正在加载图片...
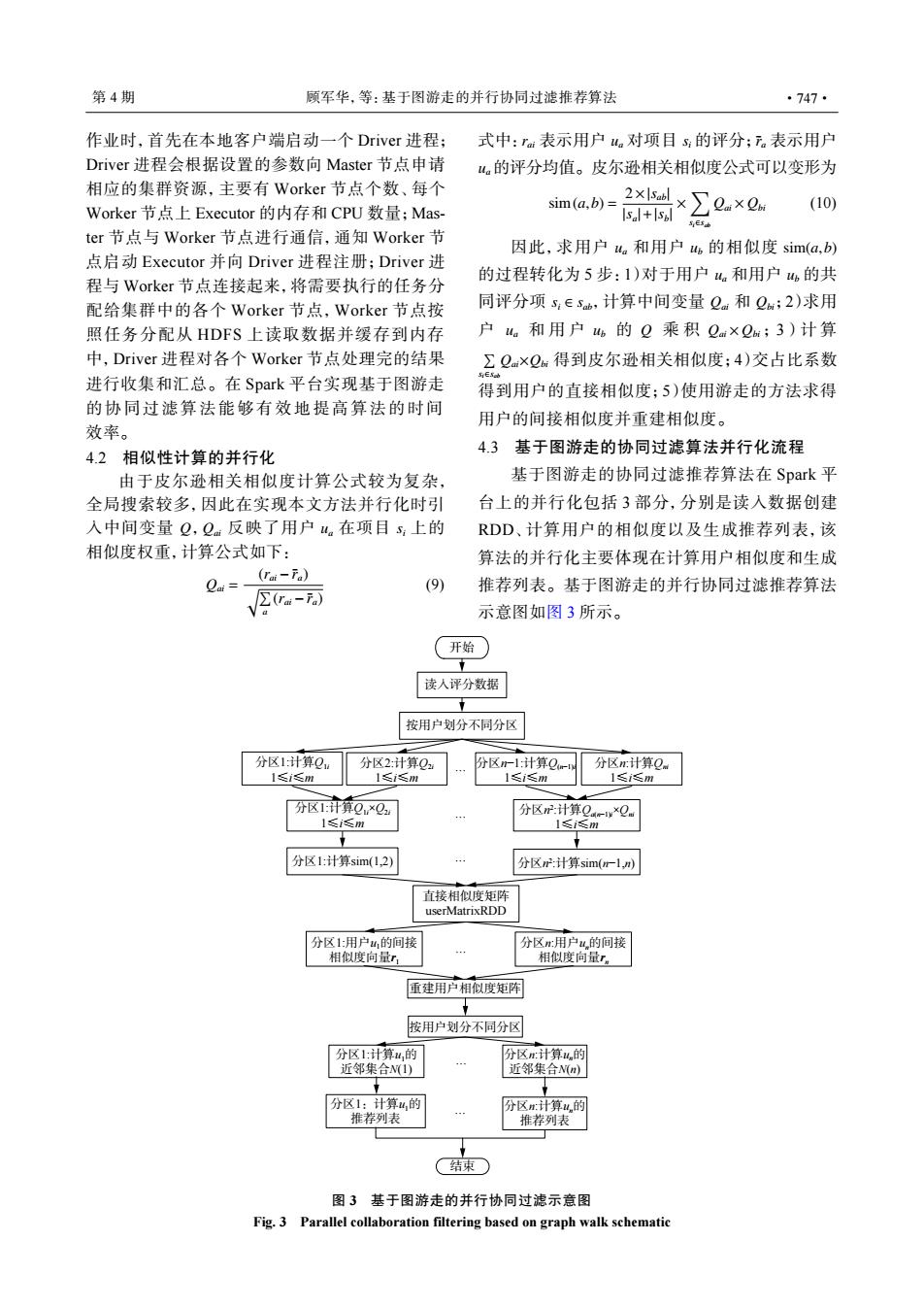
第4期 顾军华,等:基于图游走的并行协同过滤推荐算法 ·747· 作业时,首先在本地客户端启动一个Driver进程; 式中:rm表示用户w对项目的评分;下。表示用户 Driver进程会根据设置的参数向Master节点申请 “的评分均值。皮尔逊相关相似度公式可以变形为 相应的集群资源,主要有Worker节点个数、每个 Worker节点上Executor的内存和CPU数量;Mas- sim(a,b)= .x (10) SEsd ter节点与Worker节点进行通信,通知Worker节 因此,求用户ua和用户的相似度sim(a,b) 点启动Executor并向Driver进程注册;Driver进 的过程转化为5步:1)对于用户4和用户,的共 程与Worker节点连接起来,将需要执行的任务分 配给集群中的各个Worker节点,Worker节点按 同评分项s:∈sb,计算中间变量Qa和Qa;2)求用 照任务分配从HDFS上读取数据并缓存到内存 户。和用户6的Q乘积Qm×Q;3)计算 中,Driver进程对各个Worker节点处理完的结果 ∑Qm×Q得到皮尔逊相关相似度;4)交占比系数 进行收集和汇总。在Spark平台实现基于图游走 得到用户的直接相似度;5)使用游走的方法求得 的协同过滤算法能够有效地提高算法的时间 用户的间接相似度并重建相似度。 效率。 4.2相似性计算的并行化 4.3基于图游走的协同过滤算法并行化流程 由于皮尔逊相关相似度计算公式较为复杂, 基于图游走的协同过滤推荐算法在Spark平 全局搜索较多,因此在实现本文方法并行化时引 台上的并行化包括3部分,分别是读入数据创建 入中间变量Q,Qm反映了用户。在项目s:上的 RDD、计算用户的相似度以及生成推荐列表,该 相似度权重,计算公式如下: 算法的并行化主要体现在计算用户相似度和生成 Cai=- (rai-Fa) (9) 推荐列表。基于图游走的并行协同过滤推荐算法 示意图如图3所示。 开始 读人评分数据 按用户划分不同分区 分区1计算Q, 分区2:计算Q2 分区m1:计算O 分区x计算Q 1≤i≤m 1≤i≤m 1≤i≤m 1≤i≤m 分区1计算Q×Q 分区P:计算Q-w×Qm 1≤i≤m I≤i≤m 分区1:计算sim(1,2) 分区:计算sim(广l,) 直接相似度矩阵 userMatrixRDD 分区1:用户山,的间接 分区r用户u的间接 相似度向量r 相似度向量r。 重建用户相似度矩阵 t 按用户划分不同分区 分区1上计算u的 分区m:计算u的 近邻集合N(I) 近邻集合N(n) 分区1:计算4,的 分区m:计算u的 推荐列表 推荐列表 结柬 图3基于图游走的并行协同过滤示意图 Fig.3 Parallel collaboration filtering based on graph walk schematic作业时,首先在本地客户端启动一个 Driver 进程; Driver 进程会根据设置的参数向 Master 节点申请 相应的集群资源,主要有 Worker 节点个数、每个 