正在加载图片...
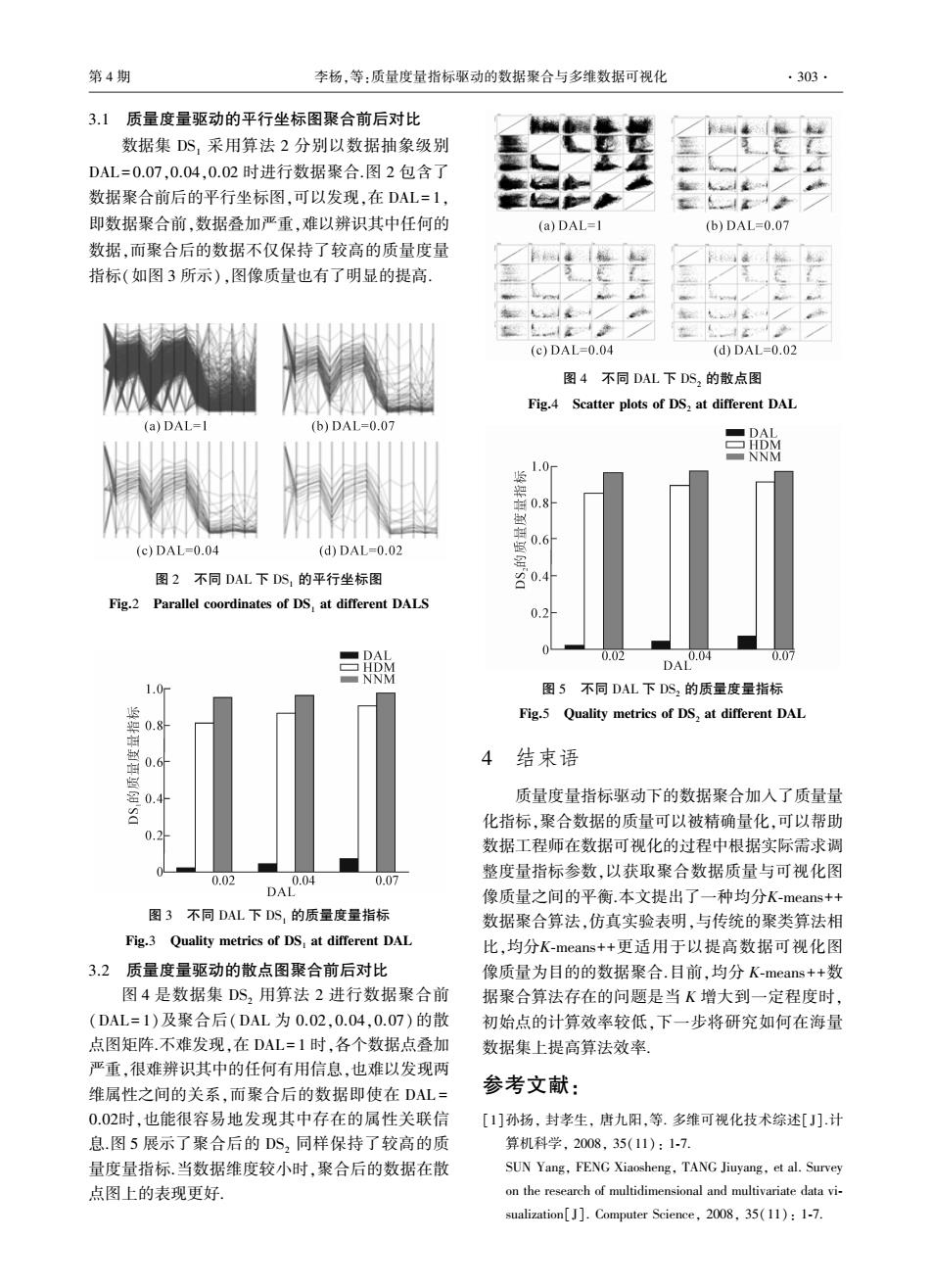
第4期 李杨,等:质量度量指标驱动的数据聚合与多维数据可视化 ·303- 3.1质量度量驱动的平行坐标图聚合前后对比 数据集DS,采用算法2分别以数据抽象级别 DAL=0.07,0.04,0.02时进行数据聚合.图2包含了 数据聚合前后的平行坐标图,可以发现,在DAL=1, 即数据聚合前,数据叠加严重,难以辨识其中任何的 (a)DAL=1 (b)DAL=0.07 数据,而聚合后的数据不仅保持了较高的质量度量 指标(如图3所示),图像质量也有了明显的提高。 (c)DAL=0.04 (d)DAL=0.02 图4不同DAL下DS2的散点图 Fig.4 Scatter plots of DS,at different DAL (a)DAL=I (b)DAL=0.07 触 1.0 0.8 0.6 (c)DAL=0.04 (d)DAL=0.02 图2不同DAL下DS,的平行坐标图 Fig.2 Parallel coordinates of DS,at different DALS 0.2 0.02 .04 0.07 DAL 图5不同DAL下DS,的质量度量指标 Fig.5 Quality metrics of DS,at different DAL 0.8 0.6 4结束语 0.4 质量度量指标驱动下的数据聚合加入了质量量 化指标,聚合数据的质量可以被精确量化,可以帮助 0.2 数据工程师在数据可视化的过程中根据实际需求调 整度量指标参数,以获取聚合数据质量与可视化图 0.02 0.04 0.07 DAL 像质量之间的平衡.本文提出了一种均分K-means++ 图3不同DAL下DS,的质量度量指标 数据聚合算法,仿真实验表明,与传统的聚类算法相 Fig.3 Quality metrics of DS,at different DAL 比,均分K-means-++更适用于以提高数据可视化图 3.2质量度量驱动的散点图聚合前后对比 像质量为目的的数据聚合.目前,均分K-means++数 图4是数据集DS,用算法2进行数据聚合前 据聚合算法存在的问题是当K增大到一定程度时, (DAL=1)及聚合后(DAL为0.02,0.04,0.07)的散 初始点的计算效率较低,下一步将研究如何在海量 点图矩阵.不难发现,在DAL=1时,各个数据,点叠加 数据集上提高算法效率, 严重,很难辨识其中的任何有用信息,也难以发现两 维属性之间的关系,而聚合后的数据即使在DAL= 参考文献: 0.02时,也能很容易地发现其中存在的属性关联信 [1]孙扬,封孝生,唐九阳,等.多维可视化技术综述[J刀].计 息.图5展示了聚合后的DS2同样保持了较高的质 算机科学,2008,35(11):1-7. 量度量指标.