正在加载图片...
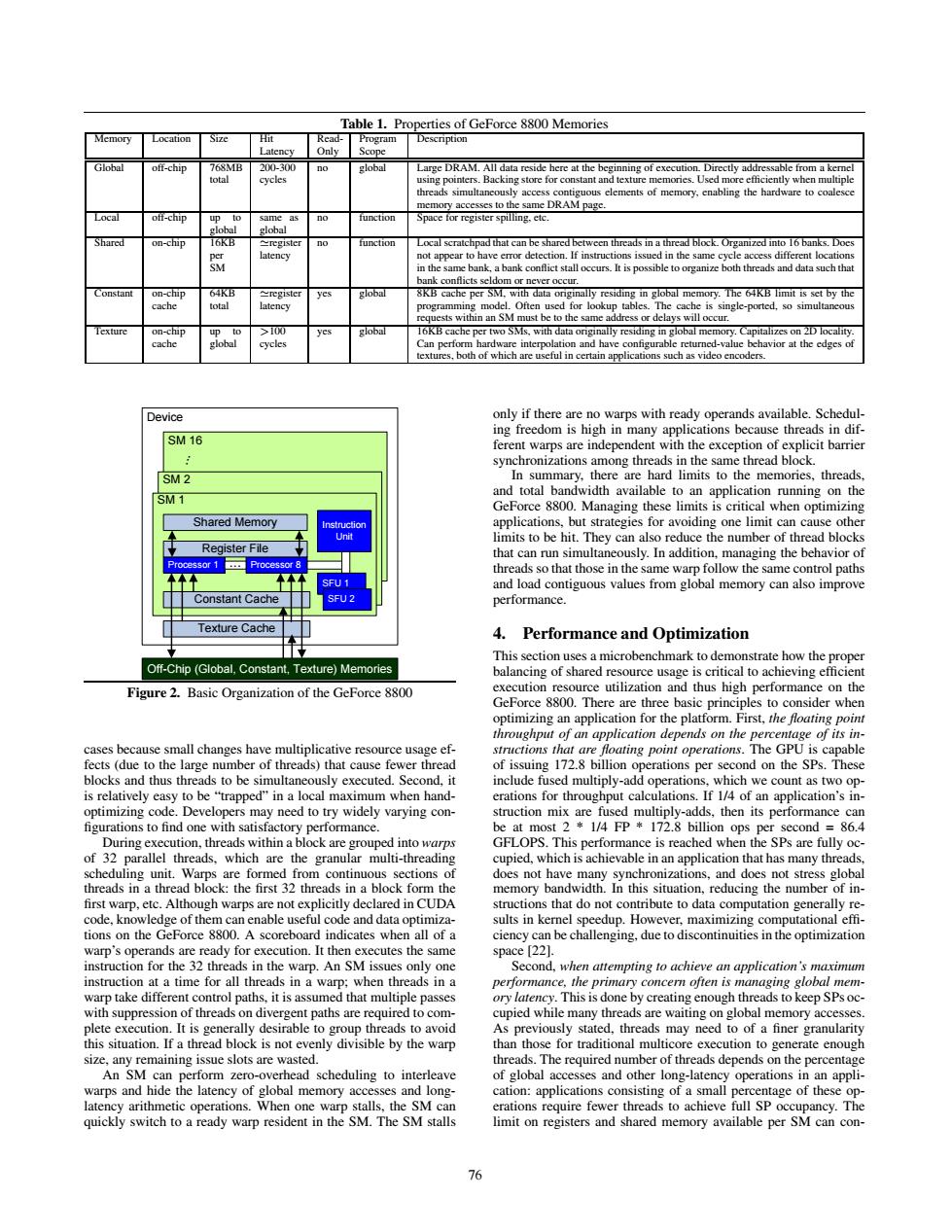
Table 1.Properties of GeForce 8800 Memories Memory Location Size Hit Read- PrograΠm Description Latency Only Scope Global off-chip 768MB 200-300 global Large DRAM.All data reside here at the beginning of execution Directly addressable from a kemel total cycles using pointers.Backing store for constant and texture memories.Used more efficiently when multiple threads simultancously access contiguous elements of memory,enabling the hardware to coalesce memory accesses to the same DRAM page. Local off-chip p to same as no function Space for register spilling.etc. global global Shared on-chip 16KB register function Local scratchpad that can be shared between threads in a thread block Organized into 16 banks.Does per latency not appear to have error detection.If instructions issued in the same cycle access different locations SM in the same bank,a bank conflict stall occurs.It is possible to organize both threads and data such that bank conflicts seldom or never occur. Constant on-chip 64B register yes global 8KB cache per SM,with data originally residing in global memory.The 64KB limit is set by the cache total latency ng model.Often used for lookup tables.The cache is single-ported,so simultaneous requests within an SM must be to the same address or delays will occur. exture on-chip >00 yes global 16KB cache per two SMs,with data originally residing in global memory.Capitalizes on 2D locality cache global cycles Can perform hardware interpolation and have configurable returned-value behavior at the edges of textures,both of which are useful in certain applications such as video encoders. Device only if there are no warps with ready operands available.Schedul- ing freedom is high in many applications because threads in dif- SM 16 ferent warps are independent with the exception of explicit barrier synchronizations among threads in the same thread block. SM2 In summary,there are hard limits to the memories,threads. SM1 and total bandwidth available to an application running on the GeForce 8800.Managing these limits is critical when optimizing Shared Memory instrction applications,but strategies for avoiding one limit can cause other Unit limits to be hit.They can also reduce the number of thread blocks Register File that can run simultaneously.In addition,managing the behavior of Processor 1 Processor 8 threads so that those in the same warp follow the same control paths SFU 1 and load contiguous values from global memory can also improve Constant Cache SFU2 performance. Texture Cache 4.Performance and Optimization This section uses a microbenchmark to demonstrate how the proper Off-Chip (Global,Constant,Texture)Memories balancing of shared resource usage is critical to achieving efficient Figure 2.Basic Organization of the GeForce 8800 execution resource utilization and thus high performance on the GeForce 8800.There are three basic principles to consider when optimizing an application for the platform.First,the floating point throughput of an application depends on the percentage of its in- cases because small changes have multiplicative resource usage ef- structions that are floating point operations.The GPU is capable fects (due to the large number of threads)that cause fewer thread of issuing 172.8 billion operations per second on the SPs.These blocks and thus threads to be simultaneously executed.Second,it include fused multiply-add operations,which we count as two op- is relatively easy to be "trapped"in a local maximum when hand- erations for throughput calculations.If 1/4 of an application's in- optimizing code.Developers may need to try widely varying con- struction mix are fused multiply-adds,then its performance can figurations to find one with satisfactory performance. be at most 2 1/4 FP 172.8 billion ops per second 86.4 During execution,threads within a block are grouped into warps GFLOPS.This performance is reached when the SPs are fully oc- of 32 parallel threads,which are the granular multi-threading cupied,which is achievable in an application that has many threads, scheduling unit.Warps are formed from continuous sections of does