正在加载图片...
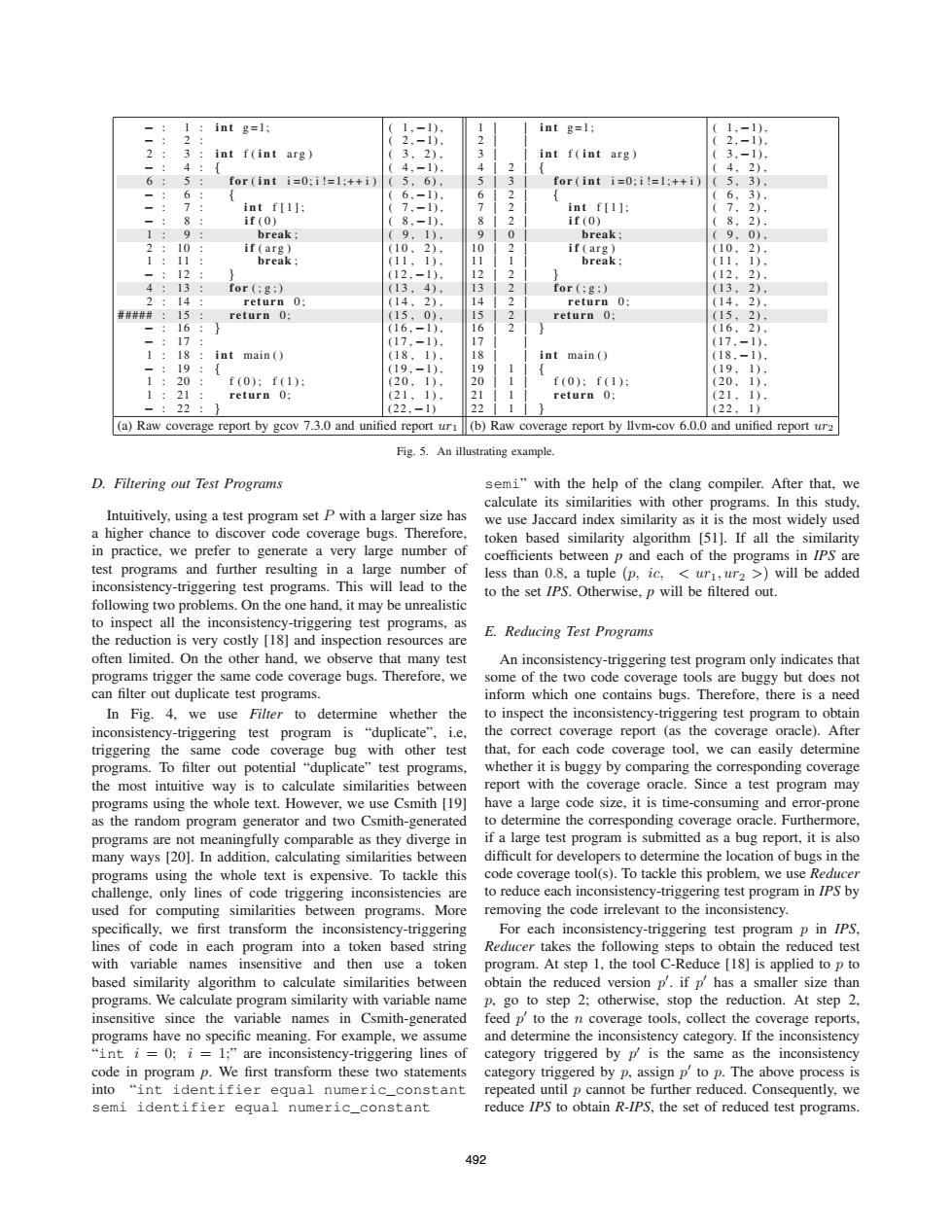
int g=1: int g=1; -1) 2 3 int f(int arg) 3 2》 3 int f(int arg) -1) 4,-1) 4 2) 6 for(inti=0:i1=1:++i)(5, 6)1 for(int i=0:i!=1:++i)( 5 3) 6 6。-11 2 6, 3) 7 int f[l]; 7 -1). > 8 if(0) 8,-1) 22 int f[l]: 7. 2) if(0) 8,2) 1 9 break: (9,1), 9 0 break; ( 9, 0). 10 if (arg) 10, 2)+ 10 if(arg) (10. 2) 1 break: (11, 11 l break: (11.1). 12 (12,-1), 12 22 (12 2) 413 for (g:) (13, 4)1 13 for(:g:) (13.2) 2 14 return 0; (14, 2), 14 2 return 0; (14, 2). ####柱 15 return 0: 15 0)+ 15 return 0: 15 21 16 16.】. 16 2 (16.2) 17 (17,-1). 1 (17.-1) 1: int main() (18 18 int main() (18.-1) 19 (19,-1) 19 (19, 1) 1: f(0):f(1): (20, 1) 20 f(0):f(1) (20, 1) 1: 21 return 0; 2】. 21 return 0; (21, 1) - 22 (22,-1) 22 (22,1) (a)Raw coverage report by gcov 7.3.0 and unified report ur1 (b)Raw coverage report by llvm-cov 6.0.0 and unified report ur2 Fig.5.An illustrating example. D.Filtering out Test Programs semi"with the help of the clang compiler.After that,we calculate its similarities with other programs.In this study. Intuitively,using a test program set P with a larger size has we use Jaccard index similarity as it is the most widely used a higher chance to discover code coverage bugs.Therefore, token based similarity algorithm [51].If all the similarity in practice,we prefer to generate a very large number of coefficients between p and each of the programs in IPS are test programs and further resulting in a large number of less than 0.8,a tuple (p,ic,<ur1,ur2 >will be added inconsistency-triggering test programs.This will lead to the to the set IPS.Otherwise,p will be filtered out. following two problems.On the one hand,it may be unrealistic to inspect all the inconsistency-triggering test programs,as the reduction is very costly [18]and inspection resources are E.Reducing Test Programs often limited.On the other hand,we observe that many test An inconsistency-triggering test program only indicates that programs trigger the same code coverage bugs.Therefore,we some of the two code coverage tools are buggy but does not can filter out duplicate test programs. inform which one contains bugs.Therefore,there is a need In Fig.4,we use Filter to determine whether the to inspect the inconsistency-triggering test program to obtain inconsistency-triggering test program is "duplicate",i.e, the correct coverage report (as the coverage oracle).After triggering the same code coverage bug with other test that,for each code coverage tool,we can easily determine programs.To filter out potential "duplicate"test programs, whether it is buggy by comparing the corresponding coverage the most intuitive way is to calculate similarities between report with the coverage oracle.Since a test program may programs using the whole text.However,we use Csmith [19] have a large code size,it is time-consuming and error-prone as the random program generator and two Csmith-generated to determine the corresponding coverage oracle.Furthermore, programs are not meaningfully comparable as they diverge in if a large test program is submitted as a bug report,it is also many ways [20].In addition,calculating similarities between difficult for developers to determine the location of bugs in the programs using the whole text is expensive.To tackle this code coverage tool(s).To tackle this problem,we use Reducer challenge,only lines of code