正在加载图片...
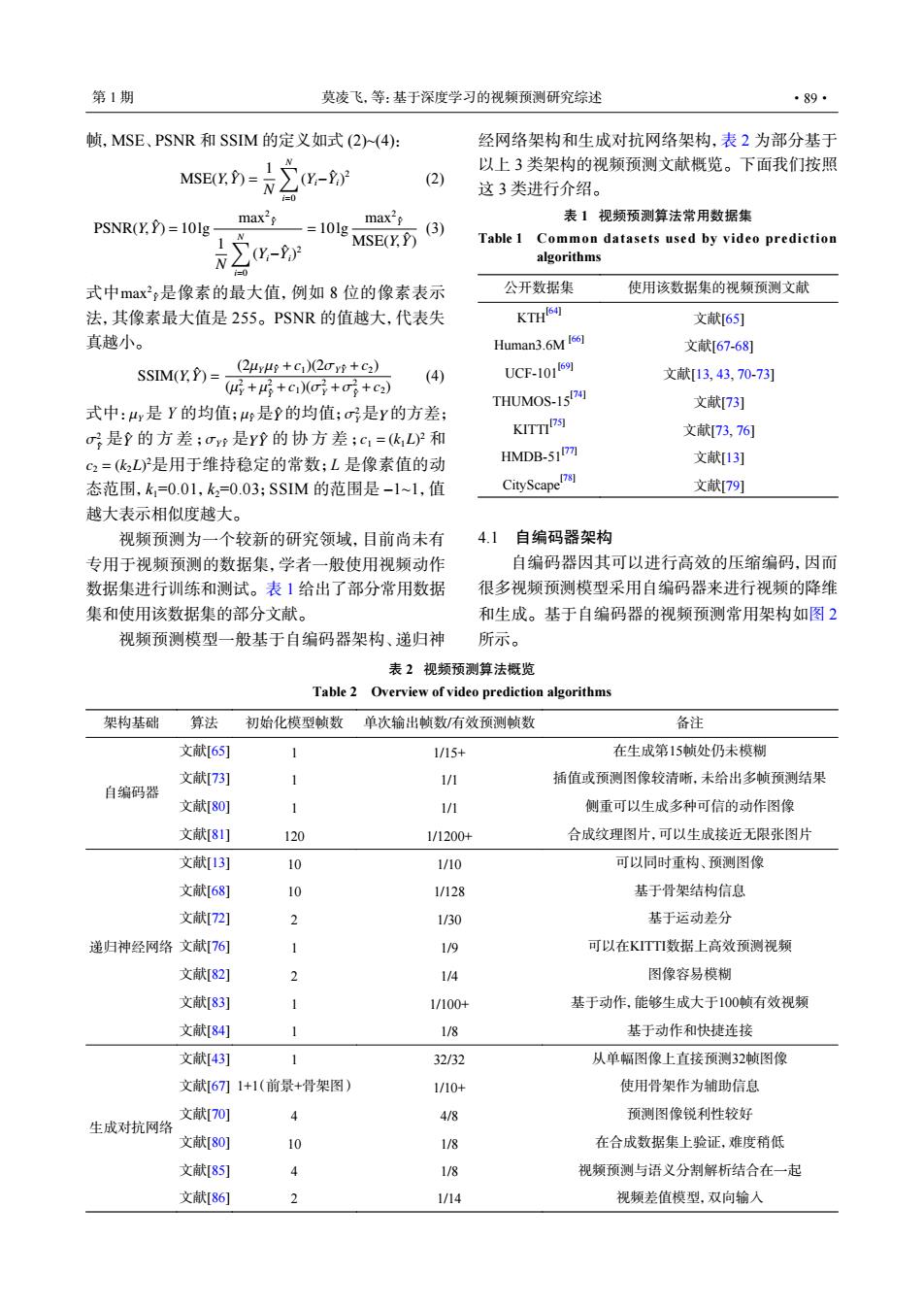
第1期 莫凌飞,等:基于深度学习的视频预测研究综述 ·89· 帧,MSE、PSNR和SSIM的定义如式(2)(4): 经网络架构和生成对抗网络架构,表2为部分基于 1 以上3类架构的视频预测文献概览。下面我们按照 MsE)=N∑Y- (2) =0 这3类进行介绍。 max2 max' 表1视频预测算法常用数据集 PSNR(YY)=101g- =10lg (3) Y- MSE(Y.P Table 1 Common datasets used by video prediction algorithms 0 式中max2,是像素的最大值,例如8位的像素表示 公开数据集 使用该数据集的视频预测文献 法,其像素最大值是255。PSNR的值越大,代表失 KTH6网 文献[65] 真越小。 Human3.6M166] 文献[67-68] SSIM(Y.Y)= (2μ44+C1)(2oy+c2) (4) UCP-10169 文献[13,43.70-73] (+5+c1)(+。+c2) THUMOS-15741 文献73) 式中:y是Y的均值;4是?的均值;σ是Y的方差; σ是?的方差;c是Y?的协方差;c1=(kL和 KITTP阿 文献73,76] c2=(2L)是用于维持稳定的常数;L是像素值的动 HMDB-51177 文献[13] 态范围,k=0.01,k2=0.03;SSIM的范围是-1~1,值 CityScape7网 文献79] 越大表示相似度越大。 视频预测为一个较新的研究领域,目前尚未有 4.1 自编码器架构 专用于视频预测的数据集,学者一般使用视频动作 自编码器因其可以进行高效的压缩编码,因而 数据集进行训练和测试。表1给出了部分常用数据 很多视频预测模型采用自编码器来进行视频的降维 集和使用该数据集的部分文献。 和生成。基于自编码器的视频预测常用架构如图2 视频预测模型一般基于自编码器架构、递归神 所示。 表2视频预测算法概览 Table 2 Overview of video prediction algorithms 架构基础 算法 初始化模型帧数 单次输出帧数/有效预测帧数 备注 文献[65] 1/15+ 在生成第15帧处仍未模糊 文献73] 1/1 插值或预测图像较清晰,未给出多帧预测结果 自编码器 文献80] 1/1 侧重可以生成多种可信的动作图像 文献[8] 120 1/1200+ 合成纹理图片,可以生成接近无限张图片 文献[13) 10 1/10 可以同时重构、预测图像 文献68) 10 1/128 基于骨架结构信息 文献[72] 2 1/30 基于运动差分 递归神经网络文献[76 1/9 可以在KITTI数据上高效预测视频 文献[82] 1/4 图像容易模糊 文献[83] 1/100+ 基于动作,能够生成大于100帧有效视频 文献[84 1/8 基于动作和快捷连接 文献43] 32/32 从单幅图像上直接预测32帧图像 文献67刀1+1(前景+骨架图) 1/10+ 使用骨架作为辅助信息 文献70) 4/8 预测图像锐利性较好 生成对抗网络 文献[80] 10 1/8 在合成数据集上验证,难度稍低 文献8) 1/8 视频预测与语义分割解析结合在一起 文献[86 2 1/14 视频差值模型,双向输入帧,MSE、PSNR 和 SSIM 的定义如式 (2)~(4): MSE(Y,Yˆ) = 1 N ∑N i=0 (Yi−Yˆ i) 2 (2) PSNR(Y,Yˆ) = 10lg max2 Yˆ 1 N ∑N i=0 (Yi−Yˆ i) 2 = 10lg max2 Yˆ MSE(Y,Yˆ) (3) max2 式中 Yˆ 是像素的最大值,例如 8 位的像素表示 法,其像素最大值是 255。