正在加载图片...
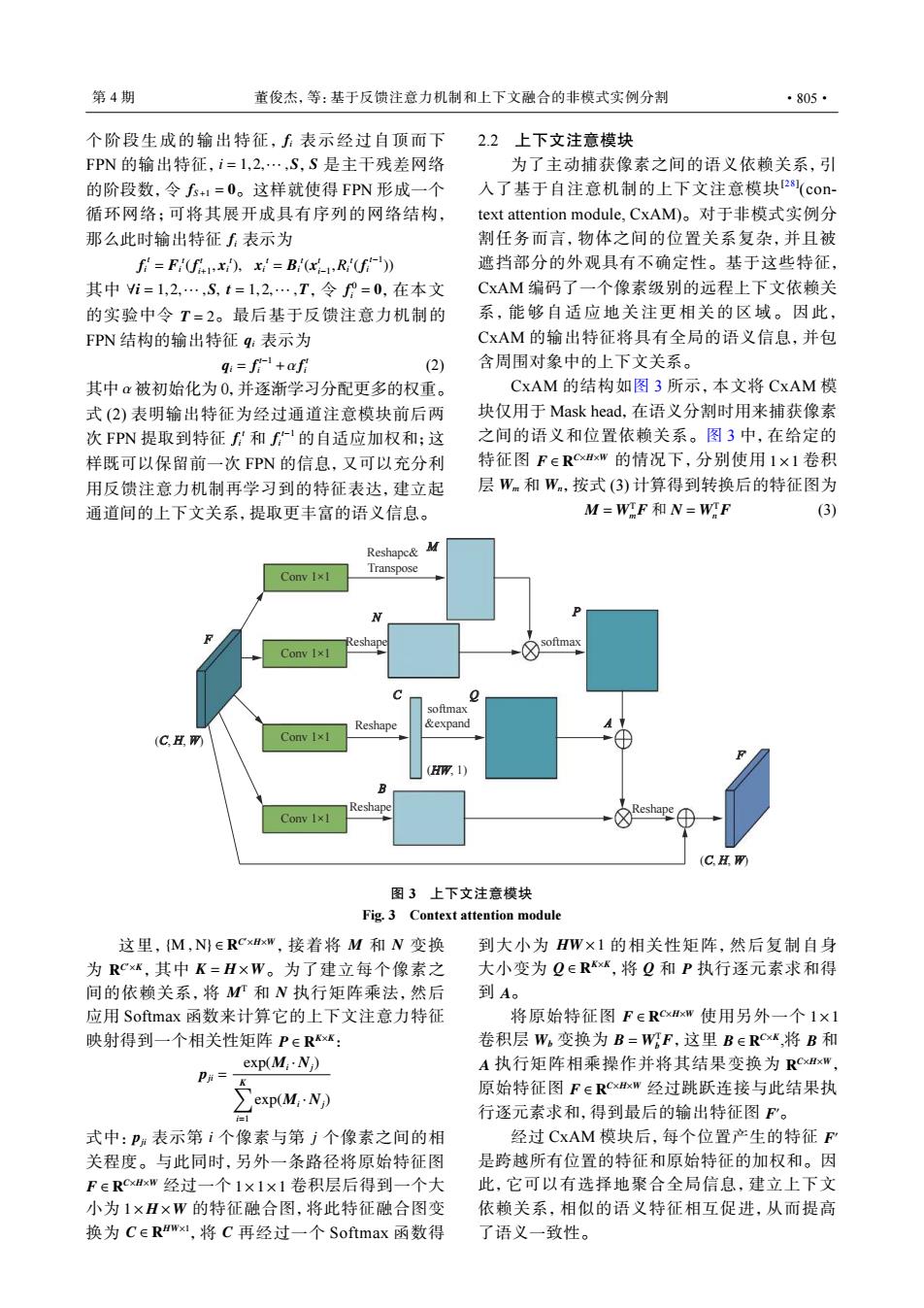
第4期 董俊杰,等:基于反馈注意力机制和上下文融合的非模式实例分割 ·805· 个阶段生成的输出特征,表示经过自顶而下 2.2上下文注意模块 FPN的输出特征,i=1,2,…,S,S是主干残差网络 为了主动捕获像素之间的语义依赖关系,引 的阶段数,令f+1=0。这样就使得FPN形成一个 入了基于自注意机制的上下文注意模块28(con- 循环网络;可将其展开成具有序列的网络结构, text attention module,CxAM)。对于非模式实例分 那么此时输出特征表示为 割任务而言,物体之间的位置关系复杂,并且被 f=F(f).x=B:(R(f)) 遮挡部分的外观具有不确定性。基于这些特征, 其中i=1,2,…,S,t=1,2,…,T,令f°=0,在本文 CxAM编码了一个像素级别的远程上下文依赖关 的实验中令T=2。最后基于反馈注意力机制的 系,能够自适应地关注更相关的区域。因此, FPN结构的输出特征q:表示为 CxAM的输出特征将具有全局的语义信息,并包 q:=f+af月 (2) 含周围对象中的上下文关系。 其中α被初始化为0,并逐渐学习分配更多的权重。 CxAM的结构如图3所示,本文将CxAM模 式(2)表明输出特征为经过通道注意模块前后两 块仅用于Mask head,,在语义分割时用来捕获像素 次FPN提取到特征f和f的自适应加权和;这 之间的语义和位置依赖关系。图3中,在给定的 样既可以保留前一次FPN的信息,又可以充分利 特征图F∈RxxW的情况下,分别使用1×1卷积 用反馈注意力机制再学习到的特征表达,建立起 层Wm和W,按式(3)计算得到转换后的特征图为 通道间的上下文关系,提取更丰富的语义信息。 M=WF和N=WrF (3) Reshapc& Conw1×L Transpose Reshape softmax Conv I×1 softmax Reshape &expand (C. Conv 1×1 (HW,1) B Reshape Conw1×1 Reshape (C.) 图3上下文注意模块 Fig.3 Context attention module 这里,M,N∈RCxHxw,接着将M和N变换 到大小为HW×1的相关性矩阵,然后复制自身 为RCxk,其中K=H×W。为了建立每个像素之 大小变为Q∈R,将Q和P执行逐元素求和得 间的依赖关系,将MT和N执行矩阵乘法,然后 到A。 应用Softmax函数来计算它的上下文注意力特征 将原始特征图F∈RCxHxW使用另外一个1×1 映射得到一个相关性矩阵P∈Rxk: 卷积层W。变换为B=WFF,这里BERCXK,将B和 exp(M:·N) A执行矩阵相乘操作并将其结果变换为RCxExW, P= pOt:N) 原始特征图F∈RCxHxW经过跳跃连接与此结果执 行逐元素求和,得到最后的输出特征图F'。 式中:P:表示第i个像素与第j个像素之间的相 经过CxAM模块后,每个位置产生的特征F 关程度。与此同时,另外一条路径将原始特征图 是跨越所有位置的特征和原始特征的加权和。因 FERCxHxW经过一个1×1×1卷积层后得到一个大 此,它可以有选择地聚合全局信息,建立上下文 小为1×H×W的特征融合图,将此特征融合图变 依赖关系,相似的语义特征相互促进,从而提高 换为CERWx1,将C再经过一个Softmax函数得 了语义一致性。fi i = 1,2,··· ,S S fS+1 = 0 fi 个阶段生成的输出特征, 表示经过自顶而下 FPN 的输出特征, , 是主干残差网络 的阶段数,令 。