正在加载图片...
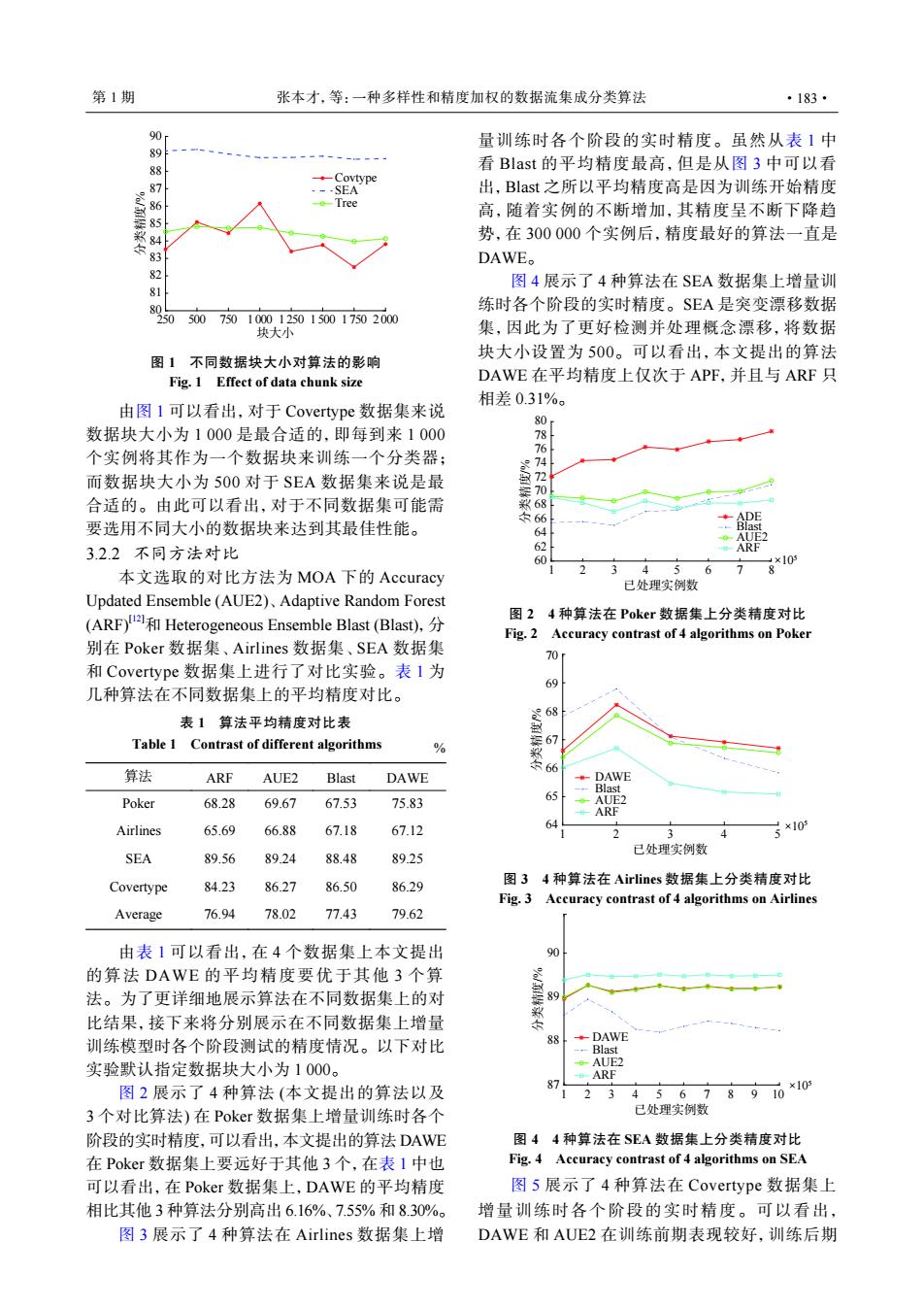
第1期 张本才,等:一种多样性和精度加权的数据流集成分类算法 ·183· 90 量训练时各个阶段的实时精度。虽然从表1中 88 看Blast的平均精度最高,但是从图3中可以看 Covtype ---SEA 出,Blast之所以平均精度高是因为训练开始精度 86 Tree 高,随着实例的不断增加,其精度呈不断下降趋 势,在300000个实例后,精度最好的算法一直是 83 DAWE。 82 图4展示了4种算法在SEA数据集上增量训 81 8 练时各个阶段的实时精度。SEA是突变漂移数据 250 500 75010001250150017502000 块大小 集,因此为了更好检测并处理概念漂移,将数据 块大小设置为500。可以看出,本文提出的算法 图1不同数据块大小对算法的影响 Fig.1 Effect of data chunk size DAWE在平均精度上仅次于APF,并且与ARF只 相差0.31%。 由图1可以看出,对于Covertype数据集来说 80 数据块大小为1000是最合适的,即每到来1000 个实例将其作为一个数据块来训练一个分类器: 而数据块大小为500对于SEA数据集来说是最 合适的。由此可以看出,对于不同数据集可能需 ADE 要选用不同大小的数据块来达到其最佳性能。 东66 64 3.2.2不同方法对比 ARF 60 本文选取的对比方法为MOA下的Accuracy 3 5 6 *10 已处理实例数 Updated Ensemble(AUE2),Adaptive Random Forest (ARF)2 Heterogeneous Ensemble Blast(Blast). 图24种算法在Poker数据集上分类精度对比 Fig.2 Accuracy contrast of 4 algorithms on Poker 别在Poker数据集、Airlines数据集、SEA数据集 70 和Covertype数据集上进行了对比实验。表I为 几种算法在不同数据集上的平均精度对比。 表1算法平均精度对比表 68 Table 1 Contrast of different algorithms % 67 66 算法 ARF AUE2 Blast DAWE ·DAWE Poker 68.28 69.67 67.53 75.83 65 一AR Airlines 65.69 66.88 67.18 67.12 64 4 5*10 已处理实例数 SEA 89.56 89.24 88.48 89.25 图34种算法在Airlines数据集上分类精度对比 Covertype 84.23 86.27 86.50 86.29 Fig.3 Accuracy contrast of 4 algorithms on Airlines Average 76.94 78.02 77.43 79.62 由表1可以看出,在4个数据集上本文提出 90 的算法DAWE的平均精度要优于其他3个算 法。为了更详细地展示算法在不同数据集上的对 比结果,接下来将分别展示在不同数据集上增量 训练模型时各个阶段测试的精度情况。以下对比 88 DAWE -Blast 实验默认指定数据块大小为1000。 。-AUE2 ARF 图2展示了4种算法(本文提出的算法以及 23 4567 891010 3个对比算法)在Pokr数据集上增量训练时各个 已处理实例数 阶段的实时精度,可以看出,本文提出的算法DAWE 图44种算法在SEA数据集上分类精度对比 在Poker数据集上要远好于其他3个,在表1中也 Fig.4 Accuracy contrast of 4 algorithms on SEA 可以看出,在Poker数据集上,DAWE的平均精度 图5展示了4种算法在Covertype数据集上 相比其他3种算法分别高出6.16%、7.55%和8.30%。 增量训练时各个阶段的实时精度。