正在加载图片...
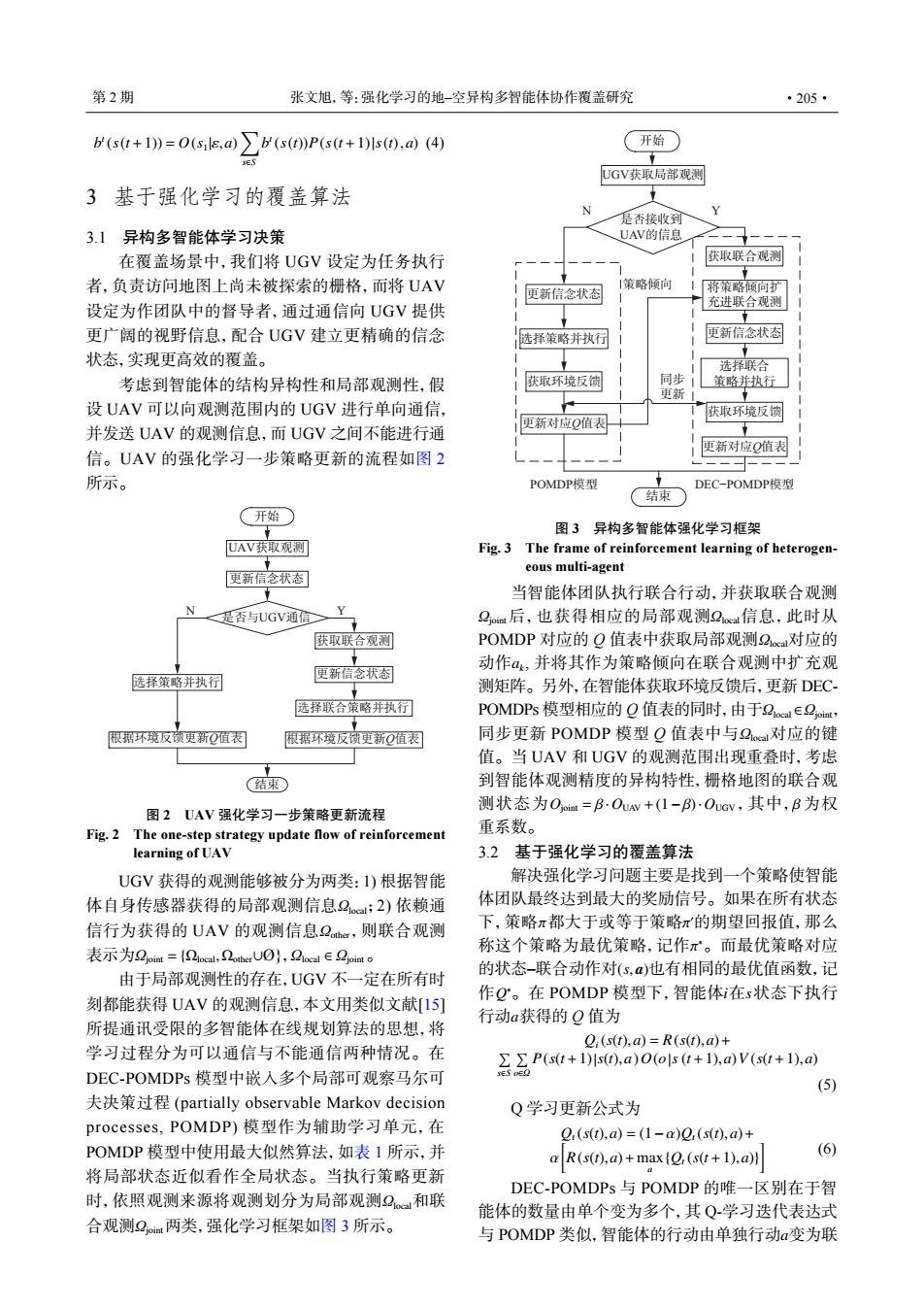
第2期 张文旭,等:强化学习的地-空异构多智能体协作覆盖研究 ·205· b(s(t+1))=O(sils,a) b(s(t)P(s(t+1)s(),ad)(4) 开始 UGV获取局部观测 3基于强化学习的覆盖算法 是否接收到 3.1异构多智能体学习决策 UAV的信息 在覆盖场景中,我们将UGV设定为任务执行 获取联合观测 者,负责访问地图上尚未被探索的栅格,而将UAV 1策略倾向 更新信念状态 将策略倾扩 设定为作团队中的督导者,通过通信向UGV提供 充进联合观测 更广阔的视野信息,配合UGV建立更精确的信念 选择策略并执行 更新信念状态 状态,实现更高效的覆盖。 选择联合 考虑到智能体的结构异构性和局部观测性,假 获取环境反馈 同步 策略并热行■ 更新 设UAV可以向观测范围内的UGV进行单向通信, 获取环境反馈 并发送UAV的观测信息,而UGV之间不能进行通 更新对应Q值表 更新对应Q值表 信。UAV的强化学习一步策略更新的流程如图2 所示。 POMDP模型 DEC-POMDP模型 结束 (开始 图3异构多智能体强化学习框架 UAV获取观测 Fig.3 The frame of reinforcement learning of heterogen- eous multi-agent 更新信念状态 当智能体团队执行联合行动,并获取联合观测 N Y 是否与UGV通信≥ 2or后,也获得相应的局部观测2e信息,此时从 获取联合观测 POMDP对应的Q值表中获取局部观测2c对应的 动作a,并将其作为策略倾向在联合观测中扩充观 选择策略并执行 更新信念状态 测矩阵。另外,在智能体获取环境反馈后,更新DEC 选择联合策略并执行 POMDPs模型相应的Q值表的同时,由于2oeal∈2oiat, 根据环境反锁更新Q值表 限据环境反窗更新Q值表 同步更新POMDP模型Q值表中与2a对应的键 值。当UAV和UGV的观测范围出现重叠时,考虑 结束 到智能体观测精度的异构特性,栅格地图的联合观 图2UAV强化学习一步策略更新流程 测状态为Ooi=B.Ouw+(1-)·Ocv,其中,B为权 Fig.2 The one-step strategy update flow of reinforcement 重系数。 learning of UAV 3.2基于强化学习的覆盖算法 UGV获得的观测能够被分为两类:1)根据智能 解决强化学习问题主要是找到一个策略使智能 体自身传感器获得的局部观测信息2;2)依赖通 体团队最终达到最大的奖励信号。如果在所有状态 信行为获得的UAV的观测信息2a,则联合观测 下,策略π都大于或等于策略π的期望回报值,那么 表示为2oiat={2oeal,2berU0O},2 ca∈2 jont 称这个策略为最优策略,记作π。