正在加载图片...
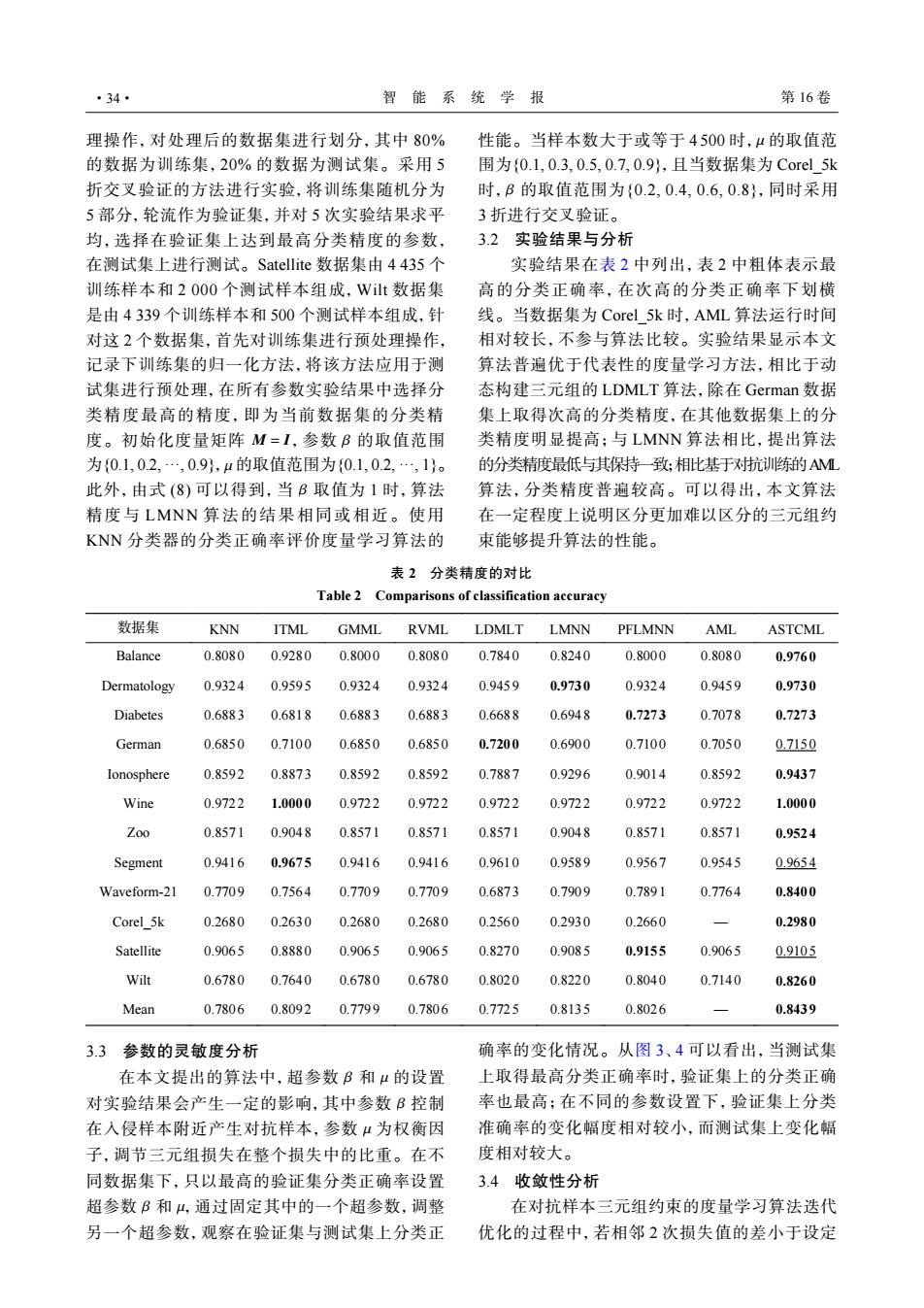
·34· 智能系统学报 第16卷 理操作,对处理后的数据集进行划分,其中80% 性能。当样本数大于或等于4500时,μ的取值范 的数据为训练集,20%的数据为测试集。采用5 围为{0.1,0.3,0.5,0.7,0.9},且当数据集为Corel5k 折交叉验证的方法进行实验,将训练集随机分为 时,B的取值范围为{0.2,0.4,0.6,0.8},同时采用 5部分,轮流作为验证集,并对5次实验结果求平 3折进行交叉验证。 均,选择在验证集上达到最高分类精度的参数,3.2实验结果与分析 在测试集上进行测试。Satellite数据集由4435个 实验结果在表2中列出,表2中粗体表示最 训练样本和2000个测试样本组成,Wit数据集 高的分类正确率,在次高的分类正确率下划横 是由4339个训练样本和500个测试样本组成,针 线。当数据集为Corel5k时,AML算法运行时间 对这2个数据集,首先对训练集进行预处理操作, 相对较长,不参与算法比较。实验结果显示本文 记录下训练集的归一化方法,将该方法应用于测 算法普遍优于代表性的度量学习方法,相比于动 试集进行预处理,在所有参数实验结果中选择分 态构建三元组的LDMLT算法,除在German数据 类精度最高的精度,即为当前数据集的分类精 集上取得次高的分类精度,在其他数据集上的分 度。初始化度量矩阵M=I,参数B的取值范围 类精度明显提高;与LMNN算法相比,提出算法 为{0.1,02,…,0.9},μ的取值范围为{0.1,02,…,1}。 的分类精度最低与其保特一致;相比基于对抗训练的AM 此外,由式(8)可以得到,当B取值为1时,算法 算法,分类精度普遍较高。可以得出,本文算法 精度与LMNN算法的结果相同或相近。使用 在一定程度上说明区分更加难以区分的三元组约 KNN分类器的分类正确率评价度量学习算法的 束能够提升算法的性能。 表2分类精度的对比 Table 2 Comparisons of classification accuracy 数据集 KNN ITML GMML RVML LDMLT LMNN PFLMNN AML ASTCML Balance 0.8080 0.9280 0.8000 0.8080 0.7840 0.8240 0.8000 0.8080 0.9760 Dermatology 0.9324 0.9595 0.9324 0.9324 0.9459 0.9730 0.9324 0.9459 0.9730 Diabetes 0.6883 0.6818 0.6883 0.6883 0.6688 0.6948 0.7273 0.7078 0.7273 German 0.6850 0.7100 0.6850 0.6850 0.7200 0.6900 0.7100 0.7050 0.7150 lonosphere 0.8592 0.8873 0.8592 0.8592 0.7887 0.9296 0.9014 0.8592 0.9437 Wine 0.9722 1.0000 0.9722 0.9722 0.9722 0.9722 0.9722 0.9722 1.0000 Z00 0.8571 0.9048 0.8571 0.8571 0.8571 0.9048 0.8571 0.8571 0.9524 Segment 0.9416 0.9675 0.9416 0.9416 0.9610 