triggering inconsistencies are to reduce each inconsistency-triggering test program in IPS by used for computing similarities between programs.More removing the code irrelevant to the inconsistency. specifically,we first transform the inconsistency-triggering For each inconsistency-triggering test program p in IPS. lines of code in each program into a token based string Reducer takes the following steps to obtain the reduced test with variable names insensitive and then use a token program.At step 1,the tool C-Reduce [18]is applied to p to based similarity algorithm to calculate similarities between obtain the reduced version p'.if p'has a smaller size than programs.We calculate program similarity with variable name p,go to step 2;otherwise,stop the reduction.At step 2. insensitive since the variable names in Csmith-generated feed p'to the n coverage tools,collect the coverage reports. programs have no specific meaning.For example,we assume and determine the inconsistency category.If the inconsistency "int i=0;i=1;"are inconsistency-triggering lines of category triggered by p'is the same as the inconsistency code in program p.We first transform these two statements category triggered by p,assign p'to p.The above process is into "int identifier equal numeric_constant repeated until p cannot be further reduced.Consequently,we semi identifier equal numeric_constant reduce IPS to obtain R-IPS,the set of reduced test programs. 492− : − : 2 : − : 6 : − : − : − : 1 : 2 : 1 : − : 4 : 2 : # #### : − : − : 1 : − : 1 : 1 : − : 1 : 2 : 3 : 4 : 5 : 6 : 7 : 8 : 9 : 10 : 11 : 12 : 13 : 14 : 15 : 16 : 17 : 18 : 19 : 20 : 21 : 22 : int g=1; int f ( int arg ) { for ( int i =0; i !=1;++ i ) { int f [1]; i f (0) break ; i f ( arg ) break ; } for (;g;) return 0 ; return 0 ; } int main ( ) { f (0); f (1); return 0 ; } ( 1, −1), ( 2, −1), ( 3, 2) , ( 4, −1), ( 5, 6) , ( 6, −1), ( 7, −1), ( 8, −1), ( 9, 1) , (10 , 2) , (11 , 1) , (12, −1), (13 , 4) , (14 , 2) , (15 , 0) , (16, −1), (17, −1), (18 , 1) , (19, −1), (20 , 1) , (21 , 1) , (22, −1 ) 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | | | | 2 | 3 | 2 | 2 | 2 | 0 | 2 | 1 | 2 | 2 | 2 | 2 | 2 | | | 1 | 1 | 1 | 1 | int g=1; int f ( int arg ) { for ( int i =0; i !=1;++ i ) { int f [1]; i f (0) break ; i f ( arg ) break ; } for (;g;) return 0 ; return 0 ; } int main ( ) { f (0); f (1); return 0 ; } ( 1, −1), ( 2, −1), ( 3, −1), ( 4, 2) , ( 5, 3) , ( 6, 3) , ( 7, 2) , ( 8, 2) , ( 9, 0) , (10 , 2) , (11 , 1) , (12 , 2) , (13 , 2) , (14 , 2) , (15 , 2) , (16 , 2) , (17, −1), (18, −1), (19 , 1) , (20 , 1) , (21 , 1) , (22 , 1) (a) Raw coverage report by gcov 7.3.0 and unified report ur1 (b) Raw coverage report by llvm-cov 6.0.0 and unified report ur2 Fig. 5. An illustrating example. D. Filtering out Test Programs Intuitively, using a test program set P with a larger size has a higher chance to discover code coverage bugs. Therefore, in practice, we prefer to generate a very large number of test programs and further resulting in a large number of inconsistency-triggering test programs. This will lead to the following two problems. On the one hand, it may be unrealistic to inspect all the inconsistency-triggering test programs, as the reduction is very costly [18] and inspection resources are often limited. On the other hand, we observe that many test programs trigger the same code coverage