正在加载图片...
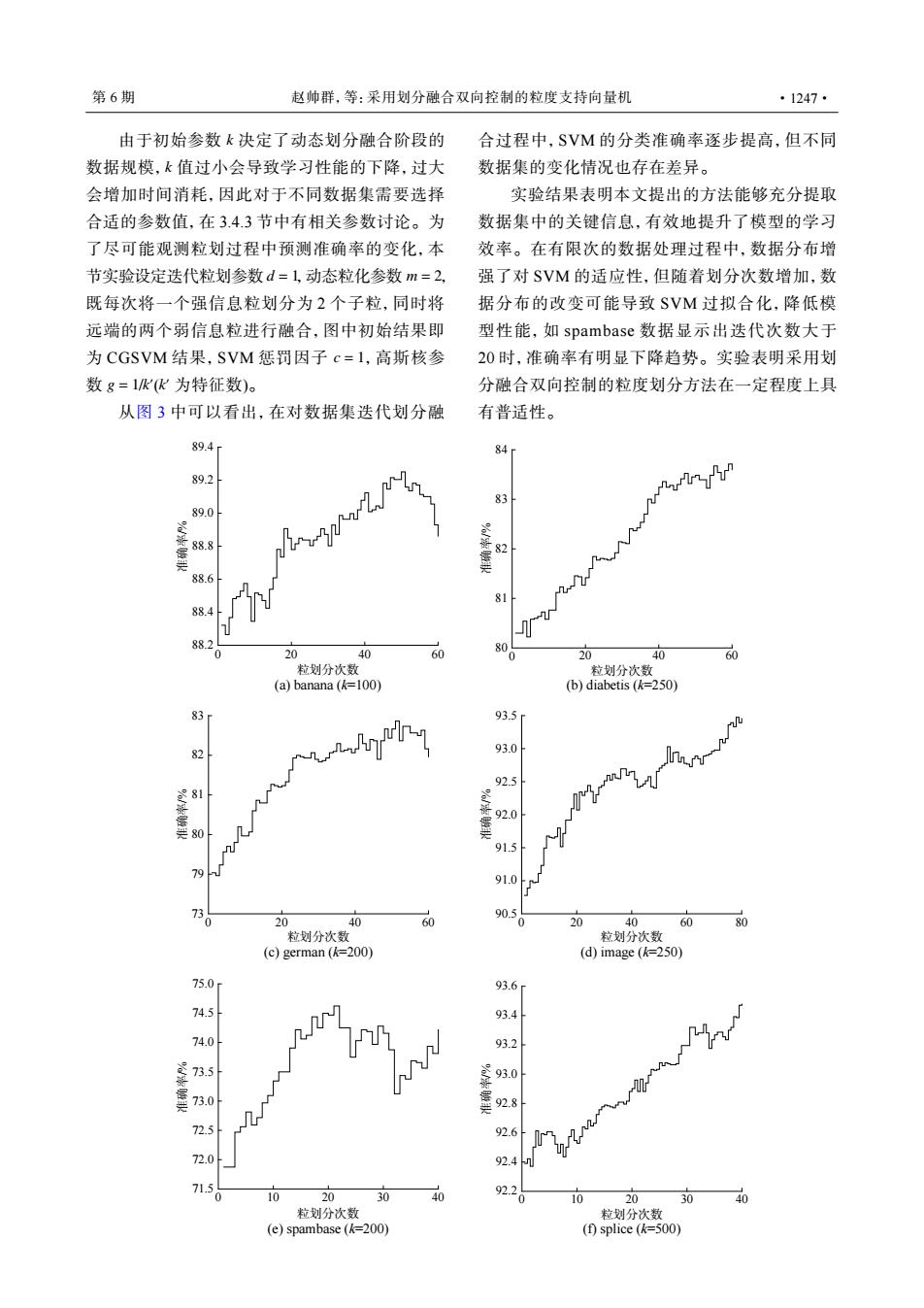
第6期 赵帅群,等:采用划分融合双向控制的粒度支持向量机 ·1247· 由于初始参数k决定了动态划分融合阶段的 合过程中,SVM的分类准确率逐步提高,但不同 数据规模,k值过小会导致学习性能的下降,过大 数据集的变化情况也存在差异。 会增加时间消耗,因此对于不同数据集需要选择 实验结果表明本文提出的方法能够充分提取 合适的参数值,在3.4.3节中有相关参数讨论。为 数据集中的关键信息,有效地提升了模型的学习 了尽可能观测粒划过程中预测准确率的变化,本 效率。在有限次的数据处理过程中,数据分布增 节实验设定迭代粒划参数d=1,动态粒化参数m=2, 强了对SVM的适应性,但随着划分次数增加,数 既每次将一个强信息粒划分为2个子粒,同时将 据分布的改变可能导致SVM过拟合化,降低模 远端的两个弱信息粒进行融合,图中初始结果即 型性能,如spambase数据显示出迭代次数大于 为CGSVM结果,SVM惩罚因子c=1,高斯核参 20时,准确率有明显下降趋势。实验表明采用划 数g=1kK为特征数). 分融合双向控制的粒度划分方法在一定程度上具 从图3中可以看出,在对数据集迭代划分融 有普适性。 89.4 84 89.2 89.0 88.6 81 88.4 88. 0 8 20 40 0 20 40 60 粒划分次数 粒划分次数 (a)banana(=100) (b)diabetis (=250) 83 93.5 93.0 92.5 81 久rnT0 92.0 91.5 19 91.0 73 90.5 20 0 0 20 40 60 畅 粒划分次数 粒划分次数 (c)german (=200) (d)image (k=250) 75.0 93.6 74.5 93.4 74.0 93.2 73.5 93.0 73.0 92.8 72.5 92.6 72.0 92.4 2 71.5 10 20 30 40 92.2 10 20 30 40 粒划分次数 粒划分次数 (e)spambase (=200) (f)splice (=500)k k d = 1 m = 2 c = 1 g = 1 k ′ k ′ 由于初始参数 决定了动态划分融合阶段的 数据规模, 值过小会导致学习性能的下降,过大 会增加时间消耗,因此对于不同数据集需要选择 合适的参数值,在 3.4.3 节中有相关参数讨论。