正在加载图片...
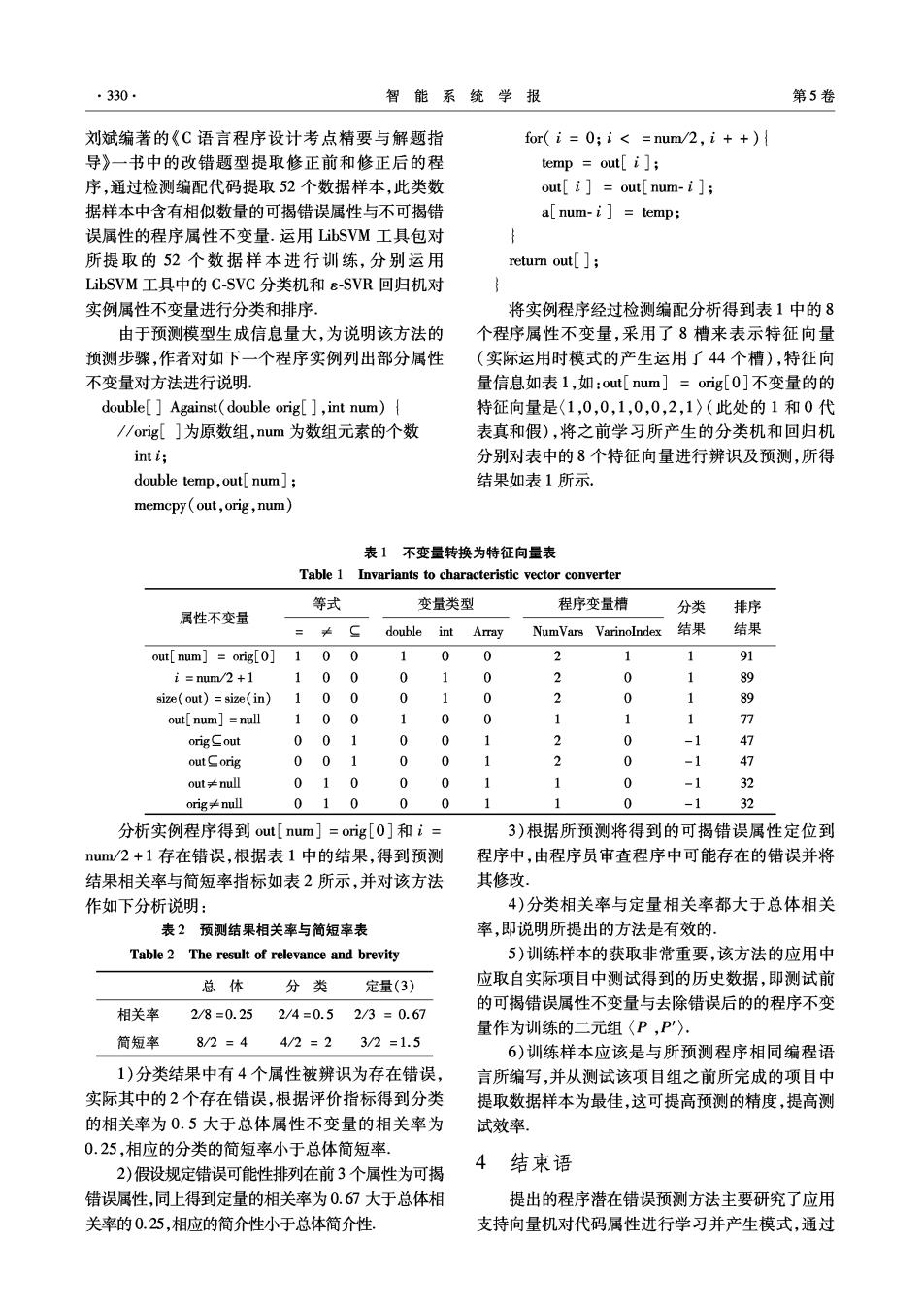
330 智能系统学报 第5卷 刘斌编著的《C语言程序设计考点精要与解题指 for(i=0;i<=num/2,i++) 导》一书中的改错题型提取修正前和修正后的程 temp =out[i]; 序,通过检测编配代码提取52个数据样本,此类数 out[i]out[num-i]; 据样本中含有相似数量的可揭错误属性与不可揭错 a[num-i]temp; 误属性的程序属性不变量.运用LibSVM工具包对 所提取的52个数据样本进行训练,分别运用 return out[] LibSVM工具中的C-SVC分类机和ε-SVR回归机对 实例属性不变量进行分类和排序. 将实例程序经过检测编配分析得到表1中的8 由于预测模型生成信息量大,为说明该方法的 个程序属性不变量,采用了8槽来表示特征向量 预测步骤,作者对如下一个程序实例列出部分属性 (实际运用时模式的产生运用了44个槽),特征向 不变量对方法进行说明. 量信息如表1,如:out[num]=oig[0]不变量的的 double[Against(double orig[]int num) 特征向量是(1,0,0,1,0,0,2,1〉(此处的1和0代 /orig[]为原数组,num为数组元素的个数 表真和假),将之前学习所产生的分类机和回归机 int i; 分别对表中的8个特征向量进行辨识及预测,所得 double temp,out[num]; 结果如表1所示. memcpy out,orig,num) 表1不变量转换为特征向量表 Table 1 Invariants to characteristic vector converter 等式 变量类型 程序变量槽 属性不变量 分类 排序 =≠ double int Array NumVars Varinolndex 结果 结果 out[num]orig[0]1 00 1 0 0 1 1 91 i=num/2+1 100 0 1 0 2 0 89 size(out)=size(in) 100 0 1 0 3 0 1 89 out[num =null 100 1 0 0 1 77 orig二out 001 0 0 1 2 0 -1 47 out Corig 00 1 0 0 1 2 0 -1 47 out≠null 010 0 0 1 0 -1 32 orig≠nu 010 0 0 1 0 -1 32 分析实例程序得到out[num]=orig[O]和i= 3)根据所预测将得到的可揭错误属性定位到 num/2+1存在错误,根据表1中的结果,得到预测 程序中,由程序员审查程序中可能存在的错误并将 结果相关率与简短率指标如表2所示,并对该方法 其修改。 作如下分析说明: 4)分类相关率与定量相关率都大于总体相关 表2预测结果相关率与简短率表 率,即说明所提出的方法是有效的、 Table 2 The result of relevance and brevity 5)训练样本的获取非常重要,该方法的应用中 总体 分类 定量(3) 应取自实际项目中测试得到的历史数据,即测试前 相关率 2/8=0.252/4=0.52/3=0.67 的可揭错误属性不变量与去除错误后的的程序不变 量作为训练的二元组〈P,P). 简短率 8/2=44/2=2 3/2=1.5 6)训练样本应该是与所预测程序相同编程语 1)分类结果中有4个属性被辨识为存在错误, 言所编写,并从测试该项目组之前所完成的项目中 实际其中的2个存在错误,根据评价指标得到分类 提取数据样本为最佳,这可提高预测的精度,提高测 的相关率为0.5大于总体属性不变量的相关率为 试效率, 0.25,相应的分类的简短率小于总体简短率。 2)假设规定错误可能性排列在前3个属性为可揭 4结束语 错误属性,同上得到定量的相关率为0.67大于总体相 提出的程序潜在错误预测方法主要研究了应用 关率的0.25,相应的简介性小于总体简介性. 支持向量机对代码属性进行学习并产生模式,通过