正在加载图片...
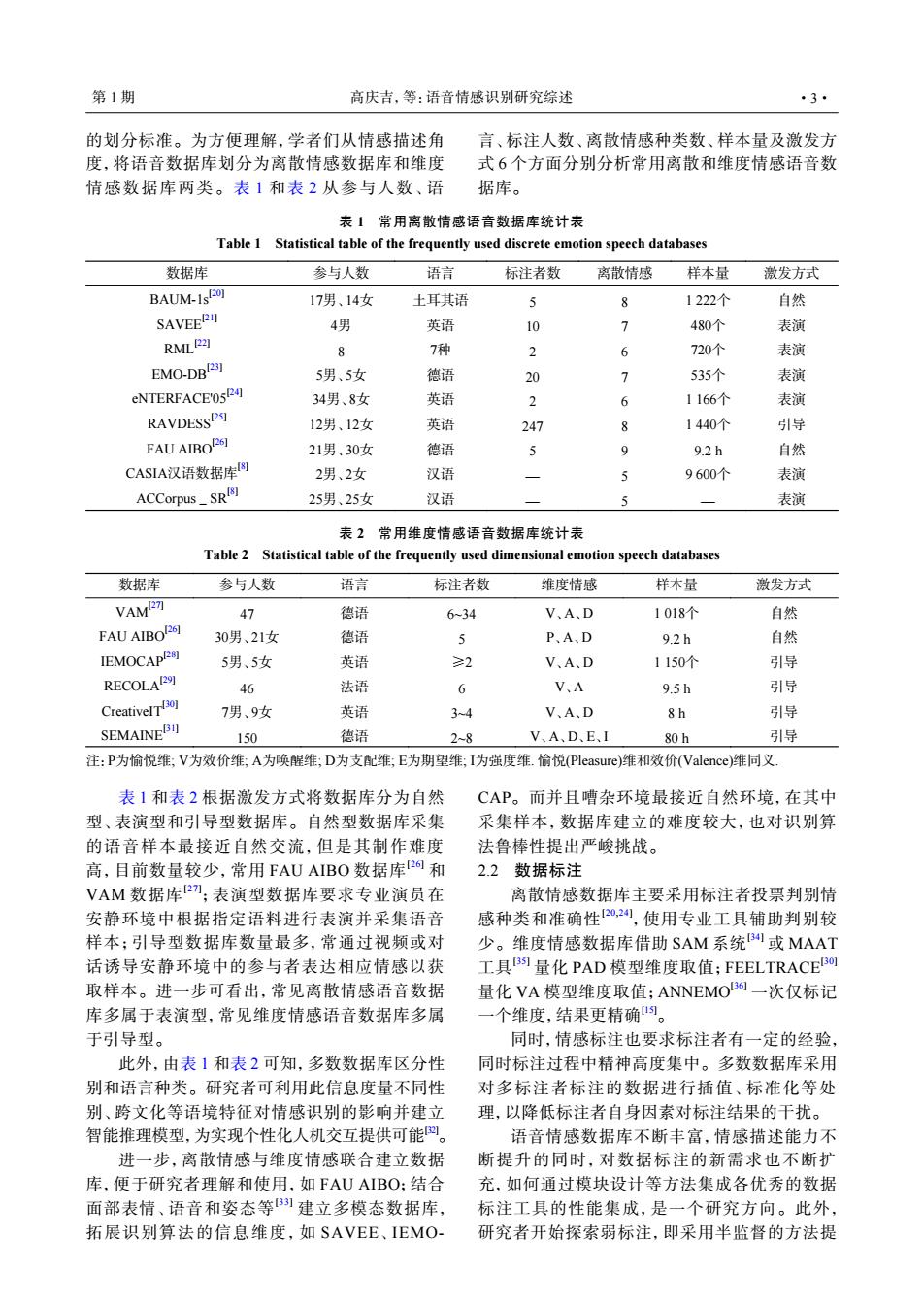
第1期 高庆吉,等:语音情感识别研究综述 的划分标准。为方便理解,学者们从情感描述角 言、标注人数、离散情感种类数、样本量及激发方 度,将语音数据库划分为离散情感数据库和维度 式6个方面分别分析常用离散和维度情感语音数 情感数据库两类。表1和表2从参与人数、语 据库。 表1常用离散情感语音数据库统计表 Table 1 Statistical table of the frequently used discrete emotion speech databases 数据库 参与人数 语言 标注者数 离散情感 样本量 激发方式 BAUM-1s1201 17男、14女 土耳其语 5 8 1222个 自然 SAVEERn 4男 英语 10 > 480个 表演 RMLP☒ 8 7种 2 6 720个 表演 EMO-DBI231 5男、5女 德语 20 > 535个 表演 eNTERFACE'05R41 34男、8女 英语 2 6 1166个 表演 RAVDESSI2ST 12男、12女 英语 247 1440个 引导 FAU AIBO2阿 21男、30女 德语 5 9 9.2h 自然 CASIA汉语数据库图 2男、2女 汉语 9600个 表演 ACCorpus_SRt8] 25男、25女 汉语 表演 表2常用维度情感语音数据库统计表 Table 2 Statistical table of the frequently used dimensional emotion speech databases 数据库 参与人数 语言 标注者数 维度情感 样本量 激发方式 VAM2可 47 德语 6-34 V、A、D 1018个 自然 FAU AIBOL61 30男、21女 德语 P、A、D 9.2h 自然 IEMOCAPR8] 5男、5女 英语 ≥2 V、A、D 1150个 引导 RECOLAI291 46 法语 6 V、A 9.5h 引导 CreativelT 7男、9女 英语 34 V、A、D 8h 引导 SEMAINEB 150 德语 2-8 V、A、D、E、I 80h 引导 注:P为愉悦维;V为效价维;A为唤醒维;D为支配维;E为期望维;I为强度维.愉悦(Pleasure)维和效价(Valence)维同义 表1和表2根据激发方式将数据库分为自然 CAP。而并且嘈杂环境最接近自然环境,在其中 型、表演型和引导型数据库。自然型数据库采集 采集样本,数据库建立的难度较大,也对识别算 的语音样本最接近自然交流,但是其制作难度 法鲁棒性提出严峻挑战。 高,目前数量较少,常用FAU AIBO数据库2a和 2.2 数据标注 VAM数据库2m;表演型数据库要求专业演员在 离散情感数据库主要采用标注者投票判别情 安静环境中根据指定语料进行表演并采集语音 感种类和准确性®2刘,使用专业工具辅助判别较 样本:引导型数据库数量最多,常通过视频或对 少。