正在加载图片...
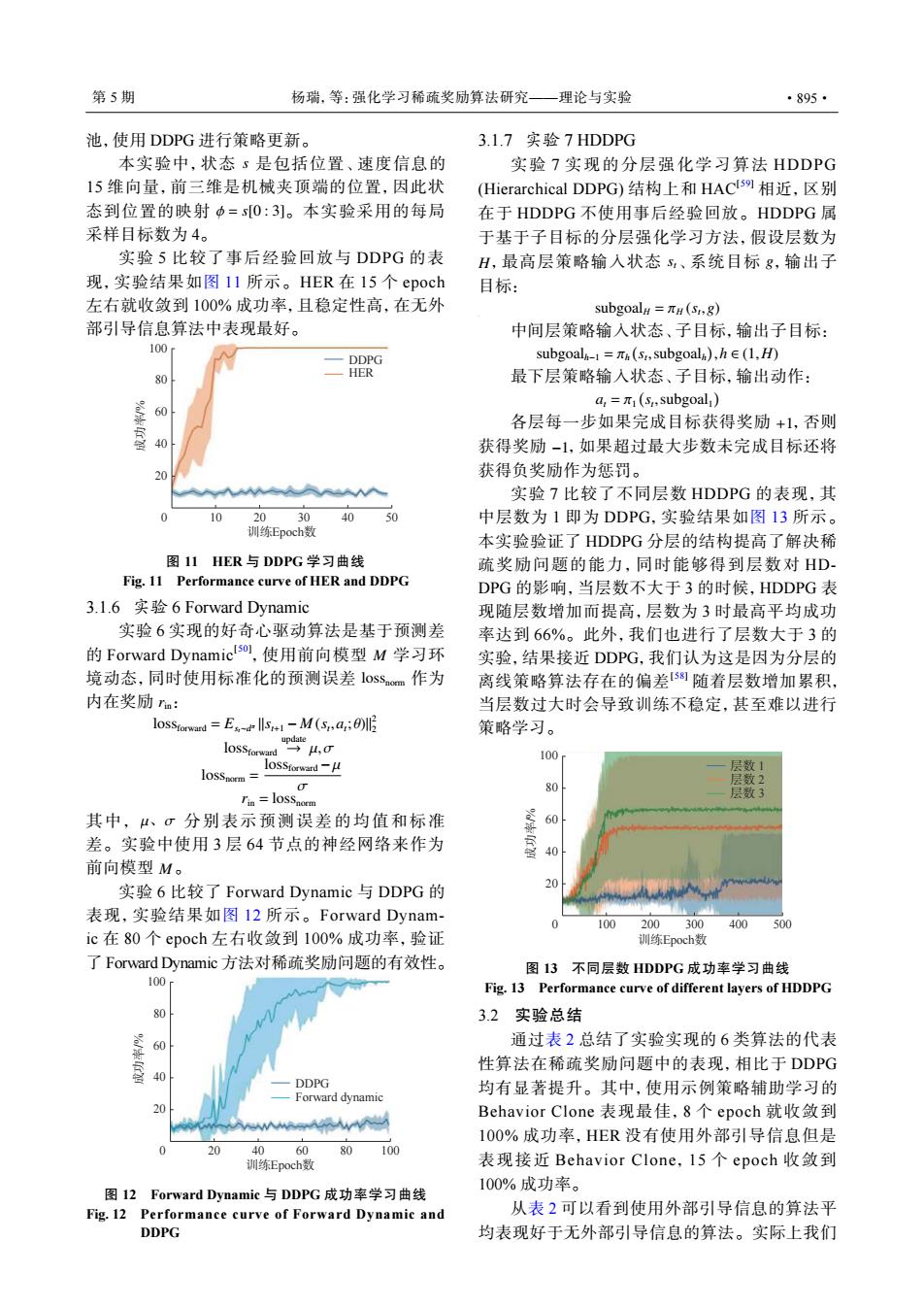
第5期 杨瑞,等:强化学习稀疏奖励算法研究一理论与实验 ·895· 池,使用DDPG进行策略更新。 3.1.7实验7 HDDPG 本实验中,状态了是包括位置、速度信息的 实验7实现的分层强化学习算法HDDPG 15维向量,前三维是机械夹顶端的位置,因此状 Hierarchical DDPG)结构上和HACs9相近,区别 态到位置的映射中=s0:3]。本实验采用的每局 在于HDDPG不使用事后经验回放。HDDPG属 采样目标数为4。 于基于子目标的分层强化学习方法,假设层数为 实验5比较了事后经验回放与DDPG的表 H,最高层策略输入状态s、系统目标g,输出子 现,实验结果如图I1所示。HER在I5个epoch 目标: 左右就收敛到100%成功率,且稳定性高,在无外 subgoal#=πH(S,8) 部引导信息算法中表现最好。 中间层策略输入状态、子目标,输出子目标: 100 DDPG subgoal-l=πa(s,subgoal),h∈(1,H) 80 HER 最下层策略输入状态、子目标,输出动作: a,=π1(s,subgoal) 60 各层每一步如果完成目标获得奖励+1,否则 获得奖励-1,如果超过最大步数未完成目标还将 20 获得负奖励作为惩罚。 A 实验7比较了不同层数HDDPG的表现,其 0 10 2030 40 50 中层数为1即为DDPG,实验结果如图13所示。 训练Epoch数 本实验验证了HDDPG分层的结构提高了解决稀 图11HIER与DDPG学习曲线 疏奖励问题的能力,同时能够得到层数对HD Fig.11 Performance curve of HER and DDPG DPG的影响,当层数不大于3的时候,HDDPG表 3.1.6实验6 Forward Dynamic 现随层数增加而提高,层数为3时最高平均成功 实验6实现的好奇心驱动算法是基于预测差 率达到66%。此外,我们也进行了层数大于3的 的Forward Dynamictso],使用前向模型M学习环 实验,结果接近DDPG,我们认为这是因为分层的 境动态,同时使用标准化的预测误差l0SSom作为 离线策略算法存在的偏差58随着层数增加累积, 内在奖励ra: 当层数过大时会导致训练不稳定,甚至难以进行 losStorwand =Es-M(a;0) yμ,g 策略学习。 l0SStorward 100 loSStorward-M 层数1 lOSSnorm= 80 层数2 Tin loSSnorm 层数3 其中,μ、σ分别表示预测误差的均值和标准 差。实验中使用3层64节点的神经网络来作为 % 前向模型M。 实验6比较了Forward Dynamic与DDPG的 表现,实验结果如图12所示。