正在加载图片...
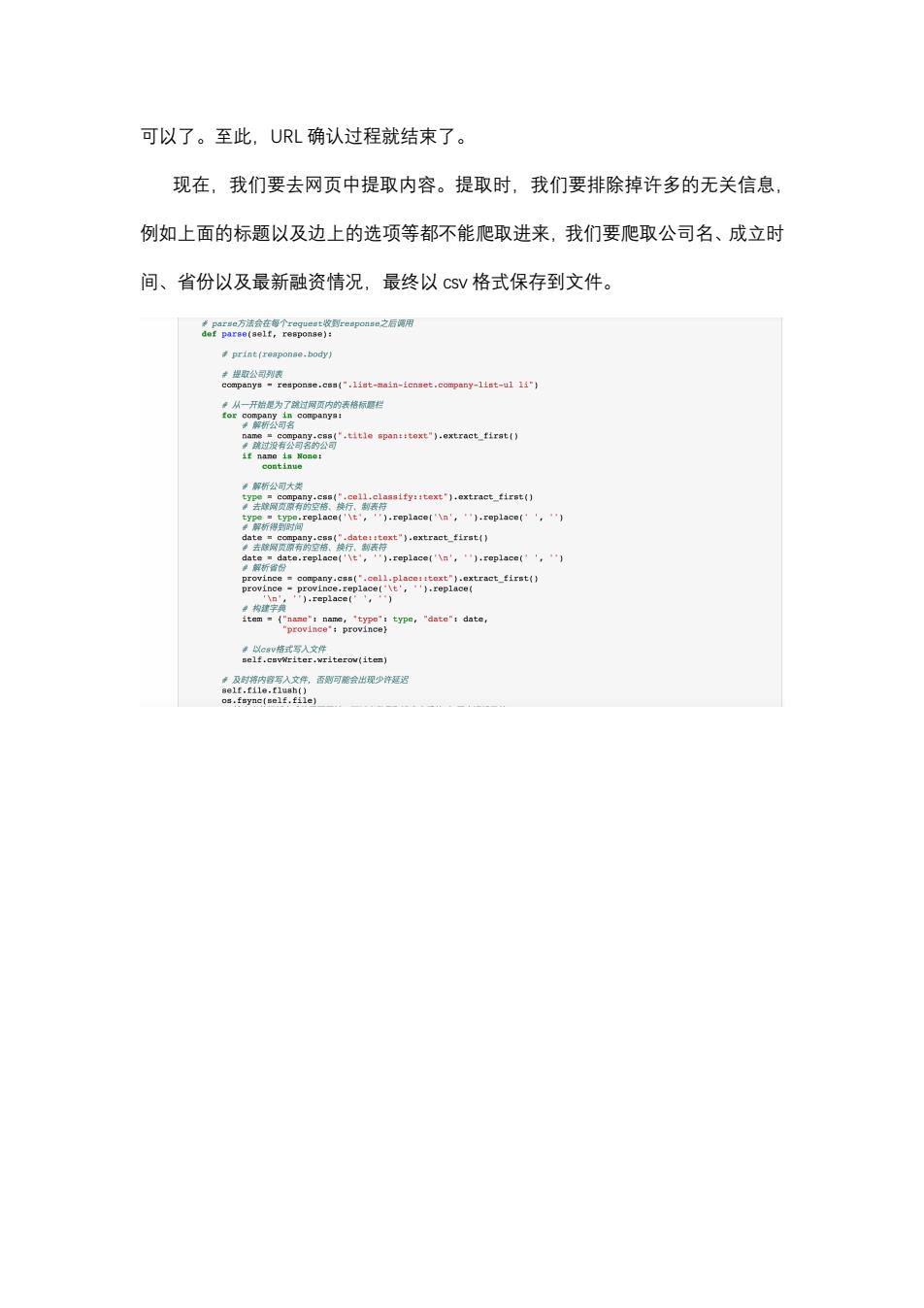
可以了。至此,URL确认过程就结束了。 现在,我们要去网页中提取内容。提取时,我们要排除掉许多的无关信息, 例如上面的标题以及边上的选项等都不能爬取进来,我们要爬取公司名、成立时 间、省份以及最新融资情况,最终以cSV格式保存到文件。 米Ppar#e方法会在每个regueet收到reapoase之后谓用 def parse(aelf,response): print(reaponae.body) 幸提取公司列 response.css(".list-main-icnset.company-list-ul li") ·从一开始是为了端过网页内的表格标圆栏 or9”3装oea79: 三unat1aoa0 解析公司大类 98美aat1.eret4eW 折得rp1acat,").cepiace('\n',.replace(',) date date.replace('t,).replace('\n',).replace(',) 单解析省份 province company.css('.cell.place::text").extract_first() provinceprovince.replace('\t',').replace( ).replace(,) e type,"date":date 以csv格式写入文件 self.csvWriter.writerov(item)可以了。至此,URL 确认过程就结束了。 现在,我们要去网页中提取内容。提取时,我们要排除掉许多的无关信息, 例如上面的标题以及边上的选项等都不能爬取进来,我们要爬取公司名、成立时 间、省份以及最新融资情况,最终以 濶瀆瀉 格式保存到文件