bugs. Therefore, we can filter out duplicate test programs. In Fig. 4, we use Filter to determine whether the inconsistency-triggering test program is “duplicate”, i.e, triggering the same code coverage bug with other test programs. To filter out potential “duplicate” test programs, the most intuitive way is to calculate similarities between programs using the whole text. However, we use Csmith [19] as the random program generator and two Csmith-generated programs are not meaningfully comparable as they diverge in many ways [20]. In addition, calculating similarities between programs using the whole text is expensive. To tackle this challenge, only lines of code triggering inconsistencies are used for computing similarities between programs. More specifically, we first transform the inconsistency-triggering lines of code in each program into a token based string with variable names insensitive and then use a token based similarity algorithm to calculate similarities between programs. We calculate program similarity with variable name insensitive since the variable names in Csmith-generated programs have no specific meaning. For example, we assume “int i = 0; i = 1;” are inconsistency-triggering lines of code in program p. We first transform these two statements into “int identifier equal numeric_constant semi identifier equal numeric_constant semi” with the help of the clang compiler. After that, we calculate its similarities with other programs. In this study, we use Jaccard index similarity as it is the most widely used token based similarity algorithm [51]. If all the similarity coefficients between p and each of the programs in IPS are less than 0.8, a tuple (p, ic, < ur1, ur2 >) will be added to the set IPS. Otherwise, p will be filtered out. E. Reducing Test Programs An inconsistency-triggering test program only indicates that some of the two code coverage tools are buggy but does not inform which one contains bugs. Therefore, there is a need to inspect the inconsistency-triggering test program to obtain the correct coverage report (as the coverage oracle). After that, for each code coverage tool, we can easily determine whether it is buggy by comparing the corresponding coverage report with the coverage oracle. Since a test program may have a large code size, it is time-consuming and error-prone to determine the corresponding coverage oracle. Furthermore, if a large test program is submitted as a bug report, it is also difficult for developers to determine the location of bugs in the code coverage tool(s). To tackle this problem, we use Reducer to reduce each inconsistency-triggering test program in IPS by removing the code irrelevant to the inconsistency. For each inconsistency-triggering test program p in IPS, Reducer takes the following steps to obtain the reduced test program. At step 1, the tool C-Reduce [18] is applied to p to obtain the reduced version p . if p has a smaller size than p, go to step 2; otherwise, stop the reduction. At step 2, feed p to the n coverage tools, collect the coverage reports, and determine the inconsistency category. If the inconsistency category triggered by p is the same as the inconsistency category triggered by p, assign p to p. The above process is repeated until p cannot be further reduced. Consequently, we reduce IPS to obtain R-IPS, the set of reduced test programs. 492�����