维度情感数据库借助SAM系统B41或MAAT 话诱导安静环境中的参与者表达相应情感以获 工具B量化PAD模型维度取值;FEELTRACE0 取样本。进一步可看出,常见离散情感语音数据 量化VA模型维度取值;AnneMo一次仅标记 库多属于表演型,常见维度情感语音数据库多属 一个维度,结果更精确。 于引导型。 同时,情感标注也要求标注者有一定的经验, 此外,由表1和表2可知,多数数据库区分性 同时标注过程中精神高度集中。多数数据库采用 别和语言种类。研究者可利用此信息度量不同性 对多标注者标注的数据进行插值、标准化等处 别、跨文化等语境特征对情感识别的影响并建立 理,以降低标注者自身因素对标注结果的干扰。 智能推理模型,为实现个性化人机交互提供可能四。 语音情感数据库不断丰富,情感描述能力不 进一步,离散情感与维度情感联合建立数据 断提升的同时,对数据标注的新需求也不断扩 库,便于研究者理解和使用,如FAU AIBO;结合 充,如何通过模块设计等方法集成各优秀的数据 面部表情、语音和姿态等1建立多模态数据库, 标注工具的性能集成,是一个研究方向。此外, 拓展识别算法的信息维度,如SAVEE、IEMO- 研究者开始探索弱标注,即采用半监督的方法提的划分标准。为方便理解,学者们从情感描述角 度,将语音数据库划分为离散情感数据库和维度 情感数据库两类。表 1 和表 2 从参与人数、语 言、标注人数、离散情感种类数、样本量及激发方 式 6 个方面分别分析常用离散和维度情感语音数 据库。 表 1 常用离散情感语音数据库统计表 Table 1 Statistical table of the frequently used discrete emotion speech databases 数据库 参与人数 语言 标注者数 离散情感 样本量 激发方式 BAUM-1s[20] 17男、14女 土耳其语 5 8 1 222个 自然 SAVEE[21] 4男 英语 10 7 480个 表演 RML[22] 8 7种 2 6 720个 表演 EMO-DB[23] 5男、5女 德语 20 7 535个 表演 eNTERFACE'05[24] 34男、8女 英语 2 6 1 166个 表演 RAVDESS[25] 12男、12女 英语 247 8 1 440个 引导 FAU AIBO[26] 21男、30女 德语 5 9 9.2 h 自然 CASIA汉语数据库[8] 2男、2女 汉语 — 5 9 600个 表演 ACCorpus_SR[8] 25男、25女 汉语 — 5 — 表演 表 2 常用维度情感语音数据库统计表 Table 2 Statistical table of the frequently used dimensional