正在加载图片...
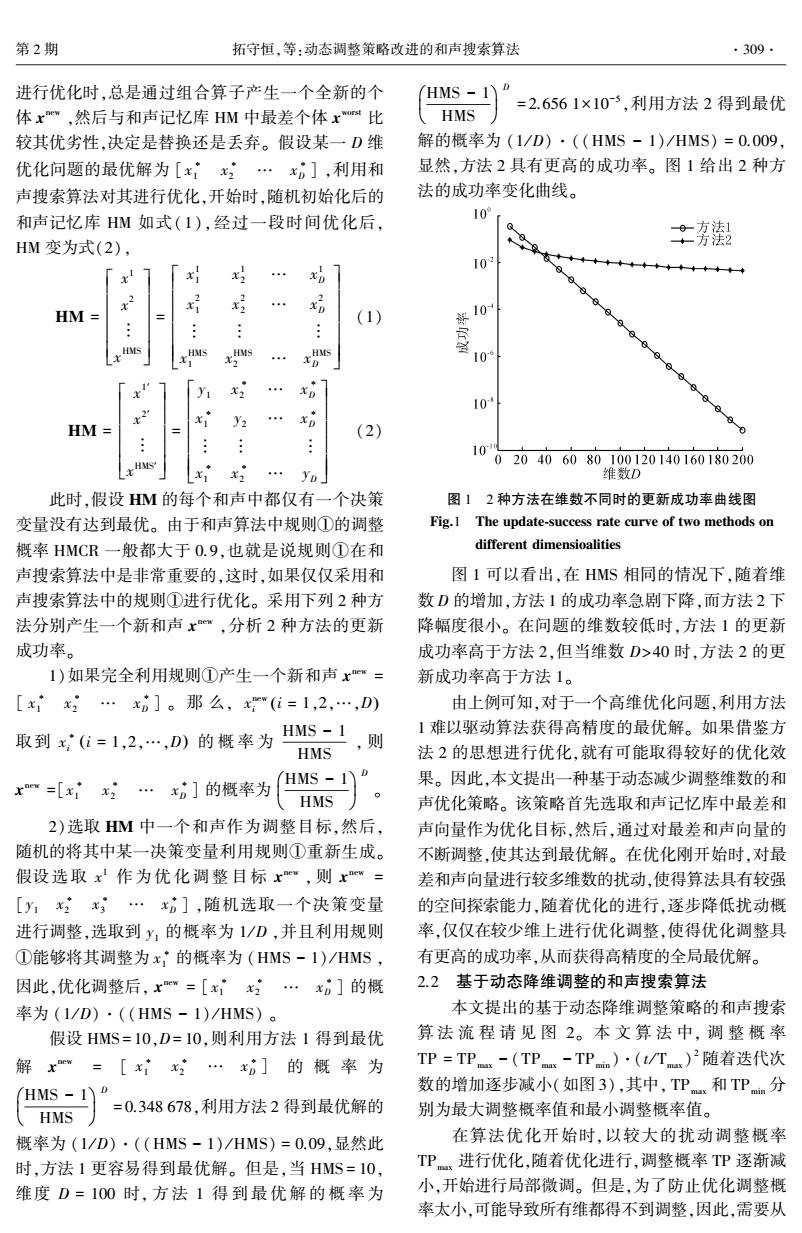
第2期 拓守恒,等:动态调整策略改进的和声搜索算法 ·309· 进行优化时,总是通过组合算子产生一个全新的个 HMS =2.6561×10-5,利用方法2得到最优 体x",然后与和声记忆库HM中最差个体x比 HMS 较其优劣性,决定是替换还是丢弃。假设某一D维 解的概率为(1/D)·((HMS-1)/HMS)=0.009, 优化问题的最优解为[xx…x],利用和 显然,方法2具有更高的成功率。图1给出2种方 声搜索算法对其进行优化,开始时,随机初始化后的 法的成功率变化曲线。 和声记忆库HM如式(1),经过一段时间优化后, 10 HM变为式(2), ·嘉潮 ◆ x 对 10 x好 HM (1) 10 109 y 10 x HM= 9 (2) 10 020406080100120140160180200 维数D 此时,假设HM的每个和声中都仅有一个决策 图12种方法在维数不同时的更新成功率曲线图 变量没有达到最优。由于和声算法中规则①的调整 Fig.1 The update-success rate curve of two methods on 概率HMCR一般都大于O.9,也就是说规则①在和 different dimensioalities 声搜索算法中是非常重要的,这时,如果仅仅采用和 图1可以看出,在HMS相同的情况下,随着维 声搜索算法中的规则①进行优化。采用下列2种方 数D的增加,方法1的成功率急剧下降,而方法2下 法分别产生一个新和声x,分析2种方法的更新 降幅度很小。在问题的维数较低时,方法1的更新 成功率。 成功率高于方法2,但当维数D>40时,方法2的更 1)如果完全利用规则①产生一个新和声x"= 新成功率高于方法1。 [x…x0]。那么,x"(i=1,2,…,D) 由上例可知,对于一个高维优化问题,利用方法 取到x(i=1,2,…,D)的概率为 HMS 1 ,则 1难以驱动算法获得高精度的最优解。如果借鉴方 HMS 法2的思想进行优化,就有可能取得较好的优化效 x=[xx…x]的概率为 HMS -1 果。因此,本文提出一种基于动态减少调整维数的和 HMS 声优化策略。该策略首先选取和声记忆库中最差和 2)选取HM中一个和声作为调整目标,然后, 声向量作为优化目标,然后,通过对最差和声向量的 随机的将其中某一决策变量利用规则①重新生成。 不断调整,使其达到最优解。在优化刚开始时,对最 假设选取x作为优化调整目标x",则xew= 差和声向量进行较多维数的扰动,使得算法具有较强 [y1x2x;…x。],随机选取一个决策变量 的空间探索能力,随着优化的进行,逐步降低扰动概 进行调整,选取到y1的概率为1/D,并且利用规则 率,仅仅在较少维上进行优化调整,使得优化调整具 ①能够将其调整为x的概率为(HMS-1)/HMS, 有更高的成功率,从而获得高精度的全局最优解。 因此,优化调整后,x=[xx…x0]的概 2.2基于动态降维调整的和声搜索算法 率为(1/D)·((HMS-1)/HMS)。 