正在加载图片...
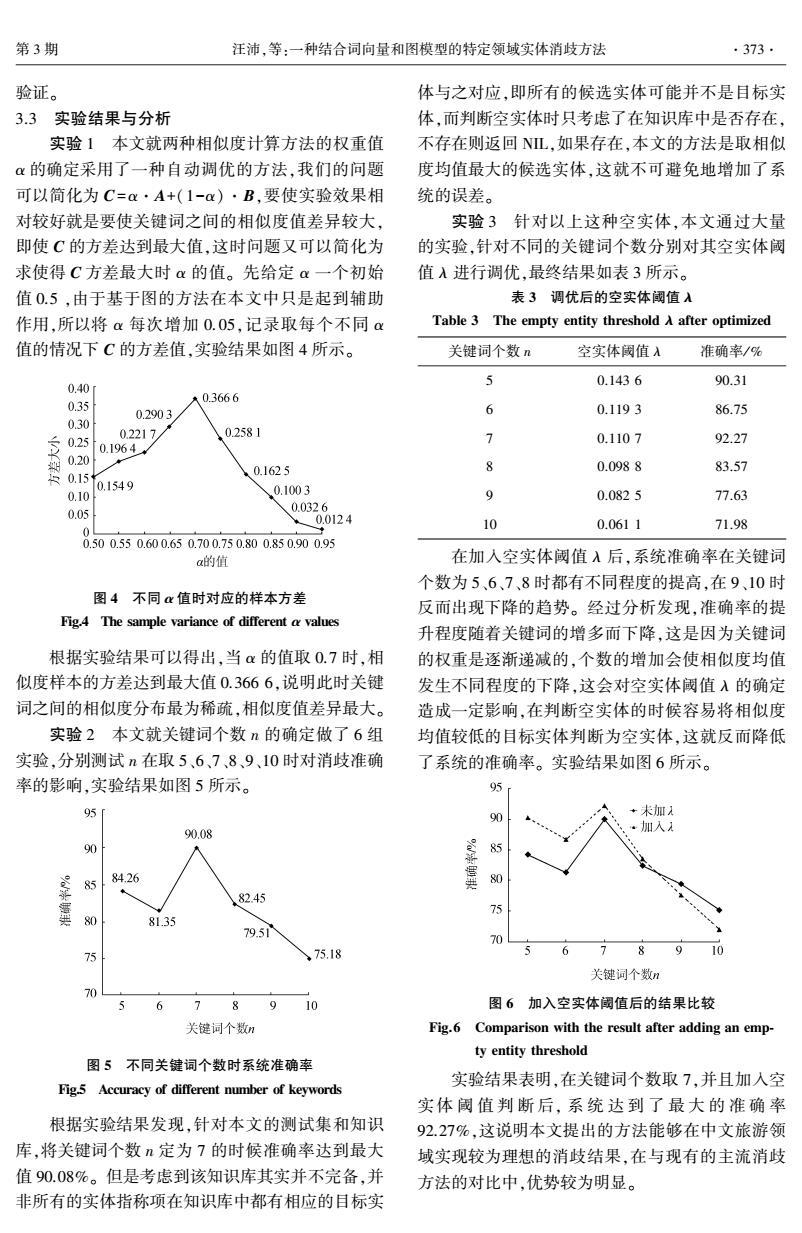
第3期 汪沛,等:一种结合词向量和图模型的特定领域实体消歧方法 ·373. 验证。 体与之对应,即所有的候选实体可能并不是目标实 3.3实验结果与分析 体,而判断空实体时只考虑了在知识库中是否存在, 实验1本文就两种相似度计算方法的权重值 不存在则返回NL,如果存在,本文的方法是取相似 α的确定采用了一种自动调优的方法,我们的问题 度均值最大的候选实体,这就不可避免地增加了系 可以简化为C=a·A+(1-α)·B,要使实验效果相 统的误差。 对较好就是要使关键词之间的相似度值差异较大, 实验3针对以上这种空实体,本文通过大量 即使C的方差达到最大值,这时问题又可以简化为 的实验,针对不同的关键词个数分别对其空实体阈 求使得C方差最大时α的值。先给定α一个初始 值入进行调优,最终结果如表3所示。 值0.5,由于基于图的方法在本文中只是起到辅助 表3调优后的空实体阈值入 作用,所以将α每次增加0.05,记录取每个不同α Table 3 The empty entity threshold A after optimized 值的情况下C的方差值,实验结果如图4所示。 关键词个数n 空实体阈值入 准确率/% 5 0.1436 90.31 0.40 0.3666 0.35 0.2903 6 0.1193 86.75 0.30 0.2217 0.2581 。025 7 0.1107 92.27 0.1964 8020 0.1625 8 0.0988 83.57 0.15 0.1549 0.10 0.1003 9 0.0825 77.63 0.05 0.0326 0.0124 10 0.0611 71.98 0.500.550.600.650.700.750.800.850.900.95 a的值 在加入空实体阈值入后,系统准确率在关键词 个数为5、6、7、8时都有不同程度的提高,在9、10时 图4不同值时对应的样本方差 反而出现下降的趋势。经过分析发现,准确率的提 Fig.4 The sample variance of different a values 升程度随着关键词的增多而下降,这是因为关键词 根据实验结果可以得出,当α的值取0.7时,相 的权重是逐渐递减的,个数的增加会使相似度均值 似度样本的方差达到最大值0.3666,说明此时关键 发生不同程度的下降,这会对空实体阈值入的确定 词之间的相似度分布最为稀疏,相似度值差异最大。 造成一定影响,在判断空实体的时候容易将相似度 实验2本文就关键词个数n的确定做了6组 均值较低的目标实体判断为空实体,这就反而降低 实验,分别测试n在取5、6、7、8、9、10时对消歧准确 了系统的准确率。实验结果如图6所示。 率的影响,实验结果如图5所示。 95 号 90 +未加 90.08 ·加入1 90 84.26 0 82.45 0 81.35 79.51 70 心 75.18 6 78910 关键词个数n 70 5 6 7 8910 图6加入空实体阔值后的结果比较 关健词个数n Fig.6 Comparison with the result after adding an emp- ty entity threshold 图5不同关键词个数时系统准确率 实验结果表明,在关键词个数取7,并且加入空 Fig.5 Accuracy of different number of keywords 实体阈值判断后,系统达到了最大的准确率 根据实验结果发现,针对本文的测试集和知识 92.27%,这说明本文提出的方法能够在中文旅游领 库,将关键词个数n定为7的时候准确率达到最大 域实现较为理想的消歧结果,在与现有的主流消歧 值90.08%。