emotion speech databases 数据库 参与人数 语言 标注者数 维度情感 样本量 激发方式 VAM[27] 47 德语 6~34 V、A、D 1 018个 自然 FAU AIBO[26] 30男、21女 德语 5 P、A、D 9.2 h 自然 IEMOCAP[28] 5男、5女 英语 ≥2 V、A、D 1 150个 引导 RECOLA[29] 46 法语 6 V、A 9.5 h 引导 CreativeIT[30] 7男、9女 英语 3~4 V、A、D 8 h 引导 SEMAINE[31] 150 德语 2~8 V、A、D、E、I 80 h 引导 注:P为愉悦维; V为效价维; A为唤醒维; D为支配维; E为期望维; I为强度维. 愉悦(Pleasure)维和效价(Valence)维同义. 表 1 和表 2 根据激发方式将数据库分为自然 型、表演型和引导型数据库。自然型数据库采集 的语音样本最接近自然交流,但是其制作难度 高,目前数量较少,常用 FAU AIBO 数据库[26] 和 VAM 数据库[27] ;表演型数据库要求专业演员在 安静环境中根据指定语料进行表演并采集语音 样本;引导型数据库数量最多,常通过视频或对 话诱导安静环境中的参与者表达相应情感以获 取样本。进一步可看出,常见离散情感语音数据 库多属于表演型,常见维度情感语音数据库多属 于引导型。 此外,由表 1 和表 2 可知,多数数据库区分性 别和语言种类。研究者可利用此信息度量不同性 别、跨文化等语境特征对情感识别的影响并建立 智能推理模型,为实现个性化人机交互提供可能[32]。 进一步,离散情感与维度情感联合建立数据 库,便于研究者理解和使用,如 FAU AIBO;结合 面部表情、语音和姿态等[33] 建立多模态数据库, 拓展识别算法的信息维度,如 SAVEE、IEMOCAP。而并且嘈杂环境最接近自然环境,在其中 采集样本,数据库建立的难度较大,也对识别算 法鲁棒性提出严峻挑战。 2.2 数据标注 离散情感数据库主要采用标注者投票判别情 感种类和准确性[20,24] ,使用专业工具辅助判别较 少。维度情感数据库借助 SAM 系统[34] 或 MAAT 工具[35] 量化 PAD 模型维度取值;FEELTRACE[30] 量化 VA 模型维度取值;ANNEMO[36] 一次仅标记 一个维度,结果更精确[15]。 同时,情感标注也要求标注者有一定的经验, 同时标注过程中精神高度集中。多数数据库采用 对多标注者标注的数据进行插值、标准化等处 理,以降低标注者自身因素对标注结果的干扰。 语音情感数据库不断丰富,情感描述能力不 断提升的同时,对数据标注的新需求也不断扩 充,如何通过模块设计等方法集成各优秀的数据 标注工具的性能集成,是一个研究方向。此外, 研究者开始探索弱标注,即采用半监督的方法提 第 1 期 高庆吉,等:语音情感识别研究综述 ·3·