正在加载图片...
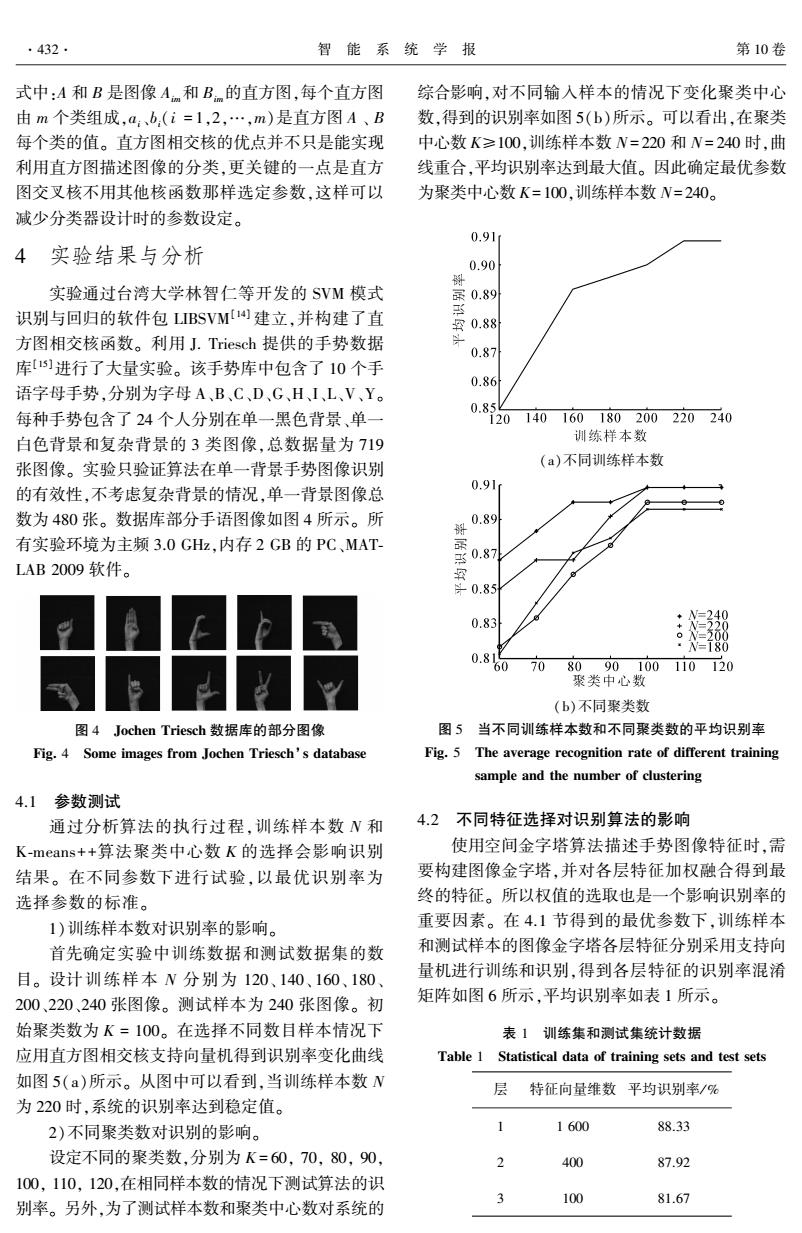
·432. 智能系统学报 第10卷 式中:A和B是图像Am和B的直方图,每个直方图 综合影响,对不同输入样本的情况下变化聚类中心 由m个类组成,a、b.(i=1,2,…,m)是直方图A、B 数,得到的识别率如图5(b)所示。可以看出,在聚类 每个类的值。直方图相交核的优点并不只是能实现 中心数K≥100,训练样本数N=220和N=240时,曲 利用直方图描述图像的分类,更关键的一点是直方 线重合,平均识别率达到最大值。因此确定最优参数 图交叉核不用其他核函数那样选定参数,这样可以 为聚类中心数K=100,训练样本数N=240。 减少分类器设计时的参数设定。 0.91 4 实验结果与分析 0.90 实验通过台湾大学林智仁等开发的SVM模式 录0.89 识别与回归的软件包LIBSVM4建立,并构建了直 0.88 方图相交核函数。利用J.Triesch提供的手势数据 0.87 库]进行了大量实验。该手势库中包含了10个手 0.86 语字母手势,分别为字母A、B、C、D、G、H、I、L、V、Y。 0.85 每种手势包含了24个人分别在单一黑色背景、单一 °120140160180200220240 白色背景和复杂背景的3类图像,总数据量为719 训练样本数 张图像。实验只验证算法在单一背景手势图像识别 (a)不同训练样本数 的有效性,不考虑复杂背景的情况,单一背景图像总 0.91 数为480张。数据库部分手语图像如图4所示。所 0.89 有实验环境为主频3.0GHz,内存2GB的PC、MAT- LAB2009软件。 ≤0.87 ÷0.85 0.83 0.85070 8090100110120 聚类中心数 (b)不同聚类数 图4 Jochen Triesch数据库的部分图像 图5当不同训练样本数和不同聚类数的平均识别率 Fig.4 Some images from Jochen Triesch's database Fig.5 The average recognition rate of different training sample and the number of clustering 4.1参数测试 通过分析算法的执行过程,训练样本数N和 4.2不同特征选择对识别算法的影响 K-means++算法聚类中心数K的选择会影响识别 使用空间金字塔算法描述手势图像特征时,需 结果。在不同参数下进行试验,以最优识别率为 要构建图像金字塔,并对各层特征加权融合得到最 选择参数的标准。 终的特征。所以权值的选取也是一个影响识别率的 1)训练样本数对识别率的影响。 重要因素。在4.1节得到的最优参数下,训练样本 首先确定实验中训练数据和测试数据集的数 和测试样本的图像金字塔各层特征分别采用支持向 目。设计训练样本N分别为120、140、160、180 量机进行训练和识别,得到各层特征的识别率混淆 200、220、240张图像。测试样本为240张图像。初 矩阵如图6所示,平均识别率如表1所示。 始聚类数为K=100。在选择不同数目样本情况下 表1训练集和测试集统计数据 应用直方图相交核支持向量机得到识别率变化曲线 Table 1 Statistical data of training sets and test sets 如图5(a)所示。从图中可以看到,当训练样本数N 层 特征向量维数平均识别率/% 为220时,系统的识别率达到稳定值。 2)不同聚类数对识别的影响。 1600 88.33 设定不同的聚类数,分别为K=60,70,80,90, 2 400 87.92 100,110,120,在相同样本数的情况下测试算法的识 3 100 81.67 别率。