正在加载图片...
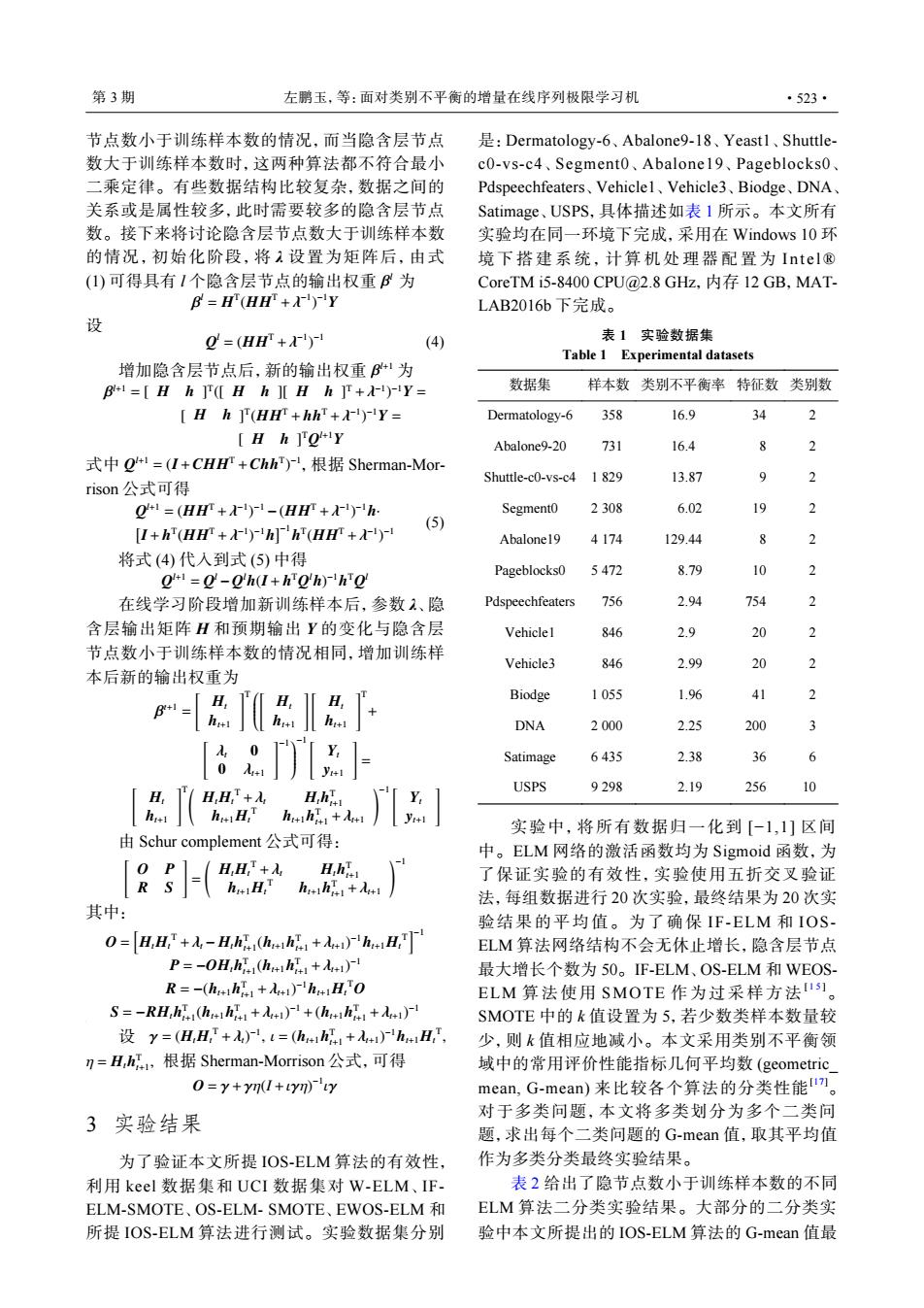
第3期 左鹏玉,等:面对类别不平衡的增量在线序列极限学习机 ·523· 节点数小于训练样本数的情况,而当隐含层节点 是:Dermatology-.6、Abalones9-l8、Yeastl、Shuttle- 数大于训练样本数时,这两种算法都不符合最小 c0-vs-c4、Segment0、Abalone 19、Pageblocks0、 二乘定律。有些数据结构比较复杂,数据之间的 Pdspeechfeaters、Vehicle1、Vehicle3、Biodge、DNA、 关系或是属性较多,此时需要较多的隐含层节点 Satimage、USPS,具体描述如表1所示。本文所有 数。接下来将讨论隐含层节点数大于训练样本数 实验均在同一环境下完成,采用在Windows 10环 的情况,初始化阶段,将1设置为矩阵后,由式 境下搭建系统,计算机处理器配置为Intel® (1)可得具有I个隐含层节点的输出权重B为 CoreTM i5-8400CPU@2.8GHz,内存12GB,MAT- B=H(HH+A)Y LAB2016b下完成, 设 0=(HH+) (4) 表1实验数据集 Table 1 Experimental datasets 增加隐含层节点后,新的输出权重B41为 B1=[Hh T([HhHh+)-Y= 数据集 样本数类别不平衡率特征数类别数 Hh ](H+hh+Y= Dermatology-6 358 16.9 34 Hh ]QY Abalone9-20 731 16.4 2 式中g=(I+CHHr+Chh),根据Sherman-Mor- Shuttle-c0-vs-c4 1 829 13.87 9 2 rison公式可得 Q1=(HH+')1-(HH+ Segmento 2308 6.02 19 [I+h(H+h]h(H) (5) Abalone19 4174 129.44 2 将式(4)代入到式(5)中得 Pageblocks0 5472 8.1 10 2 0=0-0h(I+ho'h)ho 在线学习阶段增加新训练样本后,参数2、隐 Pdspeechfeaters 756 29 754 2 含层输出矩阵H和预期输出Y的变化与隐含层 Vehiclel 846 20 2 节点数小于训练样本数的情况相同,增加训练样 Vehicle3 846 2.9 20 2 本后新的输出权重为 H Biodge 1055 1q6 41 2 B+= DNA 2000 2.25 200 3 ay Satimage 6435 2.38 36 6 USPS 9298 2.19 256 9 H,H,+入 H.hia huH huihi+ 实验中,将所有数据归一化到[-1,1]区间 由Schur complement公式可得: 中。ELM网络的激活函数均为Sigmoid函数,为 0P1 H,H+入 H.hi 了保证实验的有效性,实验使用五折交叉验证 hut H:T hohi+A 法,每组数据进行20次实验,最终结果为20次实 其中: 验结果的平均值。为了确保IF-ELM和IOS- 0=A,H+-H,hhh+i)hH ELM算法网络结构不会无休止增长,隐含层节点 P=-OH,hi(hh+ 最大增长个数为50。F-ELM、OS-ELM和WEOS- R=-(hh+)hH.O ELM算法使用SMOTE作为过采样方法Is1。 