正在加载图片...
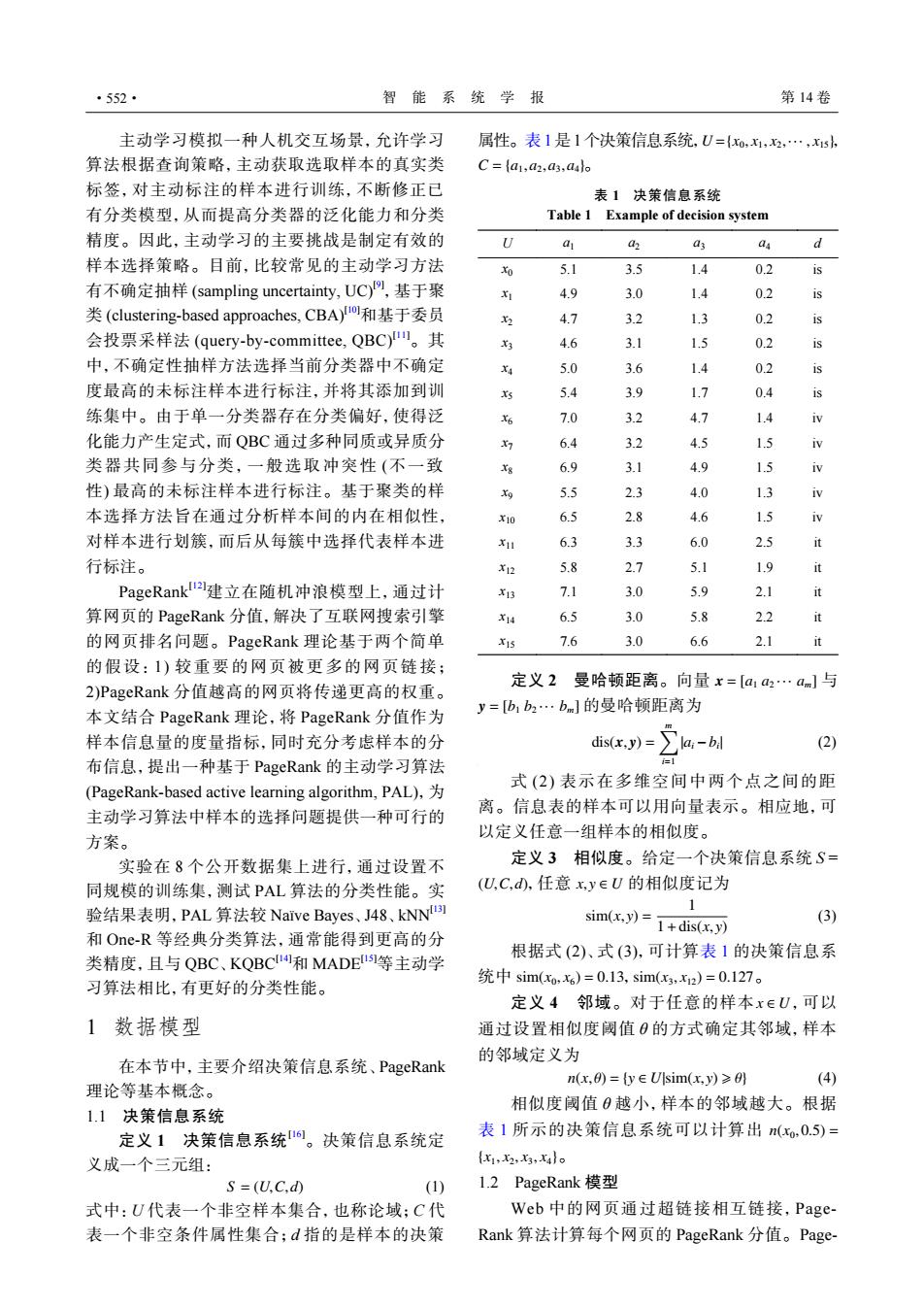
·552· 智能系统学报 第14卷 主动学习模拟一种人机交互场景,允许学习 属性。表1是1个决策信息系统,U={x0,x1,x,…,xs 算法根据查询策略,主动获取选取样本的真实类 C=a,az,a3,aslo 标签,对主动标注的样本进行训练,不断修正已 表1决策信息系统 有分类模型,从而提高分类器的泛化能力和分类 Table 1 Example of decision system 精度。因此,主动学习的主要挑战是制定有效的 U 42 d 样本选择策略。目前,比较常见的主动学习方法 Xo 5.1 3.5 1.4 0.2 is 有不确定抽样(sampling uncertainty,UC)9,基于聚 X1 4.9 3.0 1.4 0.2 is 类(clustering-.based approaches,CBA)Io和基于委员 4.7 3.2 1.3 0.2 is 会投票采样法(query-by-committee,QBC)l。其 4.6 3.1 1.5 0.2 is 中,不确定性抽样方法选择当前分类器中不确定 X4 5.0 3.6 1.4 0.2 is 度最高的未标注样本进行标注,并将其添加到训 5.4 3.9 4 is 练集中。由于单一分类器存在分类偏好,使得泛 X6 7.0 iv 化能力产生定式,而QBC通过多种同质或异质分 7 6.4 1.5 iv 类器共同参与分类,一般选取冲突性(不一致 6.9 4. 1.5 iv 性)最高的未标注样本进行标注。基于聚类的样 Xg 5.5 4.0 1.3 iv 本选择方法旨在通过分析样本间的内在相似性, x10 6.5 2.8 4.6 1.5 对样本进行划簇,而后从每簇中选择代表样本进 6.3 3.3 6.0 2.5 it 行标注。 X12 5.8 2.7 5.1 1.9 PageRank"建立在随机冲浪模型上,通过计 x13 7.1 3.0 5.9 2.1 it 算网页的PageRank分值,解决了互联网搜索引擎 X14 6.5 3.0 5.8 2.2 it 的网页排名问题。PageRank理论基于两个简单 x15 7.6 3.0 6.6 2.1 it 的假设:1)较重要的网页被更多的网页链接; 定义2 2)PageRank分值越高的网页将传递更高的权重。 曼哈顿距离。向量x=[a1a2…am]与 y=[b1b2…bm]的曼哈顿距离为 本文结合PageRank理论,将PageRank分值作为 样本信息量的度量指标,同时充分考虑样本的分 dis(x,y)= (2) 布信息,提出一种基于PageRank的主动学习算法 式(2)表示在多维空间中两个点之间的距 (PageRank-based active learning algorithm,PAL). 主动学习算法中样本的选择问题提供一种可行的 离。信息表的样本可以用向量表示。相应地,可 以定义任意一组样本的相似度。 方案。 实验在8个公开数据集上进行,通过设置不 定义3相似度。给定一个决策信息系统S= 同规模的训练集,测试PAL算法的分类性能。