当数据维度较小时,聚合后的数据在散 SUN Yang,FENG Xiaosheng,TANG Jiuyang,et al.Survey 点图上的表现更好 on the research of multidimensional and multivariate data vi- sualization[]].Computer Science,2008.35(11):1-7.3.1 质量度量驱动的平行坐标图聚合前后对比 数据集 DS1 采用算法 2 分别以数据抽象级别 DAL = 0.07,0.04,0.02 时进行数据聚合.图 2 包含了 数据聚合前后的平行坐标图,可以发现,在 DAL = 1, 即数据聚合前,数据叠加严重,难以辨识其中任何的 数据,而聚合后的数据不仅保持了较高的质量度量 指标(如图 3 所示),图像质量也有了明显的提高. 图 2 不同 DAL 下 DS1 的平行坐标图 Fig.2 Parallel coordinates of DS1 at different DALS 图 3 不同 DAL 下 DS1 的质量度量指标 Fig.3 Quality metrics of DS1 at different DAL 3.2 质量度量驱动的散点图聚合前后对比 图 4 是数据集 DS2 用算法 2 进行数据聚合前 (DAL = 1)及聚合后(DAL 为 0.02,0.04,0.07)的散 点图矩阵.不难发现,在 DAL = 1 时,各个数据点叠加 严重,很难辨识其中的任何有用信息,也难以发现两 维属性之间的关系,而聚合后的数据即使在 DAL = 0.02时,也能很容易地发现其中存在的属性关联信 息.图 5 展示了聚合后的 DS2 同样保持了较高的质 量度量指标.当数据维度较小时,聚合后的数据在散 点图上的表现更好. 图 4 不同 DAL 下 DS2 的散点图 Fig.4 Scatter plots of DS2 at different DAL 图 5 不同 DAL 下 DS2 的质量度量指标 Fig.5 Quality metrics of DS2 at different DAL 4 结束语 质量度量指标驱动下的数据聚合加入了质量量 化指标,聚合数据的质量可以被精确量化,可以帮助 数据工程师在数据可视化的过程中根据实际需求调 整度量指标参数,以获取聚合数据质量与可视化图 像质量之间的平衡.本文提出了一种均分K⁃means++ 数据聚合算法,仿真实验表明,与传统的聚类算法相 比,均分K⁃means++更适用于以提高数据可视化图 像质量为目的的数据聚合.目前,均分 K⁃means++数 据聚合算法存在的问题是当 K 增大到一定程度时, 初始点的计算效率较低,下一步将研究如何在海量 数据集上提高算法效率. 参考文献: [1]孙扬, 封孝生, 唐九阳,等. 多维可视化技术综述[ J].计 算机科学, 2008, 35(11): 1⁃7. SUN Yang, FENG Xiaosheng, TANG Jiuyang, et al. Survey on the research of multidimensional and multivariate data vi⁃ sualization[J]. Computer Science, 2008, 35(11): 1⁃7. 第 4 期 李杨,等:质量度量指标驱动的数据聚合与多维数据可视化 ·303·