正在加载图片...
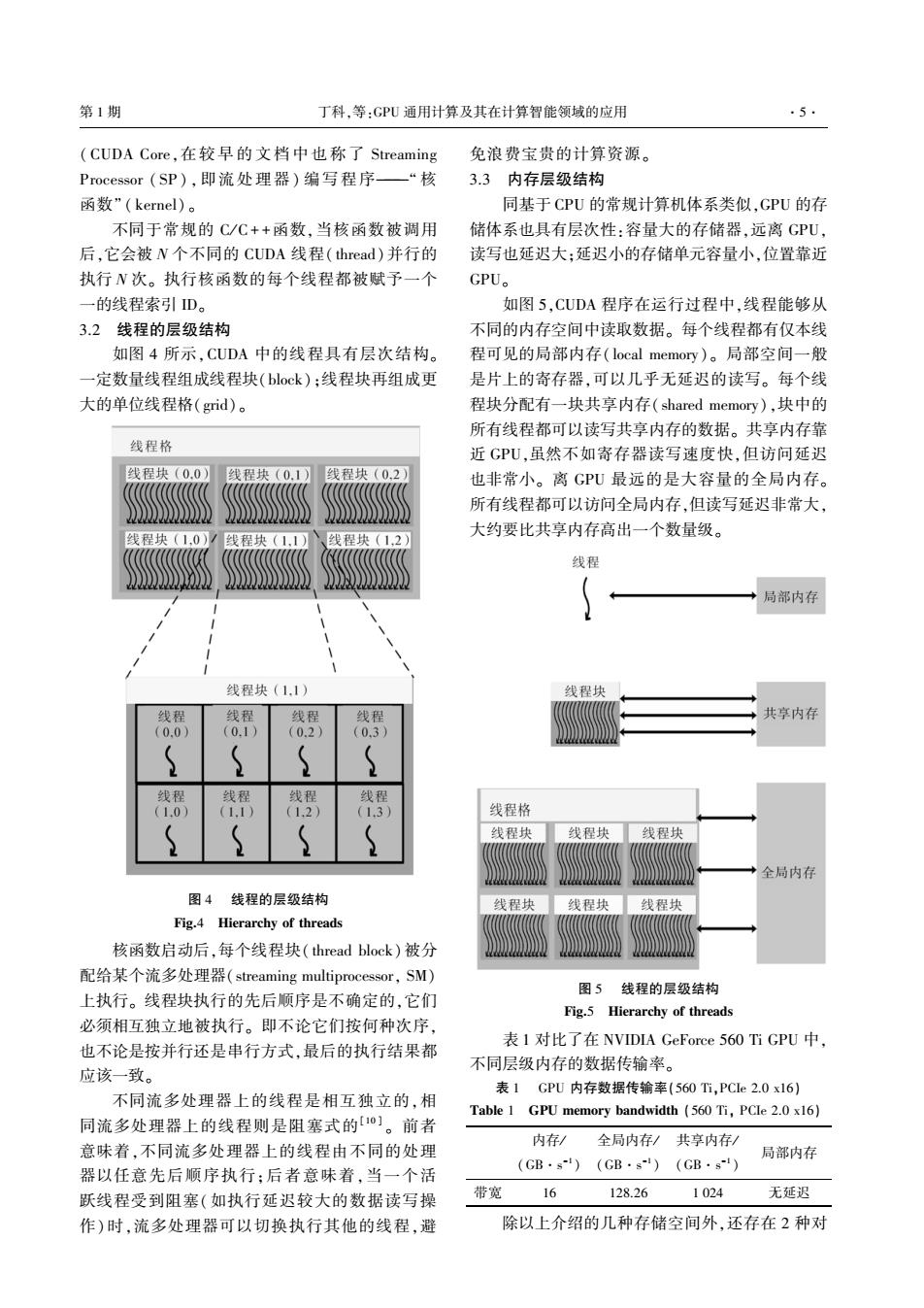
第1期 丁科,等:GPU通用计算及其在计算智能领域的应用 5 (CUDA Core,在较早的文档中也称了Streaming 免浪费宝贵的计算资源。 Processor(SP),即流处理器)编写程序一“核 3.3内存层级结构 函数”(kernel)。 同基于CPU的常规计算机体系类似,GPU的存 不同于常规的C/C++函数,当核函数被调用 储体系也具有层次性:容量大的存储器,远离GPU, 后,它会被N个不同的CUDA线程(thread)并行的 读写也延迟大:延迟小的存储单元容量小,位置靠近 执行N次。执行核函数的每个线程都被赋予一个 GPU。 一的线程索引D。 如图5,CUDA程序在运行过程中,线程能够从 3.2线程的层级结构 不同的内存空间中读取数据。每个线程都有仅本线 如图4所示,CUDA中的线程具有层次结构。 程可见的局部内存(local memory)。局部空间一般 一定数量线程组成线程块(block):线程块再组成更 是片上的寄存器,可以几乎无延迟的读写。每个线 大的单位线程格(grid)。 程块分配有一块共享内存(shared memory),块中的 所有线程都可以读写共享内存的数据。共享内存靠 线程格 近GPU,虽然不如寄存器读写速度快,但访问延迟 线程块(0.0 线程块(0.1) 线程块(0.2) 也非常小。离GPU最远的是大容量的全局内存。 所有线程都可以访问全局内存,但读写延迟非常大, 线程块 线程块(12 大约要比共享内存高出一个数量级。 线程 局部内存 线程块(1.1) 线程块 线程 线程 线程 线程 共享内存 (0.0) (0.1) (0.2) (0.3) ( 线程 线程 线程 线程 (1.0) (1.1) (1.2) (1.3) 线程格 线程块 线程块 线程块 全局内存 图4线程的层级结构 线程块 线程块 线程块 Fig.4 Hierarchy of threads 核函数启动后,每个线程块(thread block)被分 配给某个流多处理器(streaming multiprocessor,SM) 图5线程的层级结构 上执行。线程块执行的先后顺序是不确定的,它们 Fig.5 Hierarchy of threads 必须相互独立地被执行。即不论它们按何种次序, 也不论是按并行还是串行方式,最后的执行结果都 表1对比了在NVIDIA GeForce560 Ti GPU中, 不同层级内存的数据传输率。 应该一致。 表1GPU内存数据传输率(560T,PCIe2.0x16) 不同流多处理器上的线程是相互独立的,相 Table 1 GPU memory bandwidth (560 Ti,PCIe 2.0 x16) 同流多处理器上的线程则是阻塞式的]。