正在加载图片...
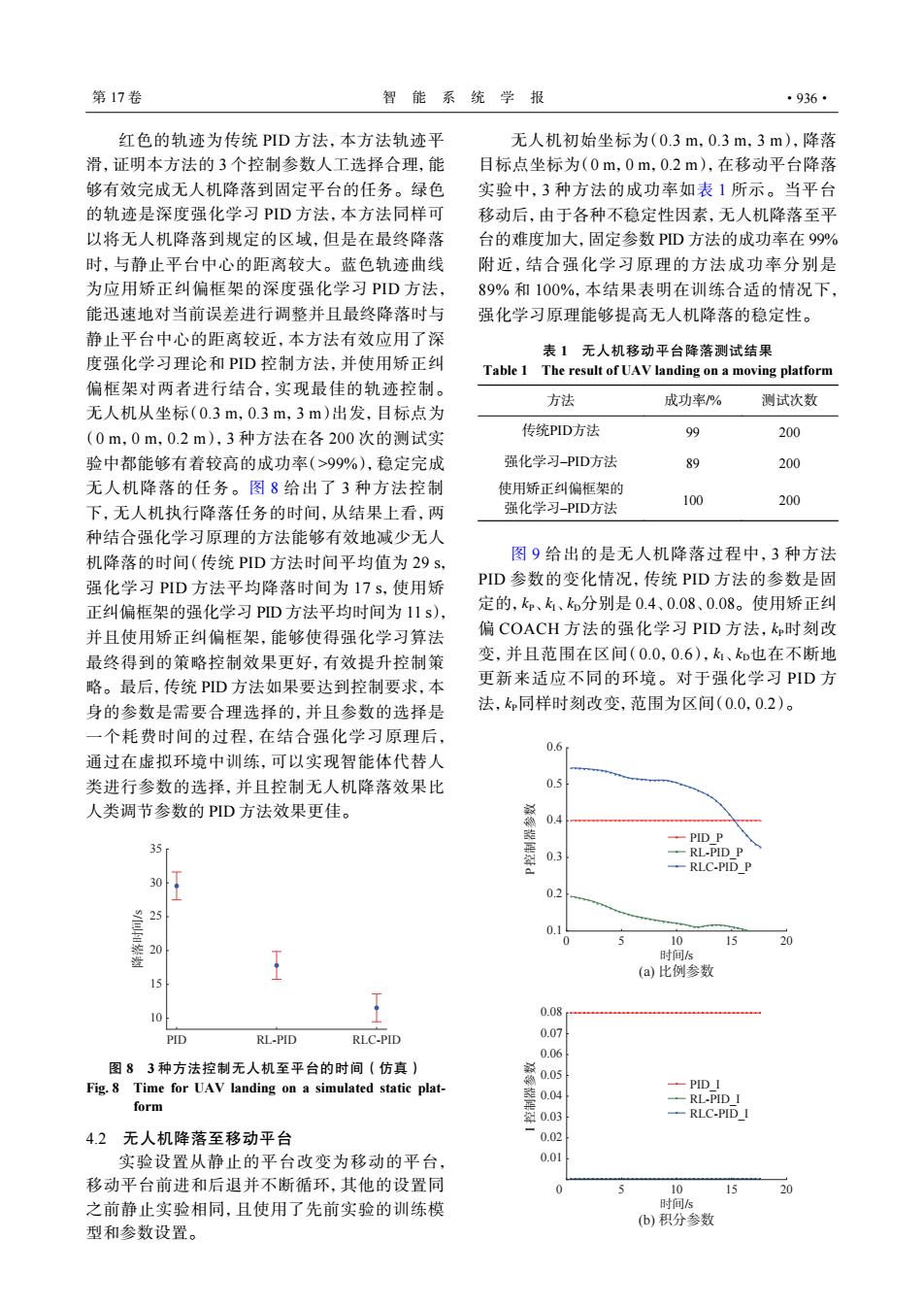
第17卷 智能系统学报 ·936· 红色的轨迹为传统PID方法,本方法轨迹平 无人机初始坐标为(0.3m,0.3m,3m),降落 滑,证明本方法的3个控制参数人工选择合理,能 目标点坐标为(0m,0m,0.2m),在移动平台降落 够有效完成无人机降落到固定平台的任务。绿色 实验中,3种方法的成功率如表1所示。当平台 的轨迹是深度强化学习PD方法,本方法同样可 移动后,由于各种不稳定性因素,无人机降落至平 以将无人机降落到规定的区域,但是在最终降落 台的难度加大,固定参数PD方法的成功率在99% 时,与静止平台中心的距离较大。蓝色轨迹曲线 附近,结合强化学习原理的方法成功率分别是 为应用矫正纠偏框架的深度强化学习PID方法, 89%和100%,本结果表明在训练合适的情况下, 能迅速地对当前误差进行调整并且最终降落时与 强化学习原理能够提高无人机降落的稳定性。 静止平台中心的距离较近,本方法有效应用了深 表1无人机移动平台降落测试结果 度强化学习理论和PD控制方法,并使用矫正纠 Table 1 The result of UAV landing on a moving platform 偏框架对两者进行结合,实现最佳的轨迹控制。 方法 成功率% 测试次数 无人机从坐标(0.3m,0.3m,3m)出发,目标点为 (0m,0m,0.2m),3种方法在各200次的测试实 传统PID方法 99 200 验中都能够有着较高的成功率(>99%),稳定完成 强化学习-PID方法 89 200 无人机降落的任务。图8给出了3种方法控制 使用矫正纠偏框架的 100 200 下,无人机执行降落任务的时间,从结果上看,两 强化学习-PID方法 种结合强化学习原理的方法能够有效地减少无人 机降落的时间(传统PD方法时间平均值为29s, 图9给出的是无人机降落过程中,3种方法 强化学习PID方法平均降落时间为17s,使用矫 PD参数的变化情况,传统PID方法的参数是固 正纠偏框架的强化学习PD方法平均时间为11s), 定的,k、k、ko分别是0.4、0.08、0.08。使用矫正纠 并且使用矫正纠偏框架,能够使得强化学习算法 偏COACH方法的强化学习PID方法,k时刻改 最终得到的策略控制效果更好,有效提升控制策 变,并且范围在区间(0.0,0.6),k、k也在不断地 略。最后,传统PD方法如果要达到控制要求,本 更新来适应不同的环境。对于强化学习PID方 身的参数是需要合理选择的,并且参数的选择是 法,k同样时刻改变,范围为区间(0.0,02)。 一个耗费时间的过程,在结合强化学习原理后, 0.6 通过在虚拟环境中训练,可以实现智能体代替人 类进行参数的选择,并且控制无人机降落效果比 0.5 人类调节参数的PID方法效果更佳。 0.4 PID P 35 0.3 --RL-PID P -RLC-PID P % 0.2 0.1 0 5 10 15 20 时间s (a)比例参数 15 10 0.08 PID RL-PID RLC-PID 0.07 0.06 图83种方法控制无人机至平台的时间(仿真) Fig.8 Time for UAV landing on a simulated static plat- 著05 -PID I form -RL-PID I -RLC-PID I 4.2无人机降落至移动平台 0.02 实验设置从静止的平台改变为移动的平台, 0.01 移动平台前进和后退并不断循环,其他的设置同 10 15 20 之前静止实验相同,且使用了先前实验的训练模 时间s b)积分参数 型和参数设置。红色的轨迹为传统 PID 方法,本方法轨迹平 滑,证明本方法的 3 个控制参数人工选择合理,能 够有效完成无人机降落到固定平台的任务。