正在加载图片...
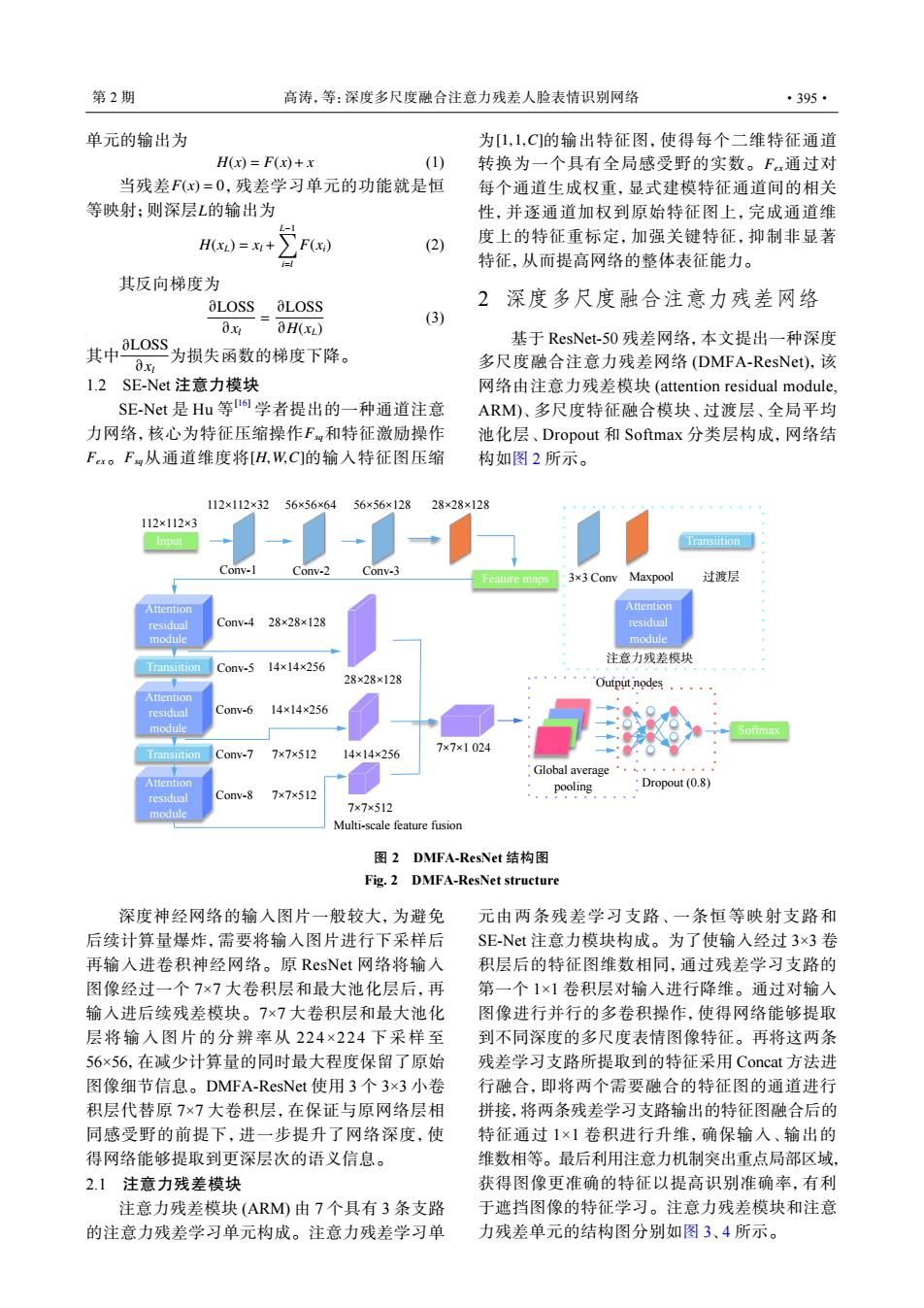
第2期 高涛,等:深度多尺度融合注意力残差人脸表情识别网络 ·395· 单元的输出为 为[1,1,C的输出特征图,使得每个二维特征通道 H(x)=F(x)+x (1) 转换为一个具有全局感受野的实数。Fx通过对 当残差F(x)=0,残差学习单元的功能就是恒 每个通道生成权重,显式建模特征通道间的相关 等映射:则深层L的输出为 性,并逐通道加权到原始特征图上,完成通道维 H)=+∑F) (2) 度上的特征重标定,加强关键特征,抑制非显著 特征,从而提高网络的整体表征能力。 其反向梯度为 aLOSS aLOSS 2深度多尺度融合注意力残差网络 x 3H(XL) (3) 其中L0ss 基于ResNet-50残差网络,本文提出一种深度 为损失函数的梯度下降。 0x 多尺度融合注意力残差网络(DMFA-ResNet),该 l.2SE-Net注意力模块 网络由注意力残差模块(attention residual module, SE-Net是Hu等I学者提出的一种通道注意 ARM)、多尺度特征融合模块、过渡层、全局平均 力网络,核心为特征压缩操作F和特征激励操作 池化层、Dropout和Softmax分类层构成,网络结 Fx。Fg从通道维度将[H,W,C]的输入特征图压缩 构如图2所示。 112×112×32 56×56×64 56×56×128 28×28×128 112×112×3 Input Transiition Conv-2 Conv-3 3x3 Conv Maxpool 过渡层 Attention Attention residual Conv-428×28×128 residual module module 注意力残差模块 Conv-.514×14×256 28×28×128 Output nodes Attention residual Conv-6 14×14×256 module Transiition Conv-7 7×7×512 14×14×256 7×7×1024 Global average·' Attention 7×7×512 pooling Dropout(0.8) residual Conv-8 module 7×7×512 Multi-scale feature fusion 图2DMFA-ResNet结构图 Fig.2 DMFA-ResNet structure 深度神经网络的输人图片一般较大,为避免 元由两条残差学习支路、一条恒等映射支路和 后续计算量爆炸,需要将输入图片进行下采样后 SE-Net注意力模块构成。为了使输入经过3×3卷 再输入进卷积神经网络。原ResNet网络将输入 积层后的特征图维数相同,通过残差学习支路的 图像经过一个7×7大卷积层和最大池化层后,再 第一个1×1卷积层对输入进行降维。通过对输入 输入进后续残差模块。7×7大卷积层和最大池化 图像进行并行的多卷积操作,使得网络能够提取 层将输入图片的分辨率从224×224下采样至 到不同深度的多尺度表情图像特征。再将这两条 56×56,在减少计算量的同时最大程度保留了原始 残差学习支路所提取到的特征采用Concat方法进 图像细节信息。DMFA-ResNet使用3个3×3小卷 行融合,即将两个需要融合的特征图的通道进行 积层代替原7×7大卷积层,在保证与原网络层相 拼接,将两条残差学习支路输出的特征图融合后的 同感受野的前提下,进一步提升了网络深度,使 特征通过1×1卷积进行升维,确保输入、输出的 得网络能够提取到更深层次的语义信息。 维数相等。最后利用注意力机制突出重点局部区域, 2.1注意力残差模块 获得图像更准确的特征以提高识别准确率,有利 注意力残差模块(ARM由7个具有3条支路 于遮挡图像的特征学习。注意力残差模块和注意 的注意力残差学习单元构成。注意力残差学习单 力残差单元的结构图分别如图3、4所示。