S=-RH,hi(h++(h+ SMOTE中的k值设置为5,若少数类样本数量较 设y=(HH,+入),t=(h4h+i)h4H,, 少,则k值相应地减小。本文采用类别不平衡领 n=H,h,根据Sherman--Morrison公式,可得 域中的常用评价性能指标几何平均数(geometric O=y+yn(+yn)y mean,G-mean)来比较各个算法的分类性能m。 3实验结果 对于多类问题,本文将多类划分为多个二类问 题,求出每个二类问题的G-mean值,取其平均值 为了验证本文所提IOS-ELM算法的有效性, 作为多类分类最终实验结果。 利用keel数据集和UCI数据集对W-ELM、IF- 表2给出了隐节点数小于训练样本数的不同 ELM-SMOTE、OS-ELM-SMOTE、EWOS-ELM和 ELM算法二分类实验结果。大部分的二分类实 所提IOS-ELM算法进行测试。实验数据集分别 验中本文所提出的IOS-ELM算法的G-mean值最β l 节点数小于训练样本数的情况,而当隐含层节点 数大于训练样本数时,这两种算法都不符合最小 二乘定律。有些数据结构比较复杂,数据之间的 关系或是属性较多,此时需要较多的隐含层节点 数。接下来将讨论隐含层节点数大于训练样本数 的情况,初始化阶段,将 λ 设置为矩阵后,由式 (1) 可得具有 l 个隐含层节点的输出权重 为 β l = H T (HHT +λ −1 ) −1Y 设 Q l = (HHT +λ −1 ) −1 (4) β 增加隐含层节点后,新的输出权重 l+1 为 β l+1 = [ H h ] T ([ H h ][ H h ] T +λ −1 ) −1Y = [ H h ] T (HHT + hhT +λ −1 ) −1Y = [ H h ] TQ l+1Y Q l+1 = (I+CHHT +ChhT ) 式中 −1,根据 Sherman-Morrison 公式可得 Q l+1 = (HHT +λ −1 ) −1 −(HHT +λ −1 ) −1h· [ I+ h T (HHT +λ −1 ) −1h ]−1 h T (HHT +λ −1 ) −1 (5) 将式 (4) 代入到式 (5) 中得 Q l+1 = Q l −Q lh(I+ h TQ lh) −1h TQ l 在线学习阶段增加新训练样本后,参数 λ、隐 含层输出矩阵 H 和预期输出 Y 的变化与隐含层 节点数小于训练样本数的情况相同,增加训练样 本后新的输出权重为 β t+1 = [ Ht ht+1 ]T [ Ht ht+1 ] [ Ht ht+1 ]T + [ λt 0 0 λt+1 ]−1 −1 [ Yt yt+1 ] = [ Ht ht+1 ]T( HtHt T +λt Hth T t+1 ht+1Ht T ht+1h T t+1 +λt+1 )−1 [ Yt yt+1 ] 由 Schur complement 公式可得: [ O P R S ] = ( HtHt T +λt Hth T t+1 ht+1Ht T ht+1h T t+1 +λt+1 )−1 其中: O = [ HtHt T +λt − Hth T t+1 (ht+1h T t+1 +λt+1) −1ht+1Ht T ]−1 P = −OHth T t+1 (ht+1h T t+1 +λt+1) −1 R = −(ht+1h T t+1 +λt+1) −1ht+1Ht TO S = −RHth T