正在加载图片...
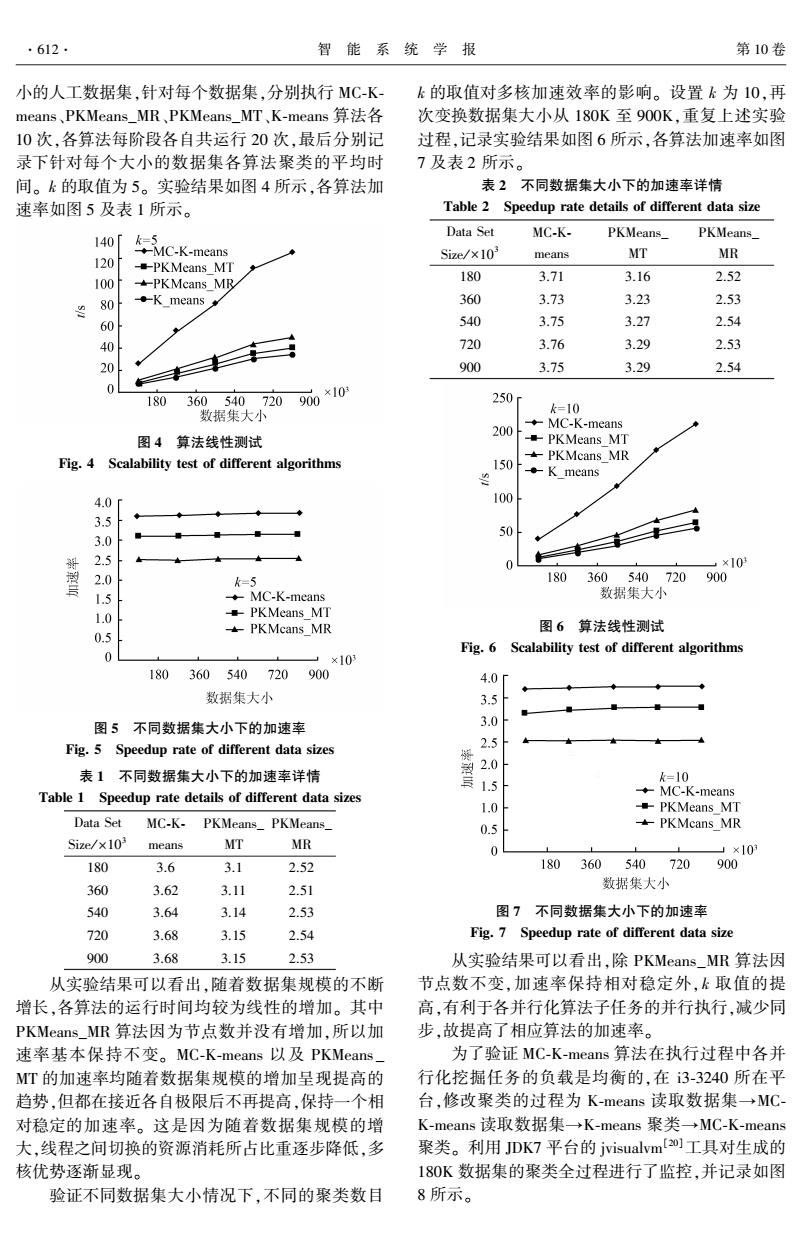
.612. 智能系统学报 第10卷 小的人工数据集,针对每个数据集,分别执行MC-K- k的取值对多核加速效率的影响。设置k为10,再 means、PKMeans_.MR、PKMeans_MT、K-means算法各 次变换数据集大小从180K至900K,重复上述实验 10次,各算法每阶段各自共运行20次,最后分别记 过程,记录实验结果如图6所示,各算法加速率如图 录下针对每个大小的数据集各算法聚类的平均时 7及表2所示。 间。k的取值为5。实验结果如图4所示,各算法加 表2不同数据集大小下的加速率详情 速率如图5及表1所示。 Table 2 Speedup rate details of different data size 140「 Data Set MC-K- k=5 PKMeans_ PKMeans_ ◆+-MC-K-neans 120 Size/x103 means MT MR -PKMeans_MT 100 PKMcans MR 180 3.71 3.16 2.52 80 ◆-K means 360 3.73 3.23 2.53 60 540 3.75 3.27 2.54 40 720 3.76 3.29 2.53 20 900 3.75 3.29 2.54 0 180 360540720900×10 250r 数据集大小 k=10 200 ◆MC-K-means 图4算法线性测试 -PKMeans MT Fig.4 Scalability test of different algorithms PKMcans MR 150 T◆K means 4.0f 100 3.5 50 3.0 哥 2.5 0 ,×10 2.0 k=5 180360540720900 1.5 ◆MC-K-means 数据集大小 1.0 -PKMeans_MT PKMcans MR 图6算法线性测试 0.5 Fig.6 Scalability test of different algorithms 0 →×10 180360540720900 4.0「 数据集大小 3.5 图5不同数据集大小下的加速率 3.0 Fig.5 Speedup rate of different data sizes 2.5 表1不同数据集大小下的加速率详情 2.0 1.5 k=10 Table 1 Speedup rate details of different data sizes -◆MC-K-means 1.0 -PKMeans MT Data Set MC-K- PKMeans PKMeans_ 0.5 PKMcans_MR Size/×103 means MT MR ×10 180 3.6 3.1 2.52 180 360540720900 360 3.62 3.11 2.51 数据集大小 540 3.64 3.14 2.53 图7不同数据集大小下的加速率 720 3.68 3.15 2.54 Fig.7 Speedup rate of different data size 900 3.68 3.15 2.53 从实验结果可以看出,除PKMeans_.MR算法因 从实验结果可以看出,随着数据集规模的不断 节点数不变,加速率保持相对稳定外,k取值的提 增长,各算法的运行时间均较为线性的增加。其中 高,有利于各并行化算法子任务的并行执行,减少同 PKMeans_.MR算法因为节点数并没有增加,所以加 步,故提高了相应算法的加速率。 速率基本保持不变。MC-K-means以及PKMeans_ 为了验证MC-K-means算法在执行过程中各并 T的加速率均随着数据集规模的增加呈现提高的 行化挖掘任务的负载是均衡的,在3-3240所在平 趋势,但都在接近各自极限后不再提高,保持一个相 台,修改聚类的过程为K-means读取数据集→MC 对稳定的加速率。