正在加载图片...
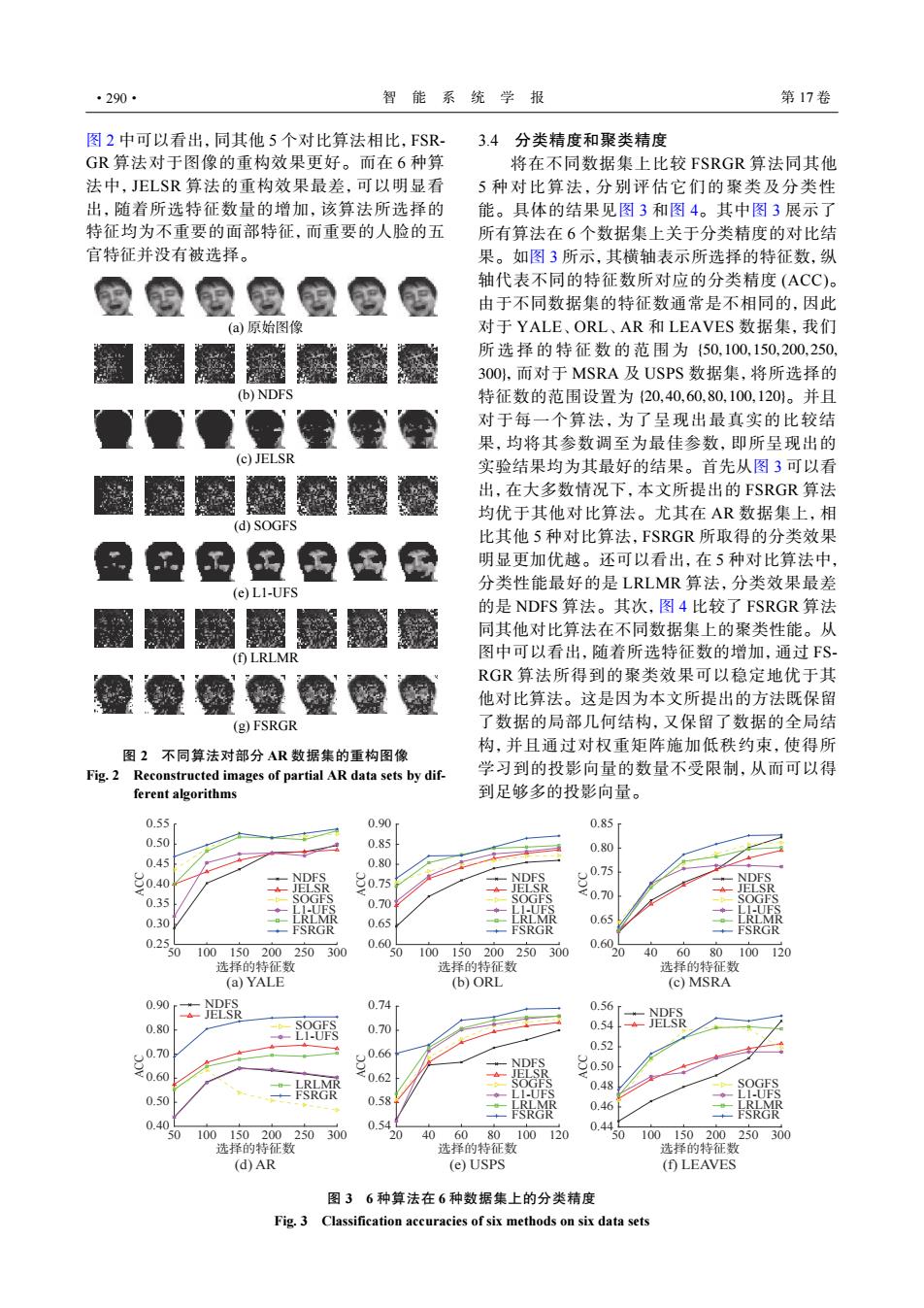
·290· 智能系统学报 第17卷 图2中可以看出,同其他5个对比算法相比,FSR- 3.4分类精度和聚类精度 G算法对于图像的重构效果更好。而在6种算 将在不同数据集上比较FSRGR算法同其他 法中,JELSR算法的重构效果最差,可以明显看 5种对比算法,分别评估它们的聚类及分类性 出,随着所选特征数量的增加,该算法所选择的 能。具体的结果见图3和图4。其中图3展示了 特征均为不重要的面部特征,而重要的人脸的五 所有算法在6个数据集上关于分类精度的对比结 官特征并没有被选择。 果。如图3所示,其横轴表示所选择的特征数,纵 轴代表不同的特征数所对应的分类精度(ACC)。 由于不同数据集的特征数通常是不相同的,因此 (a)原始图像 对于YALE、ORL、AR和LEAVES数据集,我们 所选择的特征数的范围为{50,100,150,200,250, 3001,而对于MSRA及USPS数据集,将所选择的 (b)NDFS 特征数的范围设置为(20,40,60,80,100,120)。并且 对于每一个算法,为了呈现出最直实的比较结 果,均将其参数调至为最佳参数,即所呈现出的 (c)JELSR 实验结果均为其最好的结果。首先从图3可以看 出,在大多数情况下,本文所提出的FSRGR算法 均优于其他对比算法。尤其在AR数据集上,相 (d)SOGFS 比其他5种对比算法,FSRGR所取得的分类效果 明显更加优越。还可以看出,在5种对比算法中, 分类性能最好的是LRLMR算法,分类效果最差 (e)L1-UFS 的是NDFS算法。其次,图4比较了FSRGR算法 同其他对比算法在不同数据集上的聚类性能。从 (f)LRLMR 图中可以看出,随着所选特征数的增加,通过FS RGR算法所得到的聚类效果可以稳定地优于其 他对比算法。这是因为本文所提出的方法既保留 (g)FSRGR 了数据的局部几何结构,又保留了数据的全局结 构,并且通过对权重矩阵施加低秩约束,使得所 图2不同算法对部分AR数据集的重构图像 Fig.2 Reconstructed images of partial AR data sets by dif- 学习到的投影向量的数量不受限制,从而可以得 ferent algorithms 到足够多的投影向量。 0.55 0.90r 0.85 0.50 0.85 0.80 0.45 0.80 0.40 NDFS 0.75 NDFS NDFS JELSR 0.35 SOGFS 0.70 0.30 0.65 FSRGR 0.65 FSRGR FSRGR 0.2 50 100150200 250 0.6 0.60 300 50 100150200 250 300 40 60 80 100 120 选择的特征数 选择的特征数 选择的特征数 (a)YALE (b)ORL (c)MSRA 0.90 -NDFS 。JELSR 0.74 0.56 0.80 SOGFS 0.54 ◆-L1-UFS 0.70 0.52 0.70 NDES 0.60 0.50 LRLMR 0.48 0.50 FSRGR 0.58 0.46 0.40 0.5 0.44 0100150200250300 20 406080100120 0100150200250300 选择的特征数 选择的特征数 选择的特征数 (d)AR (e)USPS (f)LEAVES 图36种算法在6种数据集上的分类精度 Fig.3 Classification accuracies of six methods on six data sets图 2 中可以看出,同其他 5 个对比算法相比,FSRGR 算法对于图像的重构效果更好。