正在加载图片...
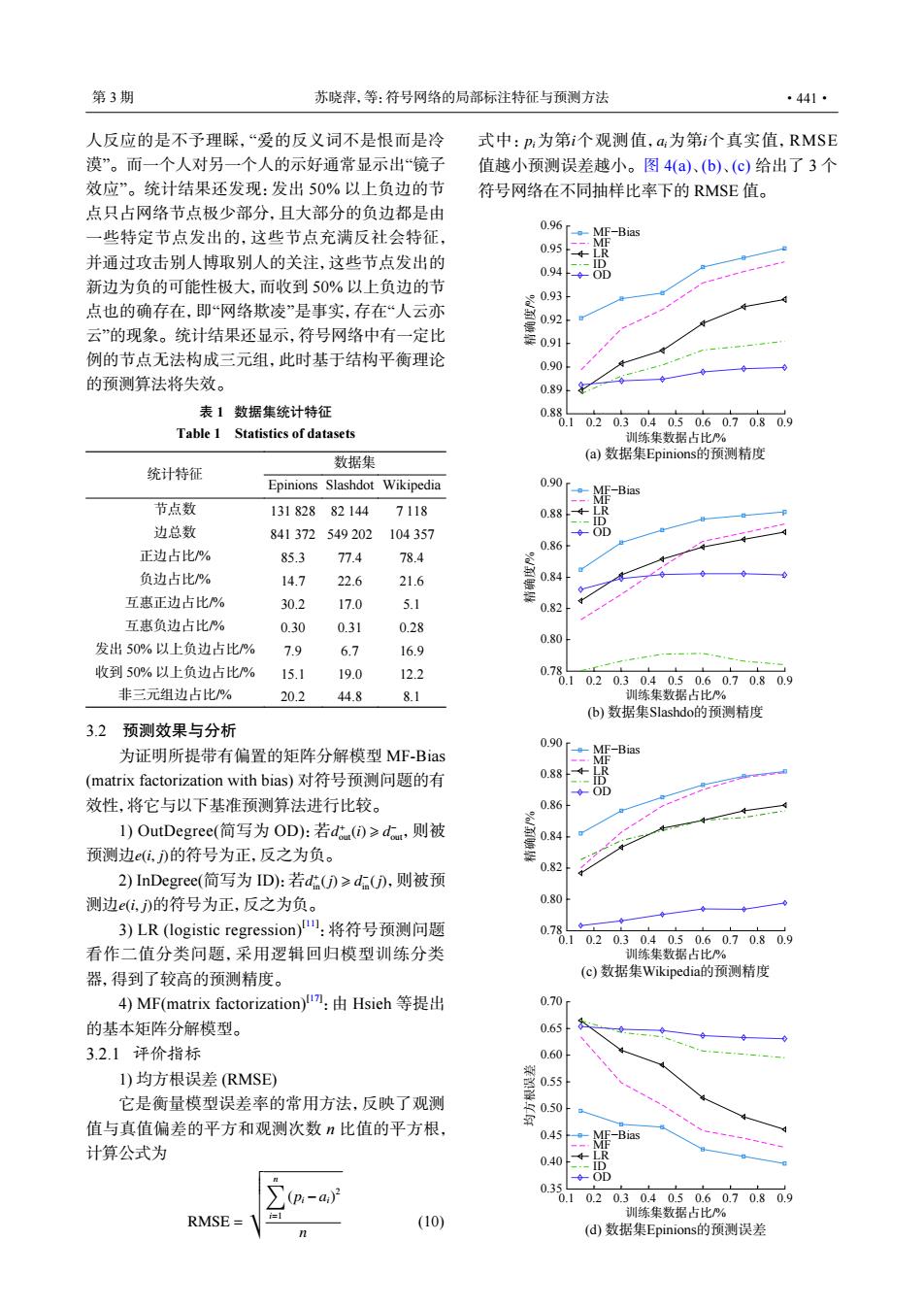
第3期 苏晓萍,等:符号网络的局部标注特征与预测方法 ·441· 人反应的是不予理睬,“爱的反义词不是恨而是冷 式中:p:为第i个观测值,a为第i个真实值,RMSE 漠”。而一个人对另一个人的示好通常显示出“镜子 值越小预测误差越小。图4(a)、(b)、(c)给出了3个 效应”。统计结果还发现:发出50%以上负边的节 符号网络在不同抽样比率下的RMSE值。 点只占网络节点极少部分,且大部分的负边都是由 0.96 些特定节点发出的,这些节点充满反社会特征, MF-Bias 0.95 并通过攻击别人博取别人的关注,这些节点发出的 -ID 0.94◆0D 新边为负的可能性极大,而收到50%以上负边的节 0.93 点也的确存在,即“网络欺凌”是事实,存在“人云亦 0.92 云”的现象。统计结果还显示,符号网络中有一定比 0.91 例的节点无法构成三元组,此时基于结构平衡理论 0.90 的预测算法将失效。 0.89 表1数据集统计特征 0.8 0.1 0.20.30.40.50.60.70.80.9 Table 1 Statistics of datasets 训练集数据占比% 数据集 (a)数据集Epinions的预测精度 统计特征 Epinions Slashdot Wikipedia 0.90 -ME-Bias 节点数 13182882144 7118 0.884 边总数 841372549202104357 ◆OD 0.86 正边占比% 85.3 77.4 78.4 负边占比% 14.7 22.6 21.6 084 互惠正边占比% 30.2 17.0 5.1 0.82 互患负边占比% 0.30 0.31 0.28 0.80 发出50%以上负边占比% 7.9 6.7 16.9 收到50%以上负边占比% ,” 15.1 19.0 12.2 0.78 .10.20.30.40.50.60.70.80.9 非三元组边占比% 20.2 44.8 8.1 训练集数据占比% (b)数据集Slashdof的预测精度 3.2预测效果与分析 0.90. 为证明所提带有偏置的矩阵分解模型MF-Bias MF-Bias M (matrix factorization with bias)对符号预测问题的有 0.88 OD 效性,将它与以下基准预测算法进行比较。 0.86 l)OutDegree(简写为OD):若d()≥d,则被 0.84 预测边(i,)的符号为正,反之为负。 0.82 2)InDegree(简写为ID):若d()≥d),则被预 测边i,)的符号为正,反之为负。 0.80 3)LR(logistic regression)":将符号预测问题 0.78 0 .10.20.30.40.50.60.70.80.9 看作二值分类问题,采用逻辑回归模型训练分类 训练集数据占比% 器,得到了较高的预测精度。 (c)数据集Wikipedial的预测精度 4)Mf(matrix factorization)m:由Hsieh等提出 0.70 的基本矩阵分解模型。 0.65 3.2.1评价指标 0.60 I)均方根误差(RMSE) 它是衡量模型误差率的常用方法,反映了观测 值与真值偏差的平方和观测次数n比值的平方根, 050 0.45 -Bias 计算公式为 0.40 LR --ID OD (p-a)月 0.3 0.10.20.30.40.50.60.70.80.9 训练集数据占比% RMSE (10) (d数据集Epinions的预测误差人反应的是不予理睬,“爱的反义词不是恨而是冷 漠”。而一个人对另一个人的示好通常显示出“镜子 效应”。