而最优策略对应 由于局部观测性的存在,UGV不一定在所有时 的状态-联合动作对(s,α)也有相同的最优值函数,记 刻都能获得UAV的观测信息,本文用类似文献[15] 作Q。在POMDP模型下,智能体在s状态下执行 行动a获得的Q值为 所提通讯受限的多智能体在线规划算法的思想,将 Q(s(),a)=R(s(t),a)+ 学习过程分为可以通信与不能通信两种情况。在 P(s(t+1)s(t),a)o(ols (1+1),a)v(s(t+1),a) DEC-POMDPs模型中嵌入多个局部可观察马尔可 (5) 夫决策过程(partially observable Markov decision Q学习更新公式为 processes,.POMDP)模型作为辅助学习单元,在 Q(s(t),a=(1-a)2(s(t),a))+ POMDP模型中使用最大似然算法,如表1所示,并 a R(s(t),a)+max(Q,(s(t+1),a)] (6) 将局部状态近似看作全局状态。当执行策略更新 DEC-POMDPs与POMDP的唯一区别在于智 时,依照观测来源将观测划分为局部观测2和联 能体的数量由单个变为多个,其Q-学习迭代表达式 合观测2两类,强化学习框架如图3所示。 与POMDP类似,智能体的行动由单独行动a变为联b t (s(t+1)) = O(s1|ε,a) ∑ s∈S b t (s(t))P(s(t+1)|s(t),a) (4) 3 基于强化学习的覆盖算法 3.1 异构多智能体学习决策 在覆盖场景中,我们将 UGV 设定为任务执行 者,负责访问地图上尚未被探索的栅格,而将 UAV 设定为作团队中的督导者,通过通信向 UGV 提供 更广阔的视野信息,配合 UGV 建立更精确的信念 状态,实现更高效的覆盖。 考虑到智能体的结构异构性和局部观测性,假 设 UAV 可以向观测范围内的 UGV 进行单向通信, 并发送 UAV 的观测信息,而 UGV 之间不能进行通 信。UAV 的强化学习一步策略更新的流程如图 2 所示。 UAV㧧ਆ㿲⍻ ᴤᯠؑᘥ⣦ᘱ 㧧ਆ㚄ਸ㿲⍻ ᴤᯠؑᘥ⣦ᘱ 䘹ᤙ㚄ਸㆆ⮕ᒦᢗ㹼 䘹ᤙㆆ⮕ᒦᢗ㹼 N Y ᔰ 㔃ᶏ ᱟоUGV䙊ؑ ṩᦞ⧟ຳ৽侸ᴤᯠQ٬㺘 ṩᦞ⧟ຳ৽侸ᴤᯠQ٬㺘 图 2 UAV 强化学习一步策略更新流程 Fig. 2 The one-step strategy update flow of reinforcement learning of UAV Ωlocal Ωother Ωjoint = {Ωlocal,Ωother∪ Ωlocal ∈ Ωjoint UGV 获得的观测能够被分为两类:1) 根据智能 体自身传感器获得的局部观测信息 ;2) 依赖通 信行为获得的 UAV 的观测信息 ,则联合观测 表示为 Ø}, 。 Ωlocal Ωjoint 由于局部观测性的存在,UGV 不一定在所有时 刻都能获得 UAV 的观测信息,本文用类似文献[15] 所提通讯受限的多智能体在线规划算法的思想,将 学习过程分为可以通信与不能通信两种情况。