实 (U,C,d,任意x,y∈U的相似度记为 验结果表明,PAL算法较Naive Bayes、.J48、kNN 1 (3) 和One-R等经典分类算法,通常能得到更高的分 sim(x,y)=1+dis(x,y) 根据式(2)、式(3),可计算表1的决策信息系 类精度,且与QBC、KQBC和MADETS1等主动学 习算法相比,有更好的分类性能。 统中sim(xox6)=0.13,sim(x3,x2)=0.127。 定义4邻域。对于任意的样本x∈U,可以 1数据模型 通过设置相似度阈值0的方式确定其邻域,样本 的邻域定义为 在本节中,主要介绍决策信息系统、PageRank n(x,)=y∈sim(x,y)≥ (4) 理论等基本概念。 相似度阈值0越小,样本的邻域越大。根据 1.1决策信息系统 定义1决策信息系统6。决策信息系统定 表1所示的决策信息系统可以计算出(xo,0.5)= 义成一个三元组: {x1,,3x4}0 S=(U,C,d) (1) 1.2 PageRank模型 式中:U代表一个非空样本集合,也称论域;C代 Web中的网页通过超链接相互链接,Page- 表一个非空条件属性集合;d指的是样本的决策 Rank算法计算每个网页的PageRank分值。Page主动学习模拟一种人机交互场景,允许学习 算法根据查询策略,主动获取选取样本的真实类 标签,对主动标注的样本进行训练,不断修正已 有分类模型,从而提高分类器的泛化能力和分类 精度。因此,主动学习的主要挑战是制定有效的 样本选择策略。目前,比较常见的主动学习方法 有不确定抽样 (sampling uncertainty, UC)[9] ,基于聚 类 (clustering-based approaches, CBA)[10]和基于委员 会投票采样法 (query-by-committee, QBC)[11]。其 中,不确定性抽样方法选择当前分类器中不确定 度最高的未标注样本进行标注,并将其添加到训 练集中。由于单一分类器存在分类偏好,使得泛 化能力产生定式,而 QBC 通过多种同质或异质分 类器共同参与分类,一般选取冲突性 (不一致 性) 最高的未标注样本进行标注。基于聚类的样 本选择方法旨在通过分析样本间的内在相似性, 对样本进行划簇,而后从每簇中选择代表样本进 行标注。 PageRank[12]建立在随机冲浪模型上,通过计 算网页的 PageRank 分值,解决了互联网搜索引擎 的网页排名问题。PageRank 理论基于两个简单 的假设: 1) 较重要的网页被更多的网页链接; 2)PageRank 分值越高的网页将传递更高的权重。 本文结合 PageRank 理论,将 PageRank 分值作为 样本信息量的度量指标,同时充分考虑样本的分 布信息,提出一种基于 PageRank 的主动学习算法 (PageRank-based active learning algorithm, PAL),为 主动学习算法中样本的选择问题提供一种可行的 方案。 实验在 8 个公开数据集上进行,通过设置不 同规模的训练集,测试 PAL 算法的分类性能。