正在加载图片...
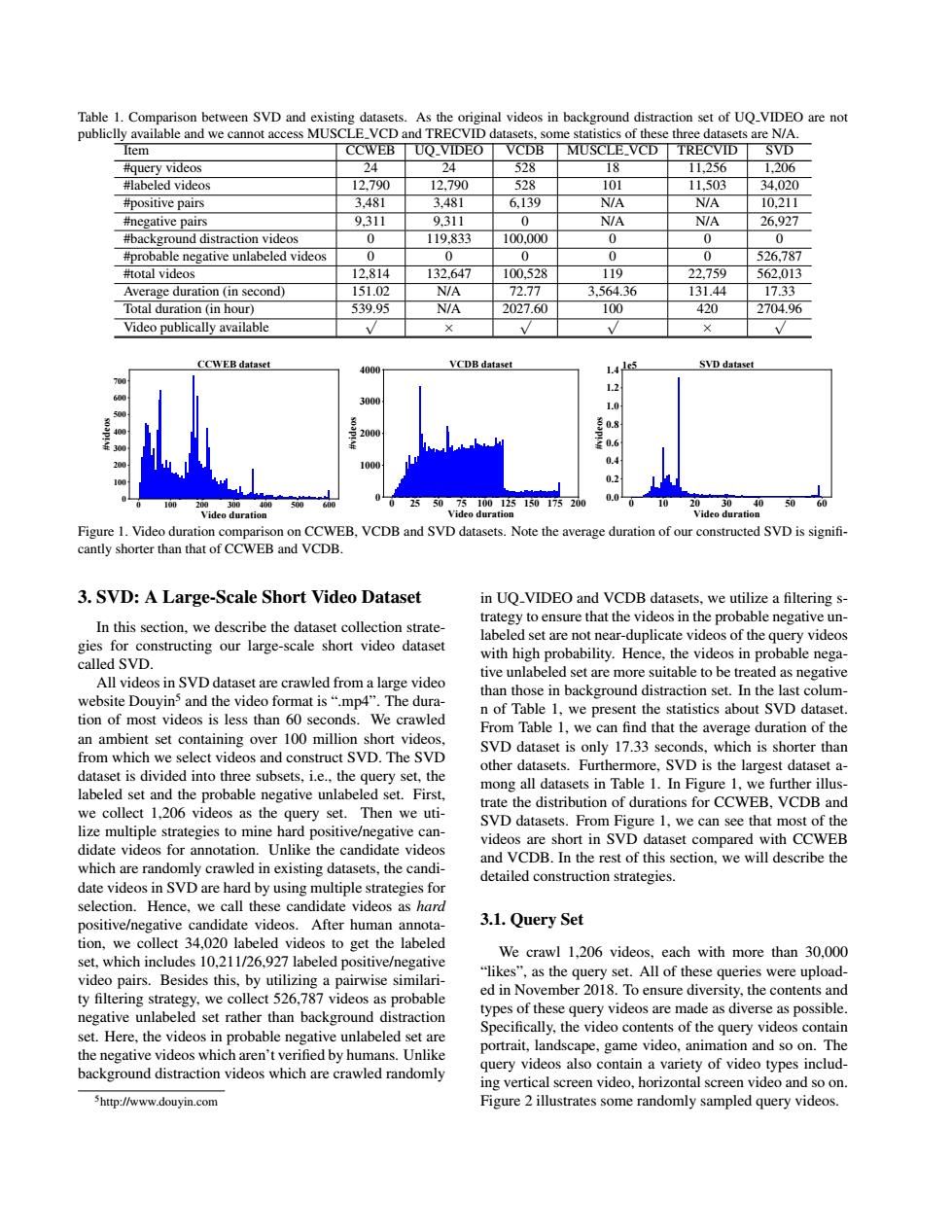
Table 1.Comparison between SVD and existing datasets.As the original videos in background distraction set of UQ_VIDEO are not publiclly available and we cannot access MUSCLE_VCD and TRECVID datasets,some statistics of these three datasets are N/A. Item CCWEB UO_VIDEO VCDB MUSCLE VCD TRECVID SVD #query videos 24 24 528 18 11,256 1,206 #labeled videos 12.790 12.790 528 101 11,503 34.020 #positive pairs 3.481 3.481 6.139 N/A N/A 10,211 #negative pairs 9311 9.311 0 N/A N/A 26.927 #background distraction videos 0 119.833 100.000 0 0 0 #probable negative unlabeled videos 0 0 0 0 0 526.787 #total videos 12,814 132,647 100,528 119 22,759 562.013 Average duration (in second) 151.02 N/A 72.77 3.564.36 131.44 17.33 Total duration (in hour) 539.95 NIA 2027.60 100 420 2704.96 Video publically available × W V CCWEB dataset VCDB dataset 4000 1.4 les SVD dataset 1.2 3000 1.0 200 0.8 0.6 0 100 0.4 0.0 100 200300400 50 25 5075100125150175200 2 3040 50 Video duration Video duration Video duration Figure 1.Video duration comparison on CCWEB,VCDB and SVD datasets.Note the average duration of our constructed SVD is signifi- cantly shorter than that of CCWEB and VCDB. 3.SVD:A Large-Scale Short Video Dataset in UQ_VIDEO and VCDB datasets,we utilize a filtering s- trategy to ensure that the videos in the probable negative un- In this section.we describe the dataset collection strate- labeled set are not near-duplicate videos of the query videos gies for constructing our large-scale short video dataset called SVD with high probability.Hence,the videos in probable nega- tive unlabeled set are more suitable to be treated as negative All videos in SVD dataset are crawled from a large video than those in background distraction set.In the last colum- website Douyin5 and the video format is".mp4".The dura- n of Table 1,we present the statistics about SVD dataset. tion of most videos is less than 60 seconds.We crawled From Table 1,we can find that the average duration of the an ambient set containing over 100 million short videos, from which we select videos and construct SVD.The SVD SVD dataset is only 17.33 seconds,which is shorter than dataset is divided into three subsets,i.e.,the query set,the other datasets.Furthermore,SVD is the largest dataset a- labeled set and the probable negative unlabeled set.First, mong all datasets in Table 1.In Figure 1,we further illus- trate the distribution of durations for CCWEB.VCDB and we collect 1.206 videos as the query set.Then we uti- SVD datasets.From Figure 1.we can see that most of the lize multiple strategies to mine hard positive/negative can- didate videos for annotation.Unlike the candidate videos videos are short in SVD dataset compared with CCWEB and VCDB.In the rest of this section,we will describe the which are randomly crawled in existing datasets.the candi- detailed construction strategies. date videos in SVD are hard by using multiple strategies for selection.Hence,we call these candidate videos as hard positive/negative candidate videos.After human annota- 3.1.Query Set tion,we collect 34,020 labeled videos to get the labeled set,which includes 10,211/26,927 labeled positive/negative We crawl 1,206 videos,each with more than 30,000 video pairs.Besides this,by utilizing a pairwise similari- "likes",as the query set.All of these queries were upload- ty filtering strategy,we collect 526,787 videos as probable ed in November 2018.To ensure diversity,the contents and negative unlabeled set rather than background distraction types of these query videos are made as diverse as possible. Specifically,the video contents of the query videos contain set.Here,the videos in probable negative unlabeled set are the negative videos which aren't verified by humans.Unlike portrait,landscape,game video,animation and so on.The background distraction videos which are crawled randomly query videos also contain a variety of video types includ- ing vertical screen video,horizontal screen video and so on http://www.douyin.com Figure 2 illustrates some randomly sampled query videos.Table 1. Comparison between SVD and existing