在 DEC-POMDPs 模型中嵌入多个局部可观察马尔可 夫决策过程 (partially observable Markov decision processes, POMDP) 模型作为辅助学习单元,在 POMDP 模型中使用最大似然算法,如表 1 所示,并 将局部状态近似看作全局状态。当执行策略更新 时,依照观测来源将观测划分为局部观测 和联 合观测 两类,强化学习框架如图 3 所示。 ᰠԍᔡ⟢ᔭ N Y ᐬ UGV㣣ंᅬ䘔㻮≷ ᭛॒ᣑᩢݜ UAV⮰ԍᖛ 㣣ं㖀ऴ㻮≷ ᄲも⪑ժऽផ ≶䔇㖀ऴ㻮ٱ ᰠԍᔡ⟢ᔭ 䔵᠕㖀ऴ も⪑Ꭲន㵸 ᰠᄥᏀQը㶔 㣣ं⣛දࣹ亴 सₑ ᰠ も⪑ժऽ ㏿ POMDPὍಷ DEC−POMDPὍಷ ᰠᄥᏀQը㶔 㣣ं⣛දࣹ亴 䔵᠕も⪑Ꭲន㵸 图 3 异构多智能体强化学习框架 Fig. 3 The frame of reinforcement learning of heterogeneous multi-agent Ωjoint Ωlocal Ωlocal ak Ωlocal ∈Ωjoint Ωlocal Ojoint = β ·OUAV +(1−β)·OUGV β 当智能体团队执行联合行动,并获取联合观测 后,也获得相应的局部观测 信息,此时从 POMDP 对应的 Q 值表中获取局部观测 对应的 动作 , 并将其作为策略倾向在联合观测中扩充观 测矩阵。另外,在智能体获取环境反馈后,更新 DECPOMDPs 模型相应的 Q 值表的同时,由于 , 同步更新 POMDP 模型 Q 值表中与 对应的键 值。当 UAV 和 UGV 的观测范围出现重叠时,考虑 到智能体观测精度的异构特性,栅格地图的联合观 测状态为 ,其中, 为权 重系数。 3.2 基于强化学习的覆盖算法 π π ′ π ∗ (s, a) Q ∗ i s a 解决强化学习问题主要是找到一个策略使智能 体团队最终达到最大的奖励信号。如果在所有状态 下,策略 都大于或等于策略 的期望回报值,那么 称这个策略为最优策略,记作 。而最优策略对应 的状态–联合动作对 也有相同的最优值函数,记 作 。在 POMDP 模型下,智能体 在 状态下执行 行动 获得的 Q 值为 Qi(s(t),a) = R(s(t),a)+ ∑ s∈S ∑ o∈Ω P(s(t+1)|s(t),a)O(o|s (t+1),a)V (s(t+1),a) (5) Q 学习更新公式为 Qt (s(t),a) = (1−α)Qt (s(t),a)+ α [ R(s(t),a)+max a {Qt (s(t+1),a)} ] (6) a DEC-POMDPs 与 POMDP 的唯一区别在于智 能体的数量由单个变为多个,其 Q-学习迭代表达式 与 POMDP 类似,智能体的行动由单独行动 变为联 第 2 期 张文旭,等:强化学习的地–空异构多智能体协作覆盖研究 ·205·