实 验结果表明,PAL 算法较 Naïve Bayes、J48、kNN[13] 和 One-R 等经典分类算法,通常能得到更高的分 类精度,且与 QBC、KQBC[14]和 MADE[15]等主动学 习算法相比,有更好的分类性能。 1 数据模型 在本节中,主要介绍决策信息系统、PageRank 理论等基本概念。 1.1 决策信息系统 定义 1 决策信息系统[16]。决策信息系统定 义成一个三元组: S = (U,C,d) (1) 式中:U 代表一个非空样本集合,也称论域;C 代 表一个非空条件属性集合;d 指的是样本的决策 U ={x0, x1, x2,··· , x15} C = {a1,a2,a3,a4} 属性。表1是1个决策信息系统, , 。 表 1 决策信息系统 Table 1 Example of decision system U a1 a2 a3 a4 d x0 5.1 3.5 1.4 0.2 is x1 4.9 3.0 1.4 0.2 is x2 4.7 3.2 1.3 0.2 is x3 4.6 3.1 1.5 0.2 is x4 5.0 3.6 1.4 0.2 is x5 5.4 3.9 1.7 0.4 is x6 7.0 3.2 4.7 1.4 iv x7 6.4 3.2 4.5 1.5 iv x8 6.9 3.1 4.9 1.5 iv x9 5.5 2.3 4.0 1.3 iv x10 6.5 2.8 4.6 1.5 iv x11 6.3 3.3 6.0 2.5 it x12 5.8 2.7 5.1 1.9 it x13 7.1 3.0 5.9 2.1 it x14 6.5 3.0 5.8 2.2 it x15 7.6 3.0 6.6 2.1 it x = [a1 a2 ··· am] y = [b1 b2 ··· bm] 定义 2 曼哈顿距离。向量 与 的曼哈顿距离为 dis(x, y) = ∑m i=1 |ai −bi | (2) 式 (2) 表示在多维空间中两个点之间的距 离。信息表的样本可以用向量表示。相应地,可 以定义任意一组样本的相似度。 (U,C,d) x, y ∈ U 定义 3 相似度。给定一个决策信息系统 S = ,任意 的相似度记为 sim(x, y) = 1 1+dis(x, y) (3) sim(x0, x6) = 0.13 sim(x3, x12) = 0.127 根据式 (2)、式 (3),可计算表 1 的决策信息系 统中 , 。 定义 4 邻域。对于任意的样本x ∈ U ,可以 通过设置相似度阈值 θ 的方式确定其邻域,样本 的邻域定义为 n(x, θ) = {y ∈ U|sim(x, y) ⩾ θ} (4) n(x0,0.5) = {x1, x2, x3, x4} 相似度阈值 θ 越小,样本的邻域越大。根据 表 1 所示的决策信息系统可以计算出 。 1.2 PageRank 模型 Web 中的网页通过超链接相互链接,PageRank 算法计算每个网页的 PageRank 分值。Page- ·552· 智 能 系 统 学 报 第 14 卷