但是考虑到该知识库其实并不完备,并 方法的对比中,优势较为明显。 非所有的实体指称项在知识库中都有相应的目标实验证。 3.3 实验结果与分析 实验 1 本文就两种相似度计算方法的权重值 α 的确定采用了一种自动调优的方法,我们的问题 可以简化为 C=α·A+(1-α)·B,要使实验效果相 对较好就是要使关键词之间的相似度值差异较大, 即使 C 的方差达到最大值,这时问题又可以简化为 求使得 C 方差最大时 α 的值。 先给定 α 一个初始 值 0.5 ,由于基于图的方法在本文中只是起到辅助 作用,所以将 α 每次增加 0.05,记录取每个不同 α 值的情况下 C 的方差值,实验结果如图 4 所示。 图 4 不同 α 值时对应的样本方差 Fig.4 The sample variance of different α values 根据实验结果可以得出,当 α 的值取 0.7 时,相 似度样本的方差达到最大值 0.366 6,说明此时关键 词之间的相似度分布最为稀疏,相似度值差异最大。 实验 2 本文就关键词个数 n 的确定做了 6 组 实验,分别测试 n 在取 5、6、7、8、9、10 时对消歧准确 率的影响,实验结果如图 5 所示。 图 5 不同关键词个数时系统准确率 Fig.5 Accuracy of different number of keywords 根据实验结果发现,针对本文的测试集和知识 库,将关键词个数 n 定为 7 的时候准确率达到最大 值 90.08%。 但是考虑到该知识库其实并不完备,并 非所有的实体指称项在知识库中都有相应的目标实 体与之对应,即所有的候选实体可能并不是目标实 体,而判断空实体时只考虑了在知识库中是否存在, 不存在则返回 NIL,如果存在,本文的方法是取相似 度均值最大的候选实体,这就不可避免地增加了系 统的误差。 实验 3 针对以上这种空实体,本文通过大量 的实验,针对不同的关键词个数分别对其空实体阈 值 λ 进行调优,最终结果如表 3 所示。 表 3 调优后的空实体阈值 λ Table 3 The empty entity threshold λ after optimized 关键词个数 n 空实体阈值 λ 准确率/ % 5 0.143 6 90.31 6 0.119 3 86.75 7 0.110 7 92.27 8 0.098 8 83.57 9 0.082 5 77.63 10 0.061 1 71.98 在加入空实体阈值 λ 后,系统准确率在关键词 个数为 5、6、7、8 时都有不同程度的提高,在 9、10 时 反而出现下降的趋势。 经过分析发现,准确率的提 升程度随着关键词的增多而下降,这是因为关键词 的权重是逐渐递减的,个数的增加会使相似度均值 发生不同程度的下降,这会对空实体阈值 λ 的确定 造成一定影响,在判断空实体的时候容易将相似度 均值较低的目标实体判断为空实体,这就反而降低 了系统的准确率。 实验结果如图 6 所示。 图 6 加入空实体阈值后的结果比较 Fig.6 Comparison with the result after adding an emp⁃ ty entity threshold 实验结果表明,在关键词个数取 7,并且加入空 实体 阈 值 判 断 后, 系 统 达 到 了 最 大 的 准 确 率 92.27%,这说明本文提出的方法能够在中文旅游领 域实现较为理想的消歧结果,在与现有的主流消歧 方法的对比中,优势较为明显。 第 3 期 汪沛,等:一种结合词向量和图模型的特定领域实体消歧方法 ·373·