0.9589 0.9567 0.9545 0.9654 Waveform-21 0.7709 0.7564 0.7709 0.7709 0.6873 0.7909 0.7891 0.7764 0.8400 Corel 5k 0.2680 0.2630 0.2680 0.2680 0.2560 0.2930 0.2660 0.2980 Satellite 0.9065 0.8880 0.9065 0.9065 0.8270 0.9085 0.9155 0.9065 0.9105 Wilt 0.6780 0.7640 0.6780 0.6780 0.8020 0.8220 0.8040 0.7140 0.8260 Mean 0.7806 0.8092 0.7799 0.7806 0.7725 0.8135 0.8026 0.8439 3.3参数的灵敏度分析 确率的变化情况。从图3、4可以看出,当测试集 在本文提出的算法中,超参数B和μ的设置 上取得最高分类正确率时,验证集上的分类正确 对实验结果会产生一定的影响,其中参数B控制 率也最高:在不同的参数设置下,验证集上分类 在入侵样本附近产生对抗样本,参数“为权衡因 准确率的变化幅度相对较小,而测试集上变化幅 子,调节三元组损失在整个损失中的比重。在不 度相对较大。 同数据集下,只以最高的验证集分类正确率设置 3.4收敛性分析 超参数B和4,通过固定其中的一个超参数,调整 在对抗样本三元组约束的度量学习算法迭代 另一个超参数,观察在验证集与测试集上分类正 优化的过程中,若相邻2次损失值的差小于设定M = I β µ β 理操作,对处理后的数据集进行划分,其中 80% 的数据为训练集,20% 的数据为测试集。采用 5 折交叉验证的方法进行实验,将训练集随机分为 5 部分,轮流作为验证集,并对 5 次实验结果求平 均,选择在验证集上达到最高分类精度的参数, 在测试集上进行测试。Satellite 数据集由 4 435 个 训练样本和 2 000 个测试样本组成,Wilt 数据集 是由 4 339 个训练样本和 500 个测试样本组成,针 对这 2 个数据集,首先对训练集进行预处理操作, 记录下训练集的归一化方法,将该方法应用于测 试集进行预处理,在所有参数实验结果中选择分 类精度最高的精度,即为当前数据集的分类精 度。初始化度量矩阵 ,参数 的取值范围 为{0.1, 0.2, ···, 0.9}, 的取值范围为{0.1, 0.2, ···, 1}。 此外,由式 (8) 可以得到,当 取值为 1 时,算法 精度与 LMNN 算法的结果相同或相近。使用 KNN 分类器的分类正确率评价度量学习算法的 µ β 性能。当样本数大于或等于 4 500 时, 的取值范 围为{0.1, 0.3, 0.5, 0.7, 0.9},且当数据集为 Corel_5k 时, 的取值范围为{0.2, 0.4, 0.6, 0.8},同时采用 3 折进行交叉验证。 3.2 实验结果与分析 实验结果在表 2 中列出,表 2 中粗体表示最 高的分类正确率,在次高的分类正确率下划横 线。当数据集为 Corel_5k 时,AML 算法运行时间 相对较长,不参与算法比较。实验结果显示本文 算法普遍优于代表性的度量学习方法,相比于动 态构建三元组的 LDMLT 算法,除在 German 数据 集上取得次高的分类精度,在其他数据集上的分 类精度明显提高;与 LMNN 算法相比,提出算法 的分类精度最低与其保持一致;相比基于对抗训练的AML 算法,分类精度普遍较高。