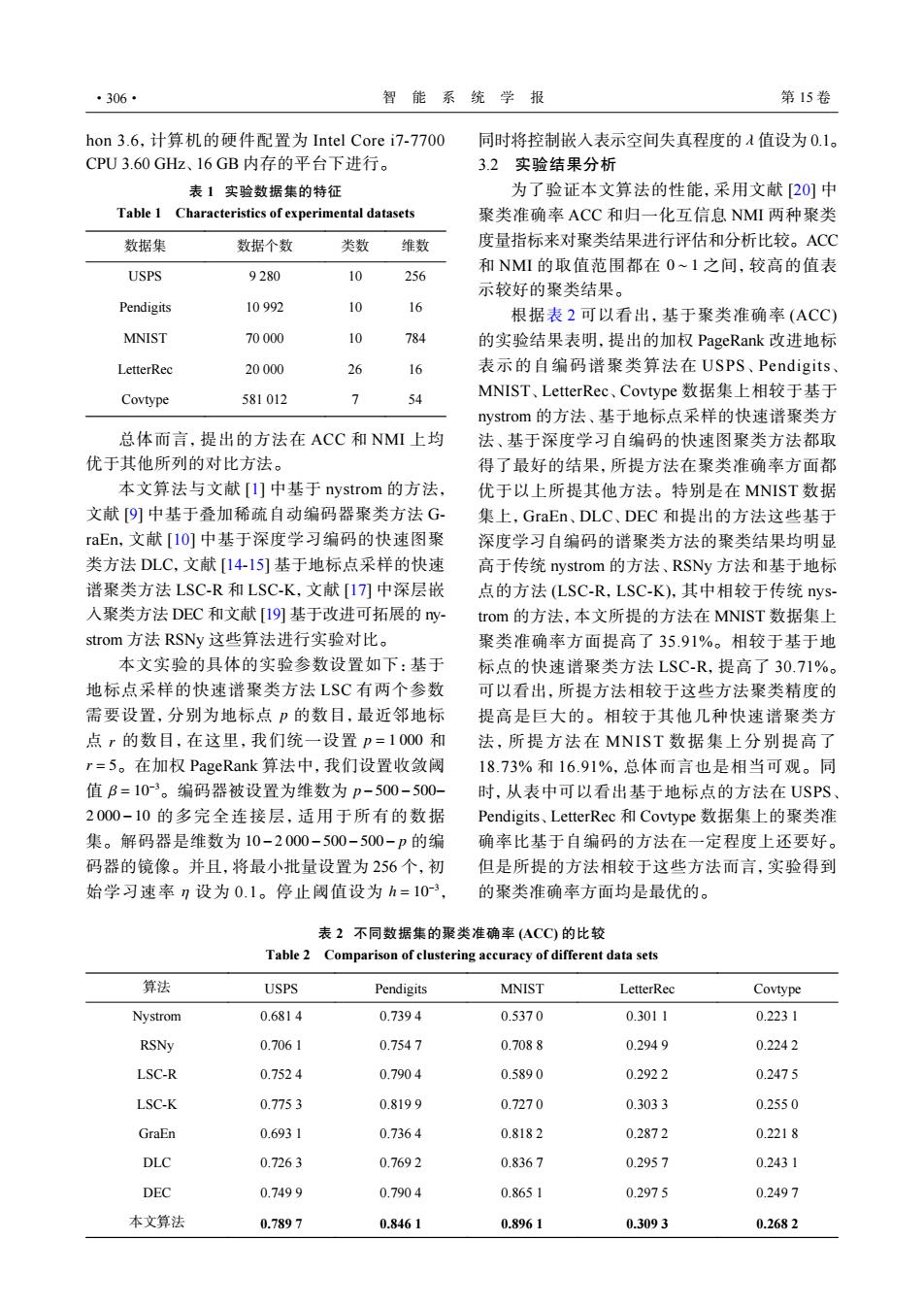
·306· 智能系统学报 第15卷 hon3.6,计算机的硬件配置为Intel Core i7-7700 同时将控制嵌入表示空间失真程度的A值设为0.1。 CPU3.60GHz、16GB内存的平台下进行。 3.2实验结果分析 表1实验数据集的特征 为了验证本文算法的性能,采用文献[20]中 Table 1 Characteristics of experimental datasets 聚类准确率ACC和归一化互信息NMⅫ两种聚类 数据集 数据个数 类数 维数 度量指标来对聚类结果进行评估和分析比较。AC℃ 和NM的取值范围都在0~1之间,较高的值表 USPS 9280 10 256 示较好的聚类结果。 Pendigits 10992 10 16 根据表2可以看出,基于聚类准确率(ACC) MNIST 70000 10 784 的实验结果表明,提出的加权PageRank改进地标 LetterRec 20000 26 16 表示的自编码谱聚类算法在USPS、Pendigits、 Covtype 581012 7 54 MNIST、LetterRec、Covtype数据集上相较于基于 nystrom的方法、基于地标点采样的快速谱聚类方 总体而言,提出的方法在ACC和NMI上均 法、基于深度学习自编码的快速图聚类方法都取 优于其他所列的对比方法。 得了最好的结果,所提方法在聚类准确率方面都 本文算法与文献[I]中基于nystrom的方法, 优于以上所提其他方法。特别是在MNIST数据 文献[9]中基于叠加稀疏自动编码器聚类方法G- 集上,GraEn、DLC、DEC和提出的方法这些基于 raEn,文献[10]中基于深度学习编码的快速图聚 深度学习自编码的谱聚类方法的聚类结果均明显 类方法DLC,文献[14-15]基于地标点采样的快速 高于传统nystrom的方法、RSNy方法和基于地标 谱聚类方法LSC-R和LSC-K,文献[17)]中深层嵌 点的方法(LSC-R,LSC-K),其中相较于传统ys- 入聚类方法DEC和文献[I9]基于改进可拓展的y- trom的方法,本文所提的方法在MNIST数据集上 strom方法RSNy这些算法进行实验对比。 聚类准确率方面提高了35.91%。相较于基于地 本文实验的具体的实验参数设置如下:基于 标点的快速谱聚类方法LSC-R,提高了30.71%。 地标点采样的快速谱聚类方法L$C有两个参数 可以看出,所提方法相较于这些方法聚类精度的 需要设置,分别为地标点p的数目,最近邻地标 提高是巨大的。相较于其他几种快速谱聚类方 点r的数目,在这里,我们统一设置p=1000和 法,所提方法在MNIST数据集上分别提高了 r=5。在加权PageRank算法中,我们设置收敛阈 18.73%和16.91%,总体而言也是相当可观。同 值B=10-3。编码器被设置为维数为p-500-500- 时,从表中可以看出基于地标点的方法在USPS 2000-10的多完全连接层,适用于所有的数据 Pendigits、LetterRec和Covtype数据集上的聚类准 集。