另外,为了测试样本数和聚类中心数对系统的式中:A 和 B 是图像 Aim和 Bim的直方图,每个直方图 由 m 个类组成,ai、bi(i = 1,2,…,m)是直方图 A 、 B 每个类的值。 直方图相交核的优点并不只是能实现 利用直方图描述图像的分类,更关键的一点是直方 图交叉核不用其他核函数那样选定参数,这样可以 减少分类器设计时的参数设定。 4 实验结果与分析 实验通过台湾大学林智仁等开发的 SVM 模式 识别与回归的软件包 LIBSVM [14] 建立,并构建了直 方图相交核函数。 利用 J. Triesch 提供的手势数据 库[15]进行了大量实验。 该手势库中包含了 10 个手 语字母手势,分别为字母 A、B、C、D、G、H、I、L、V、Y。 每种手势包含了 24 个人分别在单一黑色背景、单一 白色背景和复杂背景的 3 类图像,总数据量为 719 张图像。 实验只验证算法在单一背景手势图像识别 的有效性,不考虑复杂背景的情况,单一背景图像总 数为 480 张。 数据库部分手语图像如图 4 所示。 所 有实验环境为主频 3.0 GHz,内存 2 GB 的 PC、MAT⁃ LAB 2009 软件。 图 4 Jochen Triesch 数据库的部分图像 Fig. 4 Some images from Jochen Triesch’s database 4.1 参数测试 通过分析算法的执行过程,训练样本数 N 和 K⁃means++算法聚类中心数 K 的选择会影响识别 结果。 在不同参数下进行试验,以最优识别率为 选择参数的标准。 1)训练样本数对识别率的影响。 首先确定实验中训练数据和测试数据集的数 目。 设计训练样本 N 分别为 120、 140、 160、 180、 200、220、240 张图像。 测试样本为 240 张图像。 初 始聚类数为 K = 100。 在选择不同数目样本情况下 应用直方图相交核支持向量机得到识别率变化曲线 如图 5(a)所示。 从图中可以看到,当训练样本数 N 为 220 时,系统的识别率达到稳定值。 2)不同聚类数对识别的影响。 设定不同的聚类数,分别为 K = 60, 70, 80, 90, 100, 110, 120,在相同样本数的情况下测试算法的识 别率。 另外,为了测试样本数和聚类中心数对系统的 综合影响,对不同输入样本的情况下变化聚类中心 数,得到的识别率如图 5(b)所示。 可以看出,在聚类 中心数 K≥100,训练样本数 N= 220 和 N= 240 时,曲 线重合,平均识别率达到最大值。 因此确定最优参数 为聚类中心数 K= 100,训练样本数 N= 240。 (a)不同训练样本数 (b)不同聚类数 图 5 当不同训练样本数和不同聚类数的平均识别率 Fig. 5 The average recognition rate of different training sample and the number of clustering 4.2 不同特征选择对识别算法的影响 使用空间金字塔算法描述手势图像特征时,需 要构建图像金字塔,并对各层特征加权融合得到最 终的特征。 所以权值的选取也是一个影响识别率的 重要因素。 在 4.1 节得到的最优参数下,训练样本 和测试样本的图像金字塔各层特征分别采用支持向 量机进行训练和识别,得到各层特征的识别率混淆 矩阵如图 6 所示,平均识别率如表 1 所示。 表 1 训练集和测试集统计数据 Table 1 Statistical data of training sets and test sets 层 特征向量维数 平均识别率/ % 1 1 600 88.33 2 400 87.92 3 100 81.67 ·432· 智 能 系 统 学 报 第 10 卷