Worker 节点上 Executor 的内存和 CPU 数量;Master 节点与 Worker 节点进行通信,通知 Worker 节 点启动 Executor 并向 Driver 进程注册;Driver 进 程与 Worker 节点连接起来,将需要执行的任务分 配给集群中的各个 Worker 节点,Worker 节点按 照任务分配从 HDFS 上读取数据并缓存到内存 中,Driver 进程对各个 Worker 节点处理完的结果 进行收集和汇总。在 Spark 平台实现基于图游走 的协同过滤算法能够有效地提高算法的时间 效率。 4.2 相似性计算的并行化 Q Qai ua si 由于皮尔逊相关相似度计算公式较为复杂, 全局搜索较多,因此在实现本文方法并行化时引 入中间变量 , 反映了用户 在项目 上的 相似度权重,计算公式如下: Qai = (rai −r¯a) √∑ a (rai −r¯a) (9) rai ua si r¯a ua 式中: 表示用户 对项目 的评分; 表示用户 的评分均值。皮尔逊相关相似度公式可以变形为 sim(a,b) = 2×|sab| |sa|+|sb| × ∑ si∈sab Qai × Qbi (10) ua ub sim(a,b) ua ub si ∈ sab Qai Qbi ua ub Q Qai × Qbi ∑ si∈sabQai×Qbi 因此,求用户 和用户 的相似度 的过程转化为 5 步:1)对于用户 和用户 的共 同评分项 ,计算中间变量 和 ;2)求用 户 和用户 的 乘 积 ; 3 )计算 得到皮尔逊相关相似度;4)交占比系数 得到用户的直接相似度;5)使用游走的方法求得 用户的间接相似度并重建相似度。 4.3 基于图游走的协同过滤算法并行化流程 基于图游走的协同过滤推荐算法在 Spark 平 台上的并行化包括 3 部分,分别是读入数据创建 RDD、计算用户的相似度以及生成推荐列表,该 算法的并行化主要体现在计算用户相似度和生成 推荐列表。基于图游走的并行协同过滤推荐算法 示意图如图 3 所示。 开始 按用户划分不同分区 按用户划分不同分区 重建用户相似度矩阵 结束 直接相似度矩阵 userMatrixRDD … … … … … … 读入评分数据 分区1:计算Q1i 1≤i≤m 分区2:计算Q2i 1≤i≤m 分区n:计算Qni 1≤i≤m 分区n−1:计算Q(n−1)i 1≤i≤m 分区1:计算Q1i×Q2i 1≤i≤m 分区1:计算sim(1,2) 分区n 2 :计算Qa(n−1)i×Qni 1≤i≤m 分区n 2 :计算sim(n−1,n) 分区1:用户u1的间接 相似度向量r1 分区n:用户un的间接 相似度向量rn 分区1:计算u1的 近邻集合N(1) 分区n:计算un的 近邻集合N(n) 分区1:计算u1的 推荐列表 分区n:计算un的 推荐列表 图 3 基于图游走的并行协同过滤示意图 Fig. 3 Parallel collaboration filtering based on graph walk schematic 第 4 期 顾军华,等:基于图游走的并行协同过滤推荐算法 ·747·