not have many synchronizations,and does not stress global threads in a thread block:the first 32 threads in a block form the memory bandwidth.In this situation,reducing the number of in- first warp,etc.Although warps are not explicitly declared in CUDA structions that do not contribute to data computation generally re- code,knowledge of them can enable useful code and data optimiza- sults in kernel speedup.However,maximizing computational effi- tions on the GeForce 8800.A scoreboard indicates when all of a ciency can be challenging,due to discontinuities in the optimization warp's operands are ready for execution.It then executes the same space [221. instruction for the 32 threads in the warp.An SM issues only one Second,when attempting to achieve an application's maximum instruction at a time for all threads in a warp;when threads in a performance,the primary concern often is managing global mem- warp take different control paths,it is assumed that multiple passes ory latency.This is done by creating enough threads to keep SPs oc- with suppression of threads on divergent paths are required to com- cupied while many threads are waiting on global memory accesses. plete execution.It is generally desirable to group threads to avoid As previously stated,threads may need to of a finer granularity this situation.If a thread block is not evenly divisible by the warp than those for traditional multicore execution to generate enough size,any remaining issue slots are wasted. threads.The required number of threads depends on the percentage An SM can perform zero-overhead scheduling to interleave of global accesses and other long-latency operations in an appli- warps and hide the latency of global memory accesses and long- cation:applications consisting of a small percentage of these op- latency arithmetic operations.When one warp stalls,the SM can erations require fewer threads to achieve full SP occupancy.The quickly switch to a ready warp resident in the SM.The SM stalls limit on registers and shared memory available per SM can con- 76Table 1. Properties of GeForce 8800 Memories Memory Location Size Hit Latency ReadOnly Program Scope Description Global off-chip 768MB total 200-300 cycles no global Large DRAM. All data reside here at the beginning of execution. Directly addressable from a kernel using pointers. Backing store for constant and texture memories. Used more efficiently when multiple threads simultaneously access contiguous elements of memory, enabling the hardware to coalesce memory accesses to the same DRAM page. Local off-chip up to global same as global no function Space for register spilling, etc. Shared on-chip 16KB per SM register latency no function Local scratchpad that can be shared between threads in a thread block. Organized into 16 banks. Does not appear to have error detection. If instructions issued in the same cycle access different locations in the same bank, a bank conflict stall occurs. It is possible to organize both threads and data such that bank conflicts seldom or never occur. Constant on-chip cache 64KB total register latency yes global 8KB cache per SM, with data originally residing in global memory. The 64KB limit is set by the programming model. Often used for lookup tables. The cache is single-ported, so simultaneous requests within an SM must be to the same address or delays will occur. Texture on-chip cache up to global >100 cycles yes global 16KB cache per two SMs, with data originally residing in global memory. Capitalizes on 2D locality. Can perform hardware interpolation and have configurable returned-value behavior at the edges of textures, both of which are useful in certain applications such as video encoders. Device SM 16 SM 2 Off-Chip (Global, Constant, Texture) Memories SM 1 Texture Cache Constant Cache Processor 1 Processor 8 Register File Shared Memory Instruction Unit ... ... SFU 1 SFU 2 Figure 2. Basic Organization of the GeForce 8800 cases because small changes have multiplicative resource usage effects (due to the large number of threads) that cause fewer thread blocks and thus threads to be simultaneously executed. Second, it is relatively