正在加载图片...
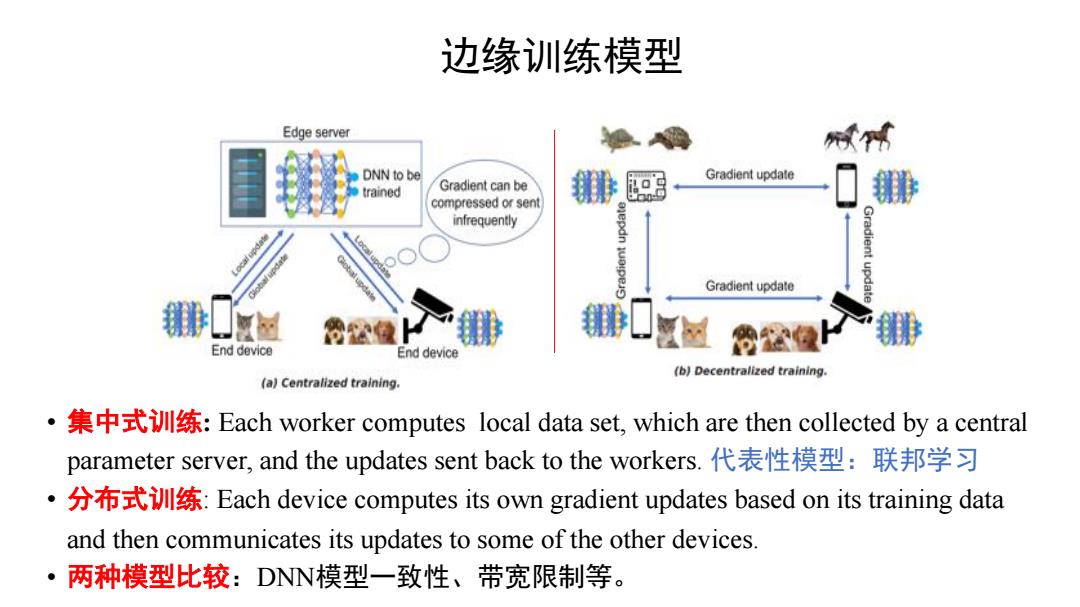
边缘训练模型 Edge server DNN to be Gradient update trained Gradient can be compressed or sen infrequently Gradient update End device End device (b)Decentralized training. (a)Centralized training. ·集中式训练:Each worker computes local data set,which are then collected by a central parameter server,and the updates sent back to the workers.代表性模型:联邦学习 ·分布式训练:Each device computes its own gradient updates based on its training data and then communicates its updates to some of the other devices. ·两种模型比较:DNN模型一致性、带宽限制等。ƊŐŭʼnč • Ʃ#Äŭʼn: Each worker computes local data set, which are then collected by a central parameter server, and the updates sent back to the workers. 8ţÓčŖƚ) • Z·Äŭʼn: Each device computes its own gradient updates based on its training data and then communicates its updates to some of the other devices. • !ĻčĒƆDNNčśÓ¹§Ƨ`Ł