正在加载图片...
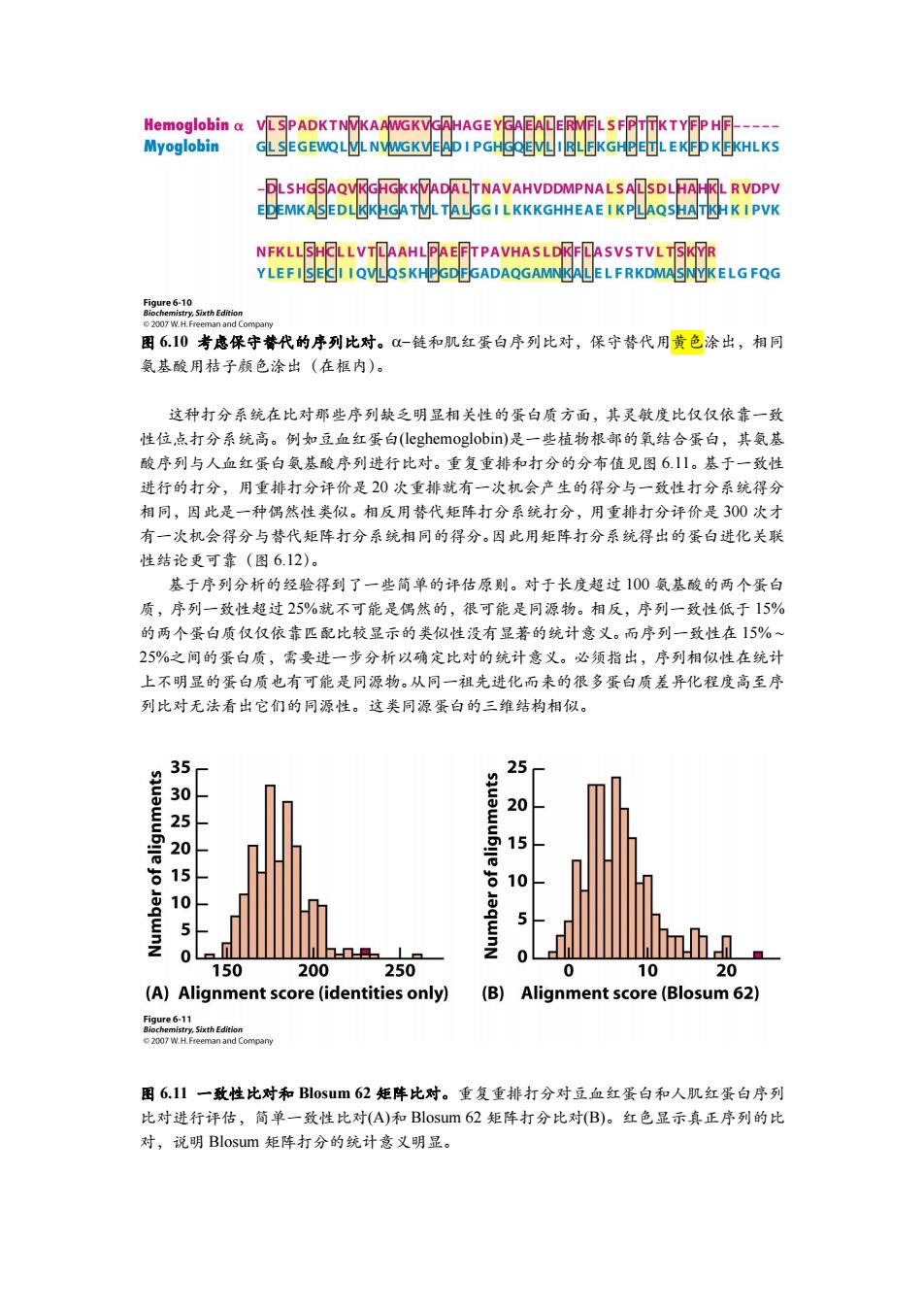
Hemoglobin VLSPADKTNVKAAWGKVGAHAGE YGAEALERMFL S FPTTKTYFP HF----- Myoglobin GLSEGEWQLVLNVGKVEAD I PGHGQEVLIRLFKGHPETLEKFD KFKHLKS DLSHGSAQVKGHGKKVADALTNAVAHVDDMPNAL SALSDLHAHKL RVDPV EDEMKASEDLKKHGATVLTALGGI LKKKGHHEAE I KPLAQSHATKHK I PVK NFKLLSHOLLVTLAAHLPAEFTPAVHASLDKFLASVSTVLTSKYR YLEFISECI I QVLQSKHPGDFGADAQGAMNKALEL FRKDMASNYKELG FQG 2007 W.H.Freeman and Company 图610考虑保守替代的序列比对。0-链和肌红蛋白序列比对,保守替代用黄色涂出,相同 氨基酸用桔子颜色涂出(在框内)。 这种打分系统在比对那些序列缺乏明显相关性的蛋白质方面,其灵敏度比仅仅依靠一致 性位,点打分系统高。例如豆血红蛋白(leghemoglobin)是一些植物根部的氧结合蛋白,其氨基 酸序列与人血红蛋白氨基酸序列进行比对。重复重排和打分的分布值见图6.11。基于一致性 进行的打分,用重排打分评价是20次重排就有一次机会产生的得分与一致性打分系统得分 相同,因此是一种偶然性类似。相反用替代矩阵打分系统打分,用重排打分评价是300次才 有一次机会得分与替代矩阵打分系统相同的得分。因此用矩阵打分系统得出的蛋白进化关联 性结论更可靠(图6.12)。 基于序列分析的经验得到了一些简单的评估原则。对于长度超过100氨基酸的两个蛋白 质,序列一致性超过25%就不可能是偶然的,很可能是同源物。相反,序列一致性低于15% 的两个蛋白质仅仅依靠匹配比较显示的类似性没有显著的统计意义。而序列一致性在15%~ 25%之间的蛋白质,需要进一步分析以确定比对的统计意义。必须指出,序列相似性在统计 上不明显的蛋白质也有可能是同源物。从同一祖先进化而来的很多蛋白质差异化程度高至序 列比对无法看出它们的同源性。这类同源蛋白的三维结构相似。 