easy to be “trapped” in a local maximum when handoptimizing code. Developers may need to try widely varying con- figurations to find one with satisfactory performance. During execution, threads within a block are grouped into warps of 32 parallel threads, which are the granular multi-threading scheduling unit. Warps are formed from continuous sections of threads in a thread block: the first 32 threads in a block form the first warp, etc. Although warps are not explicitly declared in CUDA code, knowledge of them can enable useful code and data optimizations on the GeForce 8800. A scoreboard indicates when all of a warp’s operands are ready for execution. It then executes the same instruction for the 32 threads in the warp. An SM issues only one instruction at a time for all threads in a warp; when threads in a warp take different control paths, it is assumed that multiple passes with suppression of threads on divergent paths are required to complete execution. It is generally desirable to group threads to avoid this situation. If a thread block is not evenly divisible by the warp size, any remaining issue slots are wasted. An SM can perform zero-overhead scheduling to interleave warps and hide the latency of global memory accesses and longlatency arithmetic operations. When one warp stalls, the SM can quickly switch to a ready warp resident in the SM. The SM stalls only if there are no warps with ready operands available. Scheduling freedom is high in many applications because threads in different warps are independent with the exception of explicit barrier synchronizations among threads in the same thread block. In summary, there are hard limits to the memories, threads, and total bandwidth available to an application running on the GeForce 8800. Managing these limits is critical when optimizing applications, but strategies for avoiding one limit can cause other limits to be hit. They can also reduce the number of thread blocks that can run simultaneously. In addition, managing the behavior of threads so that those in the same warp follow the same control paths and load contiguous values from global memory can also improve performance. 4. Performance and Optimization This section uses a microbenchmark to demonstrate how the proper balancing of shared resource usage is critical to achieving efficient execution resource utilization and thus high performance on the GeForce 8800. There are three basic principles to consider when optimizing an application for the platform. First, the floating point throughput of an application depends on the percentage of its instructions that are floating point operations. The GPU is capable of issuing 172.8 billion operations per second on the SPs. These include fused multiply-add operations, which we count as two operations for throughput calculations. If 1/4 of an application’s instruction mix are fused multiply-adds, then its performance can be at most 2 * 1/4 FP * 172.8 billion ops per second = 86.4 GFLOPS. This performance is reached when the SPs are fully occupied, which is achievable in an application that has many threads, does not have many synchronizations, and does not stress global memory bandwidth. In this situation, reducing the number of instructions that do not contribute to data computation generally results in kernel speedup. However, maximizing computational effi- ciency can be challenging, due to discontinuities in the optimization space [22]. Second, when attempting to achieve an application’s maximum performance, the primary concern often is managing global memory latency. This is done by creating enough threads to keep SPs occupied while many threads are waiting on global memory accesses. As previously stated, threads may need to of a finer granularity than those for traditional multicore execution to generate enough threads. The required number of threads depends on the percentage of global accesses and other long-latency operations in an application: applications consisting of a small percentage of these operations require fewer threads to achieve full SP occupancy. The limit on registers and shared memory available per SM can con- 76��