为 了尽可能观测粒划过程中预测准确率的变化,本 节实验设定迭代粒划参数 ,动态粒化参数 , 既每次将一个强信息粒划分为 2 个子粒,同时将 远端的两个弱信息粒进行融合,图中初始结果即 为 CGSVM 结果,SVM 惩罚因子 ,高斯核参 数 / ( 为特征数)。 从图 3 中可以看出,在对数据集迭代划分融 合过程中,SVM 的分类准确率逐步提高,但不同 数据集的变化情况也存在差异。 实验结果表明本文提出的方法能够充分提取 数据集中的关键信息,有效地提升了模型的学习 效率。在有限次的数据处理过程中,数据分布增 强了对 SVM 的适应性,但随着划分次数增加,数 据分布的改变可能导致 SVM 过拟合化,降低模 型性能,如 spambase 数据显示出迭代次数大于 20 时,准确率有明显下降趋势。实验表明采用划 分融合双向控制的粒度划分方法在一定程度上具 有普适性。 89.4 89.2 89.0 88.8 准确率/% 粒划分次数 88.6 88.4 88.2 0 20 40 60 (a) banana (k=100) 84 83 82 81 准确率/% 粒划分次数 80 0 20 40 60 (b) diabetis (k=250) 83 80 79 82 81 准确率/% 粒划分次数 73 0 20 40 60 (c) german (k=200) 93.5 93.0 92.5 92.0 91.5 91.0 准确率/% 粒划分次数 90.5 0 20 40 80 60 (d) image (k=250) 75.0 74.5 74.0 73.5 73.0 72.5 72.0 准确率/% 粒划分次数 71.5 0 20 10 30 40 (e) spambase (k=200) 93.6 93.4 93.2 93.0 92.8 92.6 92.4 准确率/% 粒划分次数 92.2 0 10 20 30 40 (f) splice (k=500) 第 6 期 赵帅群,等:采用划分融合双向控制的粒度支持向量机 ·1247·