t+1 (ht+1h T t+1 +λt+1) −1 +(ht+1h T t+1 +λt+1) −1 γ = (HtHt T +λt) −1 , ι = (ht+1h T t+1 +λt+1) −1ht+1Ht T , η = Hth T t+1 , 设 根据 Sherman-Morrison 公式,可得 O = γ+γη(I +ιγη) −1 ιγ 3 实验结果 为了验证本文所提 IOS-ELM 算法的有效性, 利用 keel 数据集和 UCI 数据集对 W-ELM、IFELM-SMOTE、OS-ELM- SMOTE、EWOS-ELM 和 所提 IOS-ELM 算法进行测试。实验数据集分别 是:Dermatology-6、Abalone9-18、Yeast1、Shuttlec0-vs-c4、Segment0、Abalone19、Pageblocks0、 Pdspeechfeaters、Vehicle1、Vehicle3、Biodge、DNA、 Satimage、USPS,具体描述如表 1 所示。本文所有 实验均在同一环境下完成,采用在 Windows 10 环 境下搭建系统,计算机处理器配置 为 Intel® CoreTM i5-8400 CPU@2.8 GHz,内存 12 GB,MATLAB2016b 下完成。 表 1 实验数据集 Table 1 Experimental datasets 数据集 样本数 类别不平衡率 特征数 类别数 Dermatology-6 358 16.9 34 2 Abalone9-20 731 16.4 8 2 Shuttle-c0-vs-c4 1 829 13.87 9 2 Segment0 2 308 6.02 19 2 Abalone19 4 174 129.44 8 2 Pageblocks0 5 472 8.79 10 2 Pdspeechfeaters 756 2.94 754 2 Vehicle1 846 2.9 20 2 Vehicle3 846 2.99 20 2 Biodge 1 055 1.96 41 2 DNA 2 000 2.25 200 3 Satimage 6 435 2.38 36 6 USPS 9 298 2.19 256 10 实验中,将所有数据归一化到 [−1,1] 区间 中。ELM 网络的激活函数均为 Sigmoid 函数,为 了保证实验的有效性,实验使用五折交叉验证 法,每组数据进行 20 次实验,最终结果为 20 次实 验结果的平均值。为了确保 IF-ELM 和 IOSELM 算法网络结构不会无休止增长,隐含层节点 最大增长个数为 50。IF-ELM、OS-ELM 和 WEOSELM 算法使 用 SMOTE 作为过采样方法 [ 1 5 ]。 SMOTE 中的 k 值设置为 5,若少数类样本数量较 少,则 k 值相应地减小。本文采用类别不平衡领 域中的常用评价性能指标几何平均数 (geometric_ mean, G-mean) 来比较各个算法的分类性能[17]。 对于多类问题,本文将多类划分为多个二类问 题,求出每个二类问题的 G-mean 值,取其平均值 作为多类分类最终实验结果。 表 2 给出了隐节点数小于训练样本数的不同 ELM 算法二分类实验结果。大部分的二分类实 验中本文所提出的 IOS-ELM 算法的 G-mean 值最 第 3 期 左鹏玉,等:面对类别不平衡的增量在线序列极限学习机 ·523·