3 25 20 25 15 5 10 aqwnN 5 5 0 150 200 250 O 10 20 (A)Alignment score(identities only) (B) Alignment score(Blosum 62) Figure 6-11 Biochemistry,Sixth Edition 2007 W.H.Freeman and Company 图6.1山1一致性比对和Bl0sum62矩阵比对。重复重排打分对豆血红蛋白和人肌红蛋白序列 比对进行评估,简单一致性比对(A)和Blosum62矩阵打分比对(B)。红色显示真正序列的比 对,说明Blosum矩阵打分的统计意义明显。图 6.10 考虑保守替代的序列比对。链和肌红蛋白序列比对,保守替代用黄色涂出,相同 氨基酸用桔子颜色涂出(在框内)。 这种打分系统在比对那些序列缺乏明显相关性的蛋白质方面,其灵敏度比仅仅依靠一致 性位点打分系统高。例如豆血红蛋白(leghemoglobin)是一些植物根部的氧结合蛋白,其氨基 酸序列与人血红蛋白氨基酸序列进行比对。重复重排和打分的分布值见图 6.11。基于一致性 进行的打分,用重排打分评价是 20 次重排就有一次机会产生的得分与一致性打分系统得分 相同,因此是一种偶然性类似。相反用替代矩阵打分系统打分,用重排打分评价是 300 次才 有一次机会得分与替代矩阵打分系统相同的得分。因此用矩阵打分系统得出的蛋白进化关联 性结论更可靠(图 6.12)。 基于序列分析的经验得到了一些简单的评估原则。对于长度超过 100 氨基酸的两个蛋白 质,序列一致性超过 25%就不可能是偶然的,很可能是同源物。相反,序列一致性低于 15% 的两个蛋白质仅仅依靠匹配比较显示的类似性没有显著的统计意义。而序列一致性在 15% ~ 25%之间的蛋白质,需要进一步分析以确定比对的统计意义。必须指出,序列相似性在统计 上不明显的蛋白质也有可能是同源物。从同一祖先进化而来的很多蛋白质差异化程度高至序 列比对无法看出它们的同源性。这类同源蛋白的三维结构相似。 图 6.11 一致性比对和 Blosum 62 矩阵比对。重复重排打分对豆血红蛋白和人肌红蛋白序列 比对进行评估,简单一致性比对(A)和 Blosum 62 矩阵打分比对(B)。红色显示真正序列的比 对,说明 Blosum 矩阵打分的统计意义明显