前者 内存/ 全局内存/共享内存/ 意味着,不同流多处理器上的线程由不同的处理 局部内存 (GB·s)(GB·81)(GB·s) 器以任意先后顺序执行:后者意味着,当一个活 跃线程受到阻塞(如执行延迟较大的数据读写操 带宽 16 128.26 1024 无延迟 作)时,流多处理器可以切换执行其他的线程,避 除以上介绍的几种存储空间外,还存在2种对渊 悦哉阅粤 悦燥则藻袁在较早的文档中也称了 杂贼则藻葬皂蚤灶早 孕 则燥糟藻泽泽燥则 渊 杂孕 冤 袁即流处理器冤 编写程序要要要野 核 函数冶 渊 噪藻则灶藻造冤 遥 不同于常规的 悦辕悦 垣 垣函数袁当核函数被调用 后袁它会被 晕 个不同的 悦哉阅粤 线程渊 贼澡则藻葬凿冤 并行的 执行 晕 次遥 执行核函数的每个线程都被赋予一个 一的线程索引 陨阅遥 猿援圆摇 线程的层级结构 如图 源 所示袁悦哉阅粤 中的线程具有层次结构遥 一定数量线程组成线程块渊 遭造燥糟噪冤 曰线程块再组成更 大的单位线程格渊早则蚤凿冤 遥 图 源摇 线程的层级结构 云蚤早援源摇 匀蚤藻则葬则糟澡赠 燥枣 贼澡则藻葬凿泽 核函数启动后袁每个线程块渊贼澡则藻葬凿 遭造燥糟噪冤被分 配给某个流多处理器渊 泽贼则藻葬皂蚤灶早 皂怎造贼蚤责则燥糟藻泽泽燥则袁 杂酝冤 上执行遥 线程块执行的先后顺序是不确定的袁它们 必须相互独立地被执行遥 即不论它们按何种次序袁 也不论是按并行还是串行方式袁最后的执行结果都 应该一致遥 不同流多处理器上的线程是相互独立的袁相 同流多处理器上的线程则是阻塞式的咱 员园 暂 遥 前者 意味着袁不同流多处理器上的线程由不同的处理 器以任意先后顺序执行曰后者意味着袁当一个活 跃线程受到阻塞渊如执行延迟较大的数据读写操 作冤时袁流多处理器可以切换执行其他的线程袁避 免浪费宝贵的计算资源遥 猿援猿摇 内存层级结构 同基于 悦孕哉 的常规计算机体系类似袁郧孕哉 的存 储体系也具有层次性院容量大的存储器袁远离 郧孕哉袁 读写也延迟大曰延迟小的存储单元容量小袁位置靠近 郧孕哉遥 如图 缘袁悦哉阅粤 程序在运行过程中袁线程能够从 不同的内存空间中读取数据遥 每个线程都有仅本线 程可见的局部内存渊造燥糟葬造 皂藻皂燥则赠冤 遥 局部空间一般 是片上的寄存器袁可以几乎无延迟的读写遥 每个线 程块分配有一块共享内存渊 泽澡葬则藻凿 皂藻皂燥则赠冤 袁块中的 所有线程都可以读写共享内存的数据遥 共享内存靠 近 郧孕哉袁虽然不如寄存器读写速度快袁但访问延迟 也非常小遥 离 郧孕哉 最远的是大容量的全局内存遥 所有线程都可以访问全局内存袁但读写延迟非常大袁 大约要比共享内存高出一个数量级遥 图 缘摇 线程的层级结构 云蚤早援缘摇 匀蚤藻则葬则糟澡赠 燥枣 贼澡则藻葬凿泽 摇 摇 表 员 对比了在 晕灾陨阅陨粤 郧藻云燥则糟藻 缘远园 栽蚤 郧孕哉 中袁 不同层级内存的数据传输率遥 表 员摇 郧孕哉 内存数据传输率渊缘远园 栽蚤袁孕悦陨藻 圆援园 曾员远冤 栽葬遭造藻 员摇 郧孕哉 皂藻皂燥则赠 遭葬灶凿憎蚤凿贼澡 渊缘远园 栽蚤袁 孕悦陨藻 圆援园 曾员远冤 内存辕 渊郧月窑泽原员 冤 全局内存辕 渊郧月窑泽原员 冤 共享内存辕 渊郧月窑泽原员 冤 局部内存 带宽 员远 员圆愿援圆远 员 园圆源 无延迟 摇 摇 除以上介绍的几种存储空间外袁还存在 圆 种对 第 员 期摇摇摇摇摇摇摇摇摇摇摇摇摇摇 丁科袁等院郧孕哉 通用计算及其在计算智能领域的应用 窑缘窑