正在加载图片...
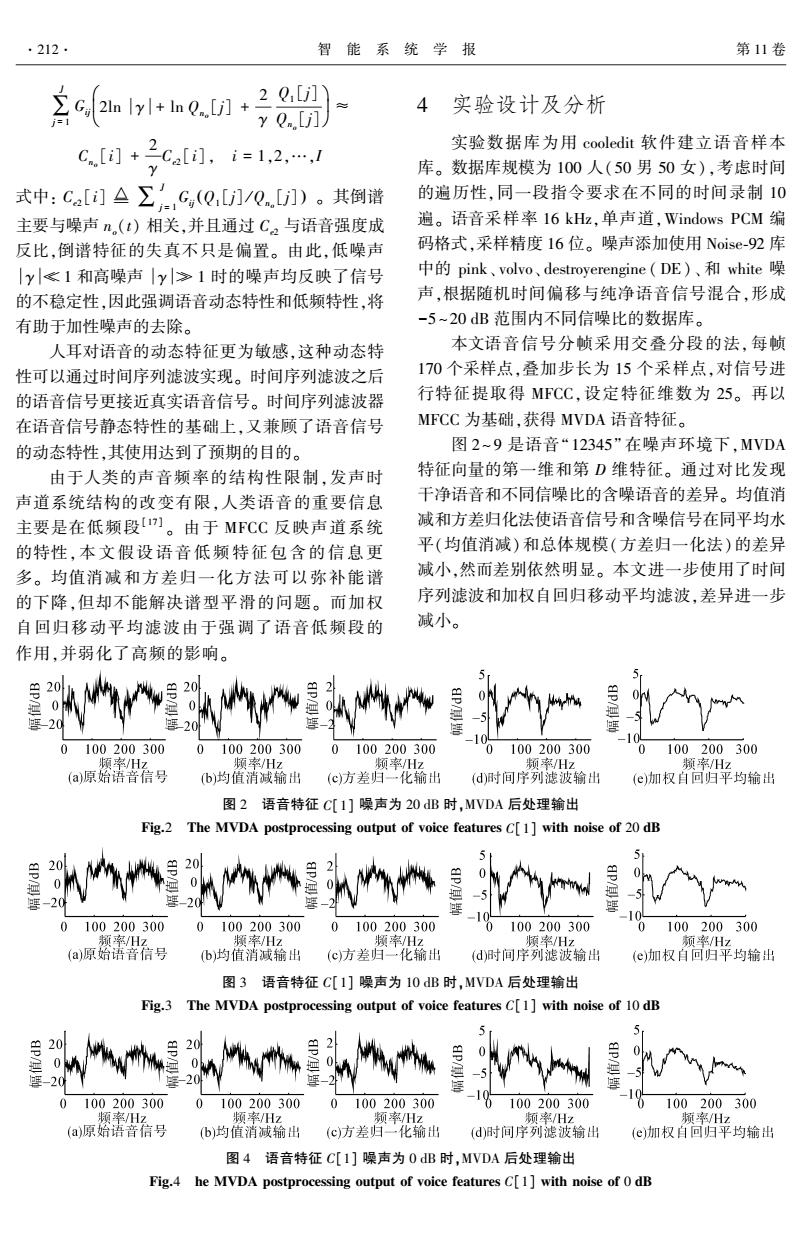
.212. 智能系统学报 第11卷 含c1+h.in+8 4 *y Q..[j]) 实验设计及分析 6.+2ca.ie1,21 实验数据库为用cooledit软件建立语音样本 库。数据库规模为100人(50男50女),考虑时间 式中:Ca[i]△∑c,(Q,j]/J)。其倒谱 的遍历性,同一段指令要求在不同的时间录制10 主要与噪声n.(t)相关,并且通过C2与语音强度成 遍。语音采样率16kHz,单声道,Windows PCM编 反比,倒谱特征的失真不只是偏置。由此,低噪声 码格式,采样精度16位。噪声添加使用Noise-92库 |y≤1和高噪声|y≥1时的噪声均反映了信号 中的pink、volvo、destroyerengine(DE)、和white噪 的不稳定性,因此强调语音动态特性和低频特性,将 声,根据随机时间偏移与纯净语音信号混合,形成 有助于加性噪声的去除。 -5~20dB范围内不同信噪比的数据库。 人耳对语音的动态特征更为敏感,这种动态特 本文语音信号分帧采用交叠分段的法,每帧 性可以通过时间序列滤波实现。时间序列滤波之后 170个采样点,叠加步长为15个采样点,对信号进 的语音信号更接近真实语音信号。时间序列滤波器 行特征提取得MFCC,设定特征维数为25。再以 在语音信号静态特性的基础上,又兼顾了语音信号 MFCC为基础,获得MVDA语音特征。 的动态特性,其使用达到了预期的目的。 图2~9是语音“12345”在噪声环境下,MVDA 由于人类的声音频率的结构性限制,发声时 特征向量的第一维和第D维特征。通过对比发现 声道系统结构的改变有限,人类语音的重要信息 干净语音和不同信噪比的含噪语音的差异。均值消 主要是在低频段1。由于MFCC反映声道系统 减和方差归化法使语音信号和含噪信号在同平均水 的特性,本文假设语音低频特征包含的信息更 平(均值消减)和总体规模(方差归一化法)的差异 多。均值消减和方差归一化方法可以弥补能谱 减小,然而差别依然明显。本文进一步使用了时间 的下降,但却不能解决谱型平滑的问题。而加权 序列滤波和加权自回归移动平均滤波,差异进一步 自回归移动平均滤波由于强调了语音低频段的 减小。 作用,并弱化了高频的影响。 20 20 0 100200300 0 100200300 0 100200300 100200300 100200300 頫率/Hz 频率Hz 频率Hz 频率Hz 频率/Hz (a)原始语音信号 (b)均值消减输出 (c方差归一化输出 (d)时间序列滤波输出 (e)加权自回归平均输出 图2语音特征C[1]噪声为20dB时,MVDA后处理输出 Fig.2 The MVDA postprocessing output of voice features C[1]with noise of 20 dB 20 920 0100200300 0100200300 0100200300 100200300 0100200300 、频率/Hz 顺率Hz 频率Hz 頫案Hz 频率/Hz (a)原始语音信号 b)均值消减输出 (c方差归一·化输出 (d)时间序列滤波输出 (e)加权自回归平均输出 图3语音特征C[1]噪声为10dB时,MVDA后处理输出 Fig.3 The MVDA postprocessing output of voice features C[1]with noise of 10 dB 5 ap/ m20 0 蟹-20 -20 0 100200300 0 100200300 100200300 100200300 100200300 频率Hz 频率Hz 频率/Hz 频率/Hz 频率/Hz (a)原始语音信号 (b)均值消减输出 (c)方差归一化输出 (d)时间序列滤波输出 (e)加权自回归平均输出 图4语音特征C[1]噪声为0dB时,MVDA后处理输出 Fig.4 he MVDA postprocessing output of voice features C[1]with noise of 0 dB∑ J j = 1 Gij 2ln γ + ln Qno [j] + 2 γ Q1 [j] Qno [j] æ è ç ö ø ÷ ≈ Cno [i] + 2 γ Ce2 [i], i = 1,2,…,I 式中: Ce2 [i] ∑ J j = 1 Gij Q1 [j] / Qno ( [j] ) 。 其倒谱 主要与噪声 no(t) 相关,并且通过 Ce2 与语音强度成 反比,倒谱特征的失真不只是偏置。 由此,低噪声 γ ≪ 1 和高噪声 γ ≫ 1 时的噪声均反映了信号 的不稳定性,因此强调语音动态特性和低频特性,将 有助于加性噪声的去除。 人耳对语音的动态特征更为敏感,这种动态特 性可以通过时间序列滤波实现。 时间序列滤波之后 的语音信号更接近真实语音信号。 时间序列滤波器 在语音信号静态特性的基础上,又兼顾了语音信号 的动态特性,其使用达到了预期的目的。 由于人类的声音频率的结构性限制,发声时 声道系统结构的改变有限,人类语音的重要信息 主要是在低频段[ 17] 。 由于 MFCC 反映声道系统 的特性,本文假设语音低频特征包 含 的 信 息 更 多。 均值消减和方差归一化方法可以弥补能谱 的下降,但却不能解决谱型平滑的问题。 而加权 自回归移动平均滤波由于强调了语音低频段的 作用,并弱化了高频的影响。 4 实验设计及分析 实验数据库为用 cooledit 软件建立语音样本 库。 数据库规模为 100 人(50 男 50 女),考虑时间 的遍历性,同一段指令要求在不同的时间录制 10 遍。 语音采样率 16 kHz,单声道,Windows PCM 编 码格式,采样精度 16 位。 噪声添加使用 Noise⁃92 库 中的 pink、 volvo、 destroyerengine ( DE)、 和 white 噪 声,根据随机时间偏移与纯净语音信号混合,形成 -5~20 dB 范围内不同信噪比的数据库。 本文语音信号分帧采用交叠分段的法,每帧 170 个采样点,叠加步长为 15 个采样点,对信号进 行特征提取得 MFCC,设定特征维数为 25。 再以 MFCC 为基础,获得 MVDA 语音特征。 图 2~ 9 是语音“12345” 在噪声环境下,MVDA 特征向量的第一维和第 D 维特征。 通过对比发现 干净语音和不同信噪比的含噪语音的差异。 均值消 减和方差归化法使语音信号和含噪信号在同平均水 平(均值消减)和总体规模(方差归一化法)的差异 减小,然而差别依然明显。 本文进一步使用了时间 序列滤波和加权自回归移动平均滤波,差异进一步 减小。 图 2 语音特征 C[1] 噪声为 20 dB 时,MVDA 后处理输出 Fig.2 The MVDA postprocessing output of voice features C[1] with noise of 20 dB 图 3 语音特征 C[1] 噪声为 10 dB 时,MVDA 后处理输出 Fig.3 The MVDA postprocessing output of voice features C[1] with noise of 10 dB 图 4 语音特征 C[1] 噪声为 0 dB 时,MVDA 后处理输出 Fig.4 he MVDA postprocessing output of voice features C[1] with noise of 0 dB ·212· 智 能 系 统 学 报 第 11 卷