这样就使得 FPN 形成一个 循环网络;可将其展开成具有序列的网络结构, 那么此时输出特征 表示为 fi t = Fi t (f t i+1 , xi t ), xi t = Bi t (x t i−1 ,Ri t (fi t−1 )) ∀i = 1,2,··· ,S, t = 1,2,··· ,T f 0 i = 0 T = 2 qi 其中 ,令 ,在本文 的实验中令 。最后基于反馈注意力机制的 FPN 结构的输出特征 表示为 qi = f t−1 i +α f t i (2) α fi t fi t−1 其中 被初始化为 0,并逐渐学习分配更多的权重。 式 (2) 表明输出特征为经过通道注意模块前后两 次 FPN 提取到特征 和 的自适应加权和;这 样既可以保留前一次 FPN 的信息,又可以充分利 用反馈注意力机制再学习到的特征表达,建立起 通道间的上下文关系,提取更丰富的语义信息。 2.2 上下文注意模块 为了主动捕获像素之间的语义依赖关系,引 入了基于自注意机制的上下文注意模块[28] (context attention module, CxAM)。对于非模式实例分 割任务而言,物体之间的位置关系复杂,并且被 遮挡部分的外观具有不确定性。基于这些特征, CxAM 编码了一个像素级别的远程上下文依赖关 系,能够自适应地关注更相关的区域。因此, CxAM 的输出特征将具有全局的语义信息,并包 含周围对象中的上下文关系。 F ∈ R C×H×W 1×1 Wm Wn CxAM 的结构如图 3 所示,本文将 CxAM 模 块仅用于 Mask head,在语义分割时用来捕获像素 之间的语义和位置依赖关系。图 3 中,在给定的 特征图 的情况下,分别使用 卷积 层 和 ,按式 (3) 计算得到转换后的特征图为 M = WT m F 和 N = WT n F (3) M N C Q P A F′ Conv 1×1 Conv 1×1 Conv 1×1 Conv 1×1 Reshapc& Transpose F softmax softmax &expand B Reshape Reshape Reshape Reshape (C, H, W) (C, H, W) (HW, 1) 图 3 上下文注意模块 Fig. 3 Context attention module {M , N} ∈ R C ′×H×W M N R C ′×K K = H ×W MT N P ∈ R K×K 这里, ,接着将 和 变换 为 ,其中 。为了建立每个像素之 间的依赖关系,将 和 执行矩阵乘法,然后 应用 Softmax 函数来计算它的上下文注意力特征 映射得到一个相关性矩阵 : pji = exp(Mi · Nj) ∑K i=1 exp(Mi · Nj) pji i j F ∈ R C×H×W 1×1×1 1× H ×W C ∈ R HW×1 C 式中: 表示第 个像素与第 个像素之间的相 关程度。与此同时,另外一条路径将原始特征图 经过一个 卷积层后得到一个大 小为 的特征融合图,将此特征融合图变 换为 ,将 再经过一个 Softmax 函数得 HW ×1 Q ∈ R K×K Q P A 到大小为 的相关性矩阵,然后复制自身 大小变为 ,将 和 执行逐元素求和得 到 。 F ∈ R C×H×W 1×1 Wb B = WT b F B ∈ R C×K B A R C×H×W F ∈ R C×H×W F ′ 将原始特征图 使用另外一个 卷积层 变换为 ,这里 ,将 和 执行矩阵相乘操作并将其结果变换为 , 原始特征图 经过跳跃连接与此结果执 行逐元素求和,得到最后的输出特征图 。 F 经过 CxAM 模块后,每个位置产生的特征 ′ 是跨越所有位置的特征和原始特征的加权和。因 此,它可以有选择地聚合全局信息,建立上下文 依赖关系,相似的语义特征相互促进,从而提高 了语义一致性。 第 4 期 董俊杰,等:基于反馈注意力机制和上下文融合的非模式实例分割 ·805·