这是因为随着数据集规模的增 K-means读取数据集→K-means聚类→MC-K-means 大,线程之间切换的资源消耗所占比重逐步降低,多 聚类。利用JDK7平台的jvisualvm20]工具对生成的 核优势逐渐显现。 180K数据集的聚类全过程进行了监控,并记录如图 验证不同数据集大小情况下,不同的聚类数目 8所示。小的人工数据集,针对每个数据集,分别执行 MC⁃K⁃ means、PKMeans_MR、PKMeans_MT、K⁃means 算法各 10 次,各算法每阶段各自共运行 20 次,最后分别记 录下针对每个大小的数据集各算法聚类的平均时 间。 k 的取值为 5。 实验结果如图 4 所示,各算法加 速率如图 5 及表 1 所示。 图 4 算法线性测试 Fig. 4 Scalability test of different algorithms 图 5 不同数据集大小下的加速率 Fig. 5 Speedup rate of different data sizes 表 1 不同数据集大小下的加速率详情 Table 1 Speedup rate details of different data sizes Data Set Size / ×10 3 MC⁃K⁃ means PKMeans_ MT PKMeans_ MR 180 3.6 3.1 2.52 360 3.62 3.11 2.51 540 3.64 3.14 2.53 720 3.68 3.15 2.54 900 3.68 3.15 2.53 从实验结果可以看出,随着数据集规模的不断 增长,各算法的运行时间均较为线性的增加。 其中 PKMeans_MR 算法因为节点数并没有增加,所以加 速率基本保持不变。 MC⁃K⁃means 以及 PKMeans _ MT 的加速率均随着数据集规模的增加呈现提高的 趋势,但都在接近各自极限后不再提高,保持一个相 对稳定的加速率。 这是因为随着数据集规模的增 大,线程之间切换的资源消耗所占比重逐步降低,多 核优势逐渐显现。 验证不同数据集大小情况下,不同的聚类数目 k 的取值对多核加速效率的影响。 设置 k 为 10,再 次变换数据集大小从 180K 至 900K,重复上述实验 过程,记录实验结果如图 6 所示,各算法加速率如图 7 及表 2 所示。 表 2 不同数据集大小下的加速率详情 Table 2 Speedup rate details of different data size Data Set Size / ×10 3 MC⁃K⁃ means PKMeans_ MT PKMeans_ MR 180 3.71 3.16 2.52 360 3.73 3.23 2.53 540 3.75 3.27 2.54 720 3.76 3.29 2.53 900 3.75 3.29 2.54 图 6 算法线性测试 Fig. 6 Scalability test of different algorithms 图 7 不同数据集大小下的加速率 Fig. 7 Speedup rate of different data size 从实验结果可以看出,除 PKMeans_MR 算法因 节点数不变,加速率保持相对稳定外,k 取值的提 高,有利于各并行化算法子任务的并行执行,减少同 步,故提高了相应算法的加速率。 为了验证 MC⁃K⁃means 算法在执行过程中各并 行化挖掘任务的负载是均衡的,在 i3⁃3240 所在平 台,修改聚类的过程为 K⁃means 读取数据集→MC⁃ K⁃means 读取数据集→K⁃means 聚类→MC⁃K⁃means 聚类。 利用 JDK7 平台的 jvisualvm [20]工具对生成的 180K 数据集的聚类全过程进行了监控,并记录如图 8 所示。 ·612· 智 能 系 统 学 报 第 10 卷