PSNR 的值越大,代表失 真越小。 SSIM(Y,Yˆ) = (2µY µYˆ +c1)(2σYYˆ +c2) (µ 2 Y +µ 2 Yˆ +c1)(σ 2 Y +σ 2 Yˆ +c2) (4) µY µYˆ Yˆ σ 2 Y Y σ 2 Yˆ Yˆ σYYˆ YYˆ c1 = (k1L) 2 c2 = (k2L) 2 式中: 是 Y 的均值; 是 的均值; 是 的方差; 是 的方差; 是 的协方差; 和 是用于维持稳定的常数;L 是像素值的动 态范围,k1=0.01,k2=0.03;SSIM 的范围是 –1~1,值 越大表示相似度越大。 视频预测为一个较新的研究领域,目前尚未有 专用于视频预测的数据集,学者一般使用视频动作 数据集进行训练和测试。表 1 给出了部分常用数据 集和使用该数据集的部分文献。 视频预测模型一般基于自编码器架构、递归神 经网络架构和生成对抗网络架构,表 2 为部分基于 以上 3 类架构的视频预测文献概览。下面我们按照 这 3 类进行介绍。 4.1 自编码器架构 自编码器因其可以进行高效的压缩编码,因而 很多视频预测模型采用自编码器来进行视频的降维 和生成。基于自编码器的视频预测常用架构如图 2 所示。 表 1 视频预测算法常用数据集 Table 1 Common datasets used by video prediction algorithms 公开数据集 使用该数据集的视频预测文献 KTH[64] 文献[65] Human3.6M [66] 文献[67-68] UCF-101[69] 文献[13, 43, 70-73] THUMOS-15[74] 文献[73] KITTI[75] 文献[73, 76] HMDB-51[77] 文献[13] CityScape[78] 文献[79] 表 2 视频预测算法概览 Table 2 Overview of video prediction algorithms 架构基础 算法 初始化模型帧数 单次输出帧数/有效预测帧数 备注 自编码器 文献[65] 1 1/15+ 在生成第15帧处仍未模糊 文献[73] 1 1/1 插值或预测图像较清晰,未给出多帧预测结果 文献[80] 1 1/1 侧重可以生成多种可信的动作图像 文献[81] 120 1/1200+ 合成纹理图片,可以生成接近无限张图片 递归神经网络 文献[13] 10 1/10 可以同时重构、预测图像 文献[68] 10 1/128 基于骨架结构信息 文献[72] 2 1/30 基于运动差分 文献[76] 1 1/9 可以在KITTI数据上高效预测视频 文献[82] 2 1/4 图像容易模糊 文献[83] 1 1/100+ 基于动作,能够生成大于100帧有效视频 文献[84] 1 1/8 基于动作和快捷连接 生成对抗网络 文献[43] 1 32/32 从单幅图像上直接预测32帧图像 文献[67] 1+1(前景+骨架图) 1/10+ 使用骨架作为辅助信息 文献[70] 4 4/8 预测图像锐利性较好 文献[80] 10 1/8 在合成数据集上验证,难度稍低 文献[85] 4 1/8 视频预测与语义分割解析结合在一起 文献[86] 2 1/14 视频差值模型,双向输入 第 1 期 莫凌飞,等:基于深度学习的视频预测研究综述 ·89·