可以得出,本文算法 在一定程度上说明区分更加难以区分的三元组约 束能够提升算法的性能。 表 2 分类精度的对比 Table 2 Comparisons of classification accuracy 数据集 KNN ITML GMML RVML LDMLT LMNN PFLMNN AML ASTCML Balance 0.8080 0.9280 0.800 0 0.808 0 0.784 0 0.824 0 0.8000 0.808 0 0.976 0 Dermatology 0.9324 0.9595 0.932 4 0.932 4 0.945 9 0.973 0 0.9324 0.945 9 0.973 0 Diabetes 0.6883 0.6818 0.688 3 0.688 3 0.668 8 0.694 8 0.7273 0.707 8 0.727 3 German 0.6850 0.7100 0.685 0 0.685 0 0.720 0 0.690 0 0.7100 0.705 0 0.715 0 Ionosphere 0.8592 0.8873 0.859 2 0.859 2 0.788 7 0.929 6 0.9014 0.859 2 0.943 7 Wine 0.9722 1.0000 0.972 2 0.972 2 0.972 2 0.972 2 0.9722 0.972 2 1.000 0 Zoo 0.8571 0.9048 0.857 1 0.857 1 0.857 1 0.904 8 0.8571 0.857 1 0.952 4 Segment 0.9416 0.9675 0.941 6 0.941 6 0.961 0 0.958 9 0.9567 0.954 5 0.965 4 Waveform-21 0.7709 0.7564 0.770 9 0.770 9 0.687 3 0.790 9 0.7891 0.776 4 0.840 0 Corel_5k 0.2680 0.2630 0.268 0 0.268 0 0.256 0 0.293 0 0.2660 — 0.298 0 Satellite 0.9065 0.8880 0.906 5 0.906 5 0.827 0 0.908 5 0.9155 0.906 5 0.910 5 Wilt 0.6780 0.7640 0.678 0 0.678 0 0.802 0 0.822 0 0.8040 0.714 0 0.826 0 Mean 0.7806 0.8092 0.779 9 0.780 6 0.772 5 0.813 5 0.8026 — 0.843 9 3.3 参数的灵敏度分析 β µ β µ β µ 在本文提出的算法中,超参数 和 的设置 对实验结果会产生一定的影响,其中参数 控制 在入侵样本附近产生对抗样本,参数 为权衡因 子,调节三元组损失在整个损失中的比重。在不 同数据集下,只以最高的验证集分类正确率设置 超参数 和 ,通过固定其中的一个超参数,调整 另一个超参数,观察在验证集与测试集上分类正 确率的变化情况。从图 3、4 可以看出,当测试集 上取得最高分类正确率时,验证集上的分类正确 率也最高;在不同的参数设置下,验证集上分类 准确率的变化幅度相对较小,而测试集上变化幅 度相对较大。 3.4 收敛性分析 在对抗样本三元组约束的度量学习算法迭代 优化的过程中,若相邻 2 次损失值的差小于设定 ·34· 智 能 系 统 学 报 第 16 卷