本文提出的基于动态降维调整策略的和声搜索 假设HMS=10,D=10,则利用方法1得到最优 算法流程请见图2。本文算法中,调整概率 解x=[xx…x门的概率为 TP=TP-(TP-TP)·(t/T)2随着迭代次 HMS -1 数的增加逐步减小(如图3),其中,TP和TPn分 、HMS =0.348678,利用方法2得到最优解的 别为最大调整概率值和最小调整概率值。 概率为(1/D)·((HMS-1)/HMS)=0.09,显然此 在算法优化开始时,以较大的扰动调整概率 时,方法1更容易得到最优解。但是,当HMS=10, TPx进行优化,随着优化进行,调整概率TP逐渐减 维度D=100时,方法1得到最优解的概率为 小,开始进行局部微调。但是,为了防止优化调整概 率太小,可能导致所有维都得不到调整,因此,需要从进行优化时,总是通过组合算子产生一个全新的个 体 x new ,然后与和声记忆库 HM 中最差个体 x worst 比 较其优劣性,决定是替换还是丢弃。 假设某一 D 维 优化问题的最优解为 [x ∗ 1 x ∗ 2 … x ∗ D ] ,利用和 声搜索算法对其进行优化,开始时,随机初始化后的 和声记忆库 HM 如式(1),经过一段时间优化后, HM 变为式(2), HM = x 1 x 2 ︙ x HMS é ë ê ê ê ê ê ù û ú ú ú ú ú = x 1 1 x 1 2 … x 1 D x 2 1 x 2 2 … x 2 D ︙ ︙ ︙ x HMS 1 x HMS 2 … x HMS D é ë ê ê ê ê ê ê ù û ú ú ú ú ú ú (1) HM = x 1′ x 2′ ︙ x HMS′ é ë ê ê ê ê ê ù û ú ú ú ú ú = y1 x ∗ 2 … x ∗ D x ∗ 1 y2 … x ∗ D ︙ ︙ ︙ x ∗ 1 x ∗ 2 … yD é ë ê ê ê ê ê ê ù û ú ú ú ú ú ú (2) 此时,假设 HM 的每个和声中都仅有一个决策 变量没有达到最优。 由于和声算法中规则①的调整 概率 HMCR 一般都大于 0.9,也就是说规则①在和 声搜索算法中是非常重要的,这时,如果仅仅采用和 声搜索算法中的规则①进行优化。 采用下列 2 种方 法分别产生一个新和声 x new ,分析 2 种方法的更新 成功率。 1)如果完全利用规则①产生一个新和声 x new = [ x ∗ 1 x ∗ 2 … x ∗ D ] 。 那 么, x new i (i = 1,2,…,D) 取到 x ∗ i (i = 1,2,…,D) 的 概 率 为 HMS - 1 HMS , 则 x new =[x ∗ 1 x ∗ 2 … x ∗ D ] 的概率为 HMS - 1 HMS æ è ç ö ø ÷ D 。 2)选取 HM 中一个和声作为调整目标,然后, 随机的将其中某一决策变量利用规则①重新生成。 