正在加载图片...
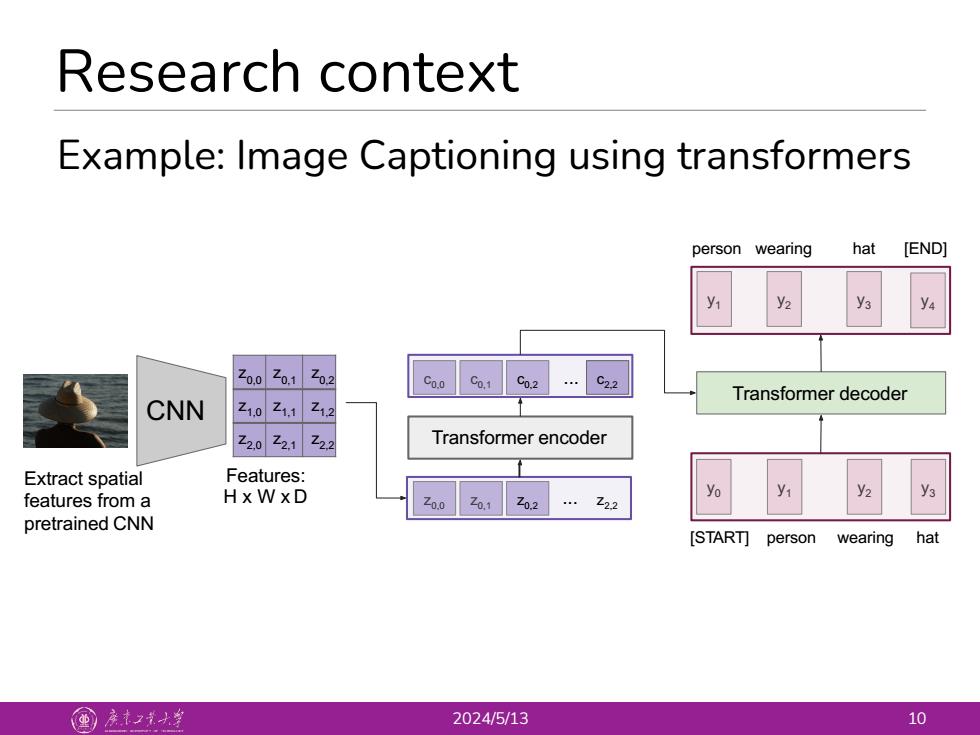
Research context Example:Image Captioning using transformers person wearing hat [END] y1 乙00Z01乙02 Co.0 Co.1 C0.2 C2.2 Z1,0 11Z1.2 Transformer decoder CNN 202122 Transformer encoder Extract spatial Features: features from a HxWXD .222 yo y2 y3 pretrained CNN [START]person wearing hat 国产之小生 2024/5/13 10Research context 2024/5/13 10 Example: Image Captioning using transformers Extract spatial features from a pretrained CNN CNN Features: H x W x D z0,0 z0,1 z0,2 z1,0 z1,1 z1,2 z2,0 z2,1 z2,2 z0,0 z0,1 z0,2 z2,2 ... Transformer encoder c0,1 c0,0 c0,2 c2,2 ... y0 [START] person wearing hat y1 y2 y1 y3 y2 y4 y3 person wearing hat [END] Transformer decoder