datasets. As the original videos in background distraction set of UQ VIDEO are not publiclly available and we cannot access MUSCLE VCD and TRECVID datasets, some statistics of these three datasets are N/A. Item CCWEB UQ VIDEO VCDB MUSCLE VCD TRECVID SVD #query videos 24 24 528 18 11,256 1,206 #labeled videos 12,790 12,790 528 101 11,503 34,020 #positive pairs 3,481 3,481 6,139 N/A N/A 10,211 #negative pairs 9,311 9,311 0 N/A N/A 26,927 #background distraction videos 0 119,833 100,000 0 0 0 #probable negative unlabeled videos 0 0 0 0 0 526,787 #total videos 12,814 132,647 100,528 119 22,759 562,013 Average duration (in second) 151.02 N/A 72.77 3,564.36 131.44 17.33 Total duration (in hour) 539.95 N/A 2027.60 100 420 2704.96 Video publically available √ × √ √ × √ 0 100 200 300 400 500 600 Video duration 0 100 200 300 400 500 600 700 #videos CCWEB dataset 0 25 50 75 100 125 150 175 200 Video duration 0 1000 2000 3000 4000 #videos VCDB dataset 0 10 20 30 40 50 60 Video duration 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 #videos 1e5 SVD dataset Figure 1. Video duration comparison on CCWEB, VCDB and SVD datasets. Note the average duration of our constructed SVD is signifi- cantly shorter than that of CCWEB and VCDB. 3. SVD: A Large-Scale Short Video Dataset In this section, we describe the dataset collection strategies for constructing our large-scale short video dataset called SVD. All videos in SVD dataset are crawled from a large video website Douyin5 and the video format is “.mp4”. The duration of most videos is less than 60 seconds. We crawled an ambient set containing over 100 million short videos, from which we select videos and construct SVD. The SVD dataset is divided into three subsets, i.e., the query set, the labeled set and the probable negative unlabeled set. First, we collect 1,206 videos as the query set. Then we utilize multiple strategies to mine hard positive/negative candidate videos for annotation. Unlike the candidate videos which are randomly crawled in existing datasets, the candidate videos in SVD are hard by using multiple strategies for selection. Hence, we call these candidate videos as hard positive/negative candidate videos. After human annotation, we collect 34,020 labeled videos to get the labeled set, which includes 10,211/26,927 labeled positive/negative video pairs. Besides this, by utilizing a pairwise similarity filtering strategy, we collect 526,787 videos as probable negative unlabeled set rather than background distraction set. Here, the videos in probable negative unlabeled set are the negative videos which aren’t verified by humans. Unlike background distraction videos which are crawled randomly 5http://www.douyin.com in UQ VIDEO and VCDB datasets, we utilize a filtering strategy to ensure that the videos in the probable negative unlabeled set are not near-duplicate videos of the query videos with high probability. Hence, the videos in probable negative unlabeled set are more suitable to be treated as negative than those in background distraction set. In the last column of Table 1, we present the statistics about SVD dataset. From Table 1, we can find that the average duration of the SVD dataset is only 17.33 seconds, which is shorter than other datasets. Furthermore, SVD is the largest dataset among all datasets in Table 1. In Figure 1, we further illustrate the distribution of durations for CCWEB, VCDB and SVD datasets. From Figure 1, we can see that most of the videos are short in SVD dataset compared with CCWEB and VCDB. In the rest of this section, we will describe the detailed construction strategies. 3.1. Query Set We crawl 1,206 videos, each with more than 30,000 “likes”, as the query set. All of these queries were uploaded in November 2018. To ensure diversity, the contents and types of these query videos are made as diverse as possible. Specifically, the video contents of the query videos contain portrait, landscape, game video, animation and so on. The query videos also contain a variety of video types including vertical screen video, horizontal screen video and so on. Figure 2 illustrates some randomly sampled query videos