Forward Dynam- 100 200300 400500 ic在80个epoch左右收敛到100%成功率,验证 训练Epoch数 了Forward Dynamic方法对稀疏奖励问题的有效性。 图13不同层数HDDPG成功率学习曲线 100 Fig.13 Performance curve of different layers of HDDPG 80 3.2实验总结 60 通过表2总结了实验实现的6类算法的代表 性算法在稀疏奖励问题中的表现,相比于DDPG 40 DDPG 均有显著提升。其中,使用示例策略辅助学习的 Forward dynamic 20 mwww Behavior Clone表现最佳,8个epoch就收敛到 100%成功率,HER没有使用外部引导信息但是 20 4060 80100 训练Epoch数 表现接近Behavior Clone,l5个epoch收敛到 100%成功率。 图12 Forward Dynamic与DDPG成功率学习曲线 Fig.12 Performance curve of Forward Dynamic and 从表2可以看到使用外部引导信息的算法平 DDPG 均表现好于无外部引导信息的算法。实际上我们池,使用 DDPG 进行策略更新。 s ϕ = s[0 : 3] 本实验中,状态 是包括位置、速度信息的 15 维向量,前三维是机械夹顶端的位置,因此状 态到位置的映射 。本实验采用的每局 采样目标数为 4。 实验 5 比较了事后经验回放与 DDPG 的表 现,实验结果如图 11 所示。HER 在 15 个 epoch 左右就收敛到 100% 成功率,且稳定性高,在无外 部引导信息算法中表现最好。 100 DDPG HER 80 60 40 20 0 10 20 30 训练Epoch数 成功率/% 40 50 图 11 HER 与 DDPG 学习曲线 Fig. 11 Performance curve of HER and DDPG 3.1.6 实验 6 Forward Dynamic M lossnorm rin 实验 6 实现的好奇心驱动算法是基于预测差 的 Forward Dynamic[ 50] ,使用前向模型 学习环 境动态,同时使用标准化的预测误差 作为 内在奖励 : lossforward = Est∼d π ∥st+1 − M (st ,at ; θ)∥ 2 2 lossforward update → µ,σ lossnorm = lossforward −µ σ rin = lossnorm µ、σ M 其中, 分别表示预测误差的均值和标准 差。实验中使用 3 层 64 节点的神经网络来作为 前向模型 。 实验 6 比较了 Forward Dynamic 与 DDPG 的 表现,实验结果如图 12 所示。