正在加载图片...
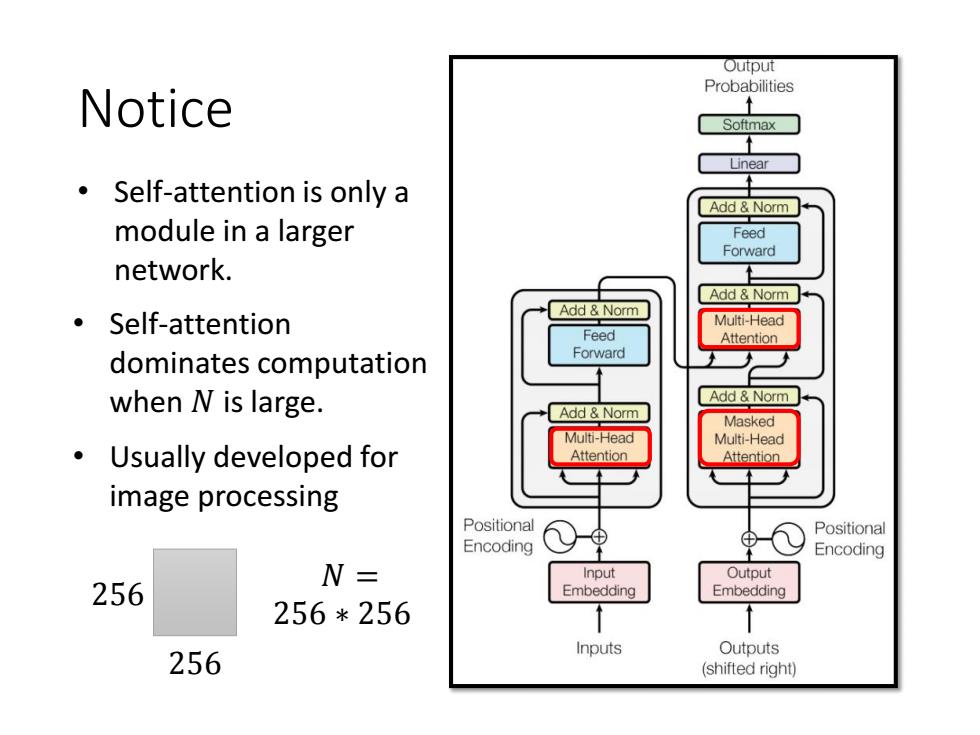
Output Probabilities Notice Softmax Self-attention is only a Add Norm module in a larger Feed Forward network. Add Norm Add Norm ·Self-attention Multi-Head Feed Attention dominates computation Forward when N is large. Add Norm Add Norm Masked Multi-Head Multi-Head Usually developed for Attention Attention image processing Positional Positional Encoding Encoding N= Input Output 256 Embedding Embedding 256*256 Inputs Outputs 256 (shifted right) Notice • Self-attention is only a module in a larger network. • Self-attention dominates computation when 𝑁 is large. • Usually developed for image processing 𝑁 = 256 ∗ 256 256 256