解码器是维数为10-2000-500-500-p的编 确率比基于自编码的方法在一定程度上还要好。 码器的镜像。并且,将最小批量设置为256个,初 但是所提的方法相较于这些方法而言,实验得到 始学习速率n设为0.1。停止阈值设为h=10-3, 的聚类准确率方面均是最优的。 表2不同数据集的聚类准确率(ACC)的比较 Table 2 Comparison of clustering accuracy of different data sets 算法 USPS Pendigits MNIST LetterRec Covtype Nystrom 0.6814 0.7394 0.5370 0.3011 0.2231 RSNy 0.7061 0.7547 0.7088 0.2949 0.2242 LSC-R 0.7524 0.7904 0.5890 0.2922 0.2475 LSC-K 0.7753 0.8199 0.7270 0.3033 0.2550 GraEn 0.6931 0.7364 0.8182 0.2872 0.2218 DLC 0.7263 0.7692 0.8367 0.2957 0.2431 DEC 0.7499 0.7904 0.8651 0.2975 0.2497 本文算法 0.7897 0.8461 0.8961 0.3093 0.2682hon 3.6,计算机的硬件配置为 Intel Core i7-7700 CPU 3.60 GHz、16 GB 内存的平台下进行。 总体而言,提出的方法在 ACC 和 NMI 上均 优于其他所列的对比方法。 本文算法与文献 [1] 中基于 nystrom 的方法, 文献 [9] 中基于叠加稀疏自动编码器聚类方法 GraEn,文献 [10] 中基于深度学习编码的快速图聚 类方法 DLC,文献 [14-15] 基于地标点采样的快速 谱聚类方法 LSC-R 和 LSC-K,文献 [17] 中深层嵌 入聚类方法 DEC 和文献 [19] 基于改进可拓展的 nystrom 方法 RSNy 这些算法进行实验对比。 p r p = 1 000 r = 5 β = 10−3 p−500−500− 2 000−10 10−2 000−500−500− p η h = 10−3 本文实验的具体的实验参数设置如下:基于 地标点采样的快速谱聚类方法 LSC 有两个参数 需要设置,分别为地标点 的数目,最近邻地标 点 的数目,在这里,我们统一设置 和 。在加权 PageRank 算法中,我们设置收敛阈 值 。编码器被设置为维数为 的多完全连接层,适用于所有的数据 集。解码器是维数为 的编 码器的镜像。并且,将最小批量设置为 256 个,初 始学习速率 设为 0.1。停止阈值设为 , 同时将控制嵌入表示空间失真程度的 λ 值设为 0.1。 3.2 实验结果分析 0 ∼ 1 为了验证本文算法的性能,采用文献 [20] 中 聚类准确率 ACC 和归一化互信息 NMI 两种聚类 度量指标来对聚类结果进行评估和分析比较。ACC 和 NMI 的取值范围都在 之间,较高的值表 示较好的聚类结果。 