可以看出, 图3展示了4种算法在Airlines数据集上增 DAWE和AUE2在训练前期表现较好,训练后期250 500 750 1 000 1 250 1 500 1 750 2 000 块大小 80 81 82 83 84 85 86 87 88 89 90 分类精度/% Covtype SEA Tree 图 1 不同数据块大小对算法的影响 Fig. 1 Effect of data chunk size 由图 1 可以看出,对于 Covertype 数据集来说 数据块大小为 1 000 是最合适的,即每到来 1 000 个实例将其作为一个数据块来训练一个分类器; 而数据块大小为 500 对于 SEA 数据集来说是最 合适的。由此可以看出,对于不同数据集可能需 要选用不同大小的数据块来达到其最佳性能。 3.2.2 不同方法对比 本文选取的对比方法为 MOA 下的 Accuracy Updated Ensemble (AUE2)、Adaptive Random Forest (ARF)[12]和 Heterogeneous Ensemble Blast (Blast),分 别在 Poker 数据集、Airlines 数据集、SEA 数据集 和 Covertype 数据集上进行了对比实验。表 1 为 几种算法在不同数据集上的平均精度对比。 表 1 算法平均精度对比表 Table 1 Contrast of different algorithms % 算法 ARF AUE2 Blast DAWE Poker 68.28 69.67 67.53 75.83 Airlines 65.69 66.88 67.18 67.12 SEA 89.56 89.24 88.48 89.25 Covertype 84.23 86.27 86.50 86.29 Average 76.94 78.02 77.43 79.62 由表 1 可以看出,在 4 个数据集上本文提出 的算法 DAWE 的平均精度要优于其他 3 个算 法。为了更详细地展示算法在不同数据集上的对 比结果,接下来将分别展示在不同数据集上增量 训练模型时各个阶段测试的精度情况。以下对比 实验默认指定数据块大小为 1 000。 图 2 展示了 4 种算法 (本文提出的算法以及 3 个对比算法) 在 Poker 数据集上增量训练时各个 阶段的实时精度,可以看出,本文提出的算法 DAWE 在 Poker 数据集上要远好于其他 3 个,在表 1 中也 可以看出,在 Poker 数据集上,DAWE 的平均精度 相比其他 3 种算法分别高出 6.16%、7.55% 和 8.30%。 图 3 展示了 4 种算法在 Airlines 数据集上增 量训练时各个阶段的实时精度。虽然从表 1 中 看 Blast 的平均精度最高,但是从图 3 中可以看 出,Blast 之所以平均精度高是因为训练开始精度 高,随着实例的不断增加,其精度呈不断下降趋 势,在 300 000 个实例后,精度最好的算法一直是 DAWE。 图 4 展示了 4 种算法在 SEA 数据集上增量训 练时各个阶段的实时精度。SEA 是突变漂移数据 集,因此为了更好检测并处理概念漂移,将数据 块大小设置为 500。可以看出,本文提出的算法 DAWE 在平均精度上仅次于 APF,并且与 ARF 只 相差 0.31%。 ×105 1 2 3 4 5 6 7 8 已处理实例数 60 62 64 66 68 70 72 74 76 78 80 分类精度/% ADE Blast AUE2 ARF 图 2 4 种算法在 Poker 数据集上分类精度对比 Fig. 2 Accuracy contrast of 4 algorithms on Poker 1 2 3 4 5 已处理实例数 64 65 66 67 68 69 70 分类精度/% DAWE Blast AUE2 ARF ×105 图 3 4 种算法在 Airlines 数据集上分类精度对比 Fig. 3 Accuracy contrast of 4 algorithms on Airlines 1 2 3 4 5 6 7 8 9 10 已处理实例数 87 88 89 90 分类精度/% DAWE Blast AUE2 ARF ×105 图 4 4 种算法在 SEA 数据集上分类精度对比 Fig. 4 Accuracy contrast of 4 algorithms on SEA 图 5 展示了 4 种算法在 Covertype 数据集上 增量训练时各个阶段的实时精度。可以看出, DAWE 和 AUE2 在训练前期表现较好,训练后期 第 1 期 张本才,等:一种多样性和精度加权的数据流集成分类算法 ·183·