假设选取 x 1 作为优化 调 整 目 标 x new , 则 x new = [y1 x ∗ 2 x ∗ 3 … x ∗ D ] ,随机选取一个决策变量 进行调整,选取到 y1 的概率为 1 / D ,并且利用规则 ①能够将其调整为 x ∗ 1 的概率为 (HMS - 1) / HMS , 因此,优化调整后, x new = [ x ∗ 1 x ∗ 2 … x ∗ D ] 的概 率为 (1 / D)·((HMS - 1) / HMS) 。 假设 HMS = 10,D= 10,则利用方法 1 得到最优 解 x new = [ x ∗ 1 x ∗ 2 … x ∗ D ] 的 概 率 为 HMS - 1 HMS æ è ç ö ø ÷ D = 0.348 678,利用方法 2 得到最优解的 概率为 (1 / D)·((HMS - 1) / HMS) = 0.09,显然此 时,方法 1 更容易得到最优解。 但是,当 HMS = 10, 维度 D = 100 时, 方 法 1 得 到 最 优 解 的 概 率 为 HMS - 1 HMS æ è ç ö ø ÷ D = 2.656 1×10 -5 ,利用方法 2 得到最优 解的概率为 (1 / D)·((HMS - 1) / HMS) = 0.009, 显然,方法 2 具有更高的成功率。 图 1 给出 2 种方 法的成功率变化曲线。 图 1 2 种方法在维数不同时的更新成功率曲线图 Fig.1 The update⁃success rate curve of two methods on different dimensioalities 图 1 可以看出,在 HMS 相同的情况下,随着维 数 D 的增加,方法 1 的成功率急剧下降,而方法 2 下 降幅度很小。 在问题的维数较低时,方法 1 的更新 成功率高于方法 2,但当维数 D>40 时,方法 2 的更 新成功率高于方法 1。 由上例可知,对于一个高维优化问题,利用方法 1 难以驱动算法获得高精度的最优解。 如果借鉴方 法 2 的思想进行优化,就有可能取得较好的优化效 果。 因此,本文提出一种基于动态减少调整维数的和 声优化策略。 该策略首先选取和声记忆库中最差和 声向量作为优化目标,然后,通过对最差和声向量的 不断调整,使其达到最优解。 在优化刚开始时,对最 差和声向量进行较多维数的扰动,使得算法具有较强 的空间探索能力,随着优化的进行,逐步降低扰动概 率,仅仅在较少维上进行优化调整,使得优化调整具 有更高的成功率,从而获得高精度的全局最优解。 2.2 基于动态降维调整的和声搜索算法 本文提出的基于动态降维调整策略的和声搜索 算 法 流 程 请 见 图 2。 本 文 算 法 中, 调 整 概 率 TP = TP max - (TP max - TP min )·(t / Tmax) 2 随着迭代次 数的增加逐步减小(如图 3),其中, TP max 和 TP min 分 别为最大调整概率值和最小调整概率值。 在算法优化开始时,以较大的扰动调整概率 TPmax 进行优化,随着优化进行,调整概率 TP 逐渐减 小,开始进行局部微调。 但是,为了防止优化调整概 率太小,可能导致所有维都得不到调整,因此,需要从 第 2 期 拓守恒,等:动态调整策略改进的和声搜索算法 ·309·