根据表 2 可以看出,基于聚类准确率 (ACC) 的实验结果表明,提出的加权 PageRank 改进地标 表示的自编码谱聚类算法在 USPS、Pendigits、 MNIST、LetterRec、Covtype 数据集上相较于基于 nystrom 的方法、基于地标点采样的快速谱聚类方 法、基于深度学习自编码的快速图聚类方法都取 得了最好的结果,所提方法在聚类准确率方面都 优于以上所提其他方法。特别是在 MNIST 数据 集上,GraEn、DLC、DEC 和提出的方法这些基于 深度学习自编码的谱聚类方法的聚类结果均明显 高于传统 nystrom 的方法、RSNy 方法和基于地标 点的方法 (LSC-R,LSC-K),其中相较于传统 nystrom 的方法,本文所提的方法在 MNIST 数据集上 聚类准确率方面提高了 35.91%。相较于基于地 标点的快速谱聚类方法 LSC-R,提高了 30.71%。 可以看出,所提方法相较于这些方法聚类精度的 提高是巨大的。相较于其他几种快速谱聚类方 法,所提方法在 MNIST 数据集上分别提高了 18.73% 和 16.91%,总体而言也是相当可观。同 时,从表中可以看出基于地标点的方法在 USPS、 Pendigits、LetterRec 和 Covtype 数据集上的聚类准 确率比基于自编码的方法在一定程度上还要好。 但是所提的方法相较于这些方法而言,实验得到 的聚类准确率方面均是最优的。 表 1 实验数据集的特征 Table 1 Characteristics of experimental datasets 数据集 数据个数 类数 维数 USPS 9 280 10 256 Pendigits 10 992 10 16 MNIST 70 000 10 784 LetterRec 20 000 26 16 Covtype 581 012 7 54 表 2 不同数据集的聚类准确率 (ACC) 的比较 Table 2 Comparison of clustering accuracy of different data sets 算法 USPS Pendigits MNIST LetterRec Covtype Nystrom 0.681 4 0.739 4 0.537 0 0.301 1 0.223 1 RSNy 0.706 1 0.754 7 0.708 8 0.294 9 0.224 2 LSC-R 0.752 4 0.790 4 0.589 0 0.292 2 0.247 5 LSC-K 0.775 3 0.819 9 0.727 0 0.303 3 0.255 0 GraEn 0.693 1 0.736 4 0.818 2 0.287 2 0.221 8 DLC 0.726 3 0.769 2 0.836 7 0.295 7 0.243 1 DEC 0.749 9 0.790 4 0.865 1 0.297 5 0.249 7 本文算法 0.789 7 0.846 1 0.896 1 0.309 3 0.268 2 ·306· 智 能 系 统 学 报 第 15 卷