绿色 的轨迹是深度强化学习 PID 方法,本方法同样可 以将无人机降落到规定的区域,但是在最终降落 时,与静止平台中心的距离较大。蓝色轨迹曲线 为应用矫正纠偏框架的深度强化学习 PID 方法, 能迅速地对当前误差进行调整并且最终降落时与 静止平台中心的距离较近,本方法有效应用了深 度强化学习理论和 PID 控制方法,并使用矫正纠 偏框架对两者进行结合,实现最佳的轨迹控制。 无人机从坐标(0.3 m,0.3 m,3 m)出发,目标点为 (0 m,0 m,0.2 m),3 种方法在各 200 次的测试实 验中都能够有着较高的成功率(>99%),稳定完成 无人机降落的任务。图 8 给出了 3 种方法控制 下,无人机执行降落任务的时间,从结果上看,两 种结合强化学习原理的方法能够有效地减少无人 机降落的时间(传统 PID 方法时间平均值为 29 s, 强化学习 PID 方法平均降落时间为 17 s,使用矫 正纠偏框架的强化学习 PID 方法平均时间为 11 s), 并且使用矫正纠偏框架,能够使得强化学习算法 最终得到的策略控制效果更好,有效提升控制策 略。最后,传统 PID 方法如果要达到控制要求,本 身的参数是需要合理选择的,并且参数的选择是 一个耗费时间的过程,在结合强化学习原理后, 通过在虚拟环境中训练,可以实现智能体代替人 类进行参数的选择,并且控制无人机降落效果比 人类调节参数的 PID 方法效果更佳。 PID RL-PID 降落时间/s RLC-PID 10 15 20 25 30 35 图 8 3 种方法控制无人机至平台的时间(仿真) Fig. 8 Time for UAV landing on a simulated static platform 4.2 无人机降落至移动平台 实验设置从静止的平台改变为移动的平台, 移动平台前进和后退并不断循环,其他的设置同 之前静止实验相同,且使用了先前实验的训练模 型和参数设置。 无人机初始坐标为(0.3 m,0.3 m,3 m),降落 目标点坐标为(0 m,0 m,0.2 m),在移动平台降落 实验中,3 种方法的成功率如表 1 所示。当平台 移动后,由于各种不稳定性因素,无人机降落至平 台的难度加大,固定参数 PID 方法的成功率在 99% 附近,结合强化学习原理的方法成功率分别是 89% 和 100%,本结果表明在训练合适的情况下, 强化学习原理能够提高无人机降落的稳定性。 表 1 无人机移动平台降落测试结果 Table 1 The result of UAV landing on a moving platform 方法 成功率/% 测试次数 传统PID方法 99 200 强化学习–PID方法 89 200 使用矫正纠偏框架的 强化学习–PID方法 100 200 kP kI kD kP kI kD kP 图 9 给出的是无人机降落过程中,3 种方法 PID 参数的变化情况,传统 PID 方法的参数是固 定的, 、 、 分别是 0.4、0.08、0.08。使用矫正纠 偏 COACH 方法的强化学习 PID 方法, 时刻改 变,并且范围在区间(0.0,0.6), 、 也在不断地 更新来适应不同的环境。对于强化学习 PID 方 法, 同样时刻改变,范围为区间(0.0,0.2)。 D 控制器参数 时间/s (c) 微分参数 PID_D RL-PID_D RLC-PID_D 5 10 I 控制器参数 时间/s (b) 积分参数 15 20 20 0.01 0 0.02 0.03 0.05 0.06 0.04 0.07 0.08 PID_I RL-PID_I RLC-PID_I 0 5 10 P 控制器参数 时间/s (a) 比例参数 15 0.1 0.2 0.3 0.4 0.5 0.6 PID_P RL-PID_P RLC-PID_P 第 17 卷 智 能 系 统 学 报 ·936·