单元的输出为 H(x) = F(x)+ x (1) F(x) = 0 L 当残差 ,残差学习单元的功能就是恒 等映射;则深层 的输出为 H(xL) = xl + ∑L−1 i=l F(xi) (2) 其反向梯度为 ∂LOSS ∂xl = ∂LOSS ∂H(xL) (3) ∂LOSS ∂xl 其中 为损失函数的梯度下降。 1.2 SE-Net 注意力模块 Fsq Fex Fsq [H,W,C] SE-Net 是 Hu 等 [16] 学者提出的一种通道注意 力网络,核心为特征压缩操作 和特征激励操作 。 从通道维度将 的输入特征图压缩 [1,1,C] Fex 为 的输出特征图,使得每个二维特征通道 转换为一个具有全局感受野的实数。 通过对 每个通道生成权重,显式建模特征通道间的相关 性,并逐通道加权到原始特征图上,完成通道维 度上的特征重标定,加强关键特征,抑制非显著 特征,从而提高网络的整体表征能力。 2 深度多尺度融合注意力残差网络 基于 ResNet-50 残差网络,本文提出一种深度 多尺度融合注意力残差网络 (DMFA-ResNet),该 网络由注意力残差模块 (attention residual module, ARM)、多尺度特征融合模块、过渡层、全局平均 池化层、Dropout 和 Softmax 分类层构成,网络结 构如图 2 所示。 Attention residual module Attention residual module Attention residual module Transiition Transiition Feature maps Output nodes Softmax Input 3×3 Conv Maxpool Conv-1 Conv-2 Conv-3 Conv-4 Conv-5 Conv-6 Conv-7 Conv-8 Global average pooling Dropout (0.8) Transiition 注意力残差模块 过渡层 Multi-scale feature fusion Attention residual module 112×112×3 112×112×32 56×56×64 56×56×128 28×28×128 28×28×128 14×14×256 14×14×256 7×7×512 7×7×512 7×7×512 14×14×256 28×28×128 7×7×1 024 图 2 DMFA-ResNet 结构图 Fig. 2 DMFA-ResNet structure 深度神经网络的输入图片一般较大,为避免 后续计算量爆炸,需要将输入图片进行下采样后 再输入进卷积神经网络。原 ResNet 网络将输入 图像经过一个 7×7 大卷积层和最大池化层后,再 输入进后续残差模块。7×7 大卷积层和最大池化 层将输入图片的分辨率从 224×224 下采样至 56×56,在减少计算量的同时最大程度保留了原始 图像细节信息。DMFA-ResNet 使用 3 个 3×3 小卷 积层代替原 7×7 大卷积层,在保证与原网络层相 同感受野的前提下,进一步提升了网络深度,使 得网络能够提取到更深层次的语义信息。 2.1 注意力残差模块 注意力残差模块 (ARM) 由 7 个具有 3 条支路 的注意力残差学习单元构成。注意力残差学习单 元由两条残差学习支路、一条恒等映射支路和 SE-Net 注意力模块构成。为了使输入经过 3×3 卷 积层后的特征图维数相同,通过残差学习支路的 第一个 1×1 卷积层对输入进行降维。通过对输入 图像进行并行的多卷积操作,使得网络能够提取 到不同深度的多尺度表情图像特征。再将这两条 残差学习支路所提取到的特征采用 Concat 方法进 行融合,即将两个需要融合的特征图的通道进行 拼接,将两条残差学习支路输出的特征图融合后的 特征通过 1×1 卷积进行升维,确保输入、输出的 维数相等。最后利用注意力机制突出重点局部区域, 获得图像更准确的特征以提高识别准确率,有利 于遮挡图像的特征学习。注意力残差模块和注意 力残差单元的结构图分别如图 3、4 所示。 第 2 期 高涛,等:深度多尺度融合注意力残差人脸表情识别网络 ·395·