Forward Dynamic 在 80 个 epoch 左右收敛到 100% 成功率,验证 了 Forward Dynamic 方法对稀疏奖励问题的有效性。 DDPG Forward dynamic 100 80 60 40 20 0 20 40 60 训练Epoch数 成功率/% 80 100 图 12 Forward Dynamic 与 DDPG 成功率学习曲线 Fig. 12 Performance curve of Forward Dynamic and DDPG 3.1.7 实验 7 HDDPG H st g 实验 7 实现的分层强化学习算法 HDDPG (Hierarchical DDPG) 结构上和 HAC[59] 相近,区别 在于 HDDPG 不使用事后经验回放。HDDPG 属 于基于子目标的分层强化学习方法,假设层数为 ,最高层策略输入状态 、系统目标 ,输出子 目标: subgoalH = πH (st ,g) 中间层策略输入状态、子目标,输出子目标: subgoalh−1 = πh ( st ,subgoalh ) ,h ∈ (1,H) 最下层策略输入状态、子目标,输出动作: at = π1 ( st ,subgoal1 ) +1 −1 各层每一步如果完成目标获得奖励 ,否则 获得奖励 ,如果超过最大步数未完成目标还将 获得负奖励作为惩罚。 实验 7 比较了不同层数 HDDPG 的表现,其 中层数为 1 即为 DDPG,实验结果如图 13 所示。 本实验验证了 HDDPG 分层的结构提高了解决稀 疏奖励问题的能力,同时能够得到层数对 HDDPG 的影响,当层数不大于 3 的时候,HDDPG 表 现随层数增加而提高,层数为 3 时最高平均成功 率达到 66%。此外,我们也进行了层数大于 3 的 实验,结果接近 DDPG,我们认为这是因为分层的 离线策略算法存在的偏差[ 58] 随着层数增加累积, 当层数过大时会导致训练不稳定,甚至难以进行 策略学习。 层数 1 层数 2 层数 3 100 80 60 40 20 0 100 200 300 训练Epoch数 成功率/% 400 500 图 13 不同层数 HDDPG 成功率学习曲线 Fig. 13 Performance curve of different layers of HDDPG 3.2 实验总结 通过表 2 总结了实验实现的 6 类算法的代表 性算法在稀疏奖励问题中的表现,相比于 DDPG 均有显著提升。其中,使用示例策略辅助学习的 Behavior Clone 表现最佳,8 个 epoch 就收敛到 100% 成功率,HER 没有使用外部引导信息但是 表现接近 Behavior Clone,15 个 epoch 收敛到 100% 成功率。 从表 2 可以看到使用外部引导信息的算法平 均表现好于无外部引导信息的算法。实际上我们 第 5 期 杨瑞,等:强化学习稀疏奖励算法研究——理论与实验 ·895·