统计结果还发现:发出 50% 以上负边的节 点只占网络节点极少部分,且大部分的负边都是由 一些特定节点发出的,这些节点充满反社会特征, 并通过攻击别人博取别人的关注,这些节点发出的 新边为负的可能性极大,而收到 50% 以上负边的节 点也的确存在,即“网络欺凌”是事实,存在“人云亦 云”的现象。统计结果还显示,符号网络中有一定比 例的节点无法构成三元组,此时基于结构平衡理论 的预测算法将失效。 3.2 预测效果与分析 为证明所提带有偏置的矩阵分解模型 MF-Bias (matrix factorization with bias) 对符号预测问题的有 效性,将它与以下基准预测算法进行比较。 d + out(i) ⩾ d − out e(i, j) 1) OutDegree(简写为 OD):若 ,则被 预测边 的符号为正,反之为负。 d + in(j) ⩾ d − in(j) e(i, j) 2) InDegree(简写为 ID):若 ,则被预 测边 的符号为正,反之为负。 3) LR (logistic regression)[11] :将符号预测问题 看作二值分类问题,采用逻辑回归模型训练分类 器,得到了较高的预测精度。 4) MF(matrix factorization)[17] :由 Hsieh 等提出 的基本矩阵分解模型。 3.2.1 评价指标 1) 均方根误差 (RMSE) 它是衡量模型误差率的常用方法,反映了观测 值与真值偏差的平方和观测次数 n 比值的平方根, 计算公式为 RMSE = vuuuuut∑n i=1 (pi −ai) 2 n (10) pi i ai 式中: 为第 个观测值, 为第 i 个真实值,RMSE 值越小预测误差越小。图 4(a)、(b)、(c) 给出了 3 个 符号网络在不同抽样比率下的 RMSE 值。 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 0.88 0.89 0.90 0.91 0.92 0.93 0.94 0.95 0.96 精确度/% 训练集数据占比/% (a) 数据集Epinions的预测精度 MF−Bias MF LR ID OD MF−Bias MF LR ID OD 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 0.78 0.80 0.82 0.84 0.86 0.88 0.90 训练集数据占比/% (b) 数据集Slashdo的预测精度 精确度/% MF−Bias MF LR ID OD 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 0.78 0.80 0.82 0.84 0.86 0.88 0.90 训练集数据占比/% (c) 数据集Wikipedia的预测精度 精确度/% MF−Bias MF LR ID OD 均方根误差 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 0.35 0.40 0.45 0.50 0.55 0.60 0.65 0.70 训练集数据占比/% (d) 数据集Epinions的预测误差 表 1 数据集统计特征 Table 1 Statistics of datasets 统计特征 数据集 Epinions Slashdot Wikipedia 节点数 131 828 82 144 7 118 边总数 841 372 549 202 104 357 正边占比/% 85.3 77.4 78.4 负边占比/% 14.7 22.6 21.6 互惠正边占比/% 30.2 17.0 5.1 互惠负边占比/% 0.30 0.31 0.28 发出 50% 以上负边占比/% 7.9 6.7 16.9 收到 50% 以上负边占比/% 15.1 19.0 12.2 非三元组边占比/% 20.2 44.8 8.1 第 3 期 苏晓萍,等:符号网络的局部标注特征与预测方法 ·441·