而在 6 种算 法中,JELSR 算法的重构效果最差,可以明显看 出,随着所选特征数量的增加,该算法所选择的 特征均为不重要的面部特征,而重要的人脸的五 官特征并没有被选择。 (a) 原始图像 (b) NDFS (c) JELSR (d) SOGFS (e) L1-UFS (f) LRLMR (g) FSRGR 图 2 不同算法对部分 AR 数据集的重构图像 Fig. 2 Reconstructed images of partial AR data sets by different algorithms 3.4 分类精度和聚类精度 {50,100,150,200,250, 300} {20,40,60,80,100,120} 将在不同数据集上比较 FSRGR 算法同其他 5 种对比算法,分别评估它们的聚类及分类性 能。具体的结果见图 3 和图 4。其中图 3 展示了 所有算法在 6 个数据集上关于分类精度的对比结 果。如图 3 所示,其横轴表示所选择的特征数,纵 轴代表不同的特征数所对应的分类精度 (ACC)。 由于不同数据集的特征数通常是不相同的,因此 对于 YALE、ORL、AR 和 LEAVES 数据集,我们 所选择的特征数的范围为 ,而对于 MSRA 及 USPS 数据集,将所选择的 特征数的范围设置为 。并且 对于每一个算法,为了呈现出最真实的比较结 果,均将其参数调至为最佳参数,即所呈现出的 实验结果均为其最好的结果。首先从图 3 可以看 出,在大多数情况下,本文所提出的 FSRGR 算法 均优于其他对比算法。尤其在 AR 数据集上,相 比其他 5 种对比算法,FSRGR 所取得的分类效果 明显更加优越。还可以看出,在 5 种对比算法中, 分类性能最好的是 LRLMR 算法,分类效果最差 的是 NDFS 算法。其次,图 4 比较了 FSRGR 算法 同其他对比算法在不同数据集上的聚类性能。从 图中可以看出,随着所选特征数的增加,通过 FSRGR 算法所得到的聚类效果可以稳定地优于其 他对比算法。这是因为本文所提出的方法既保留 了数据的局部几何结构,又保留了数据的全局结 构,并且通过对权重矩阵施加低秩约束,使得所 学习到的投影向量的数量不受限制,从而可以得 到足够多的投影向量。 50 100 150 200 250 300 选择的特征数 NDFS JELSR SOGFS LRLMR FSRGR L1-UFS NDFS JELSR LRLMR FSRGR SOGFS L1-UFS NDFS JELSR SOGFS LRLMR FSRGR L1-UFS NDFS JELSR SOGFS LRLMR FSRGR L1-UFS NDFS JELSR SOGFS LRLMR FSRGR L1-UFS NDFS JELSR SOGFS LRLMR FSRGR L1-UFS ACC 0.55 0.50 0.45 0.40 0.35 0.30 0.25 (a) YALE 50 100 150 200 250 300 选择的特征数 0.60 0.65 0.70 0.75 0.80 0.85 0.90 ACC (b) ORL 20 40 60 80 100 120 选择的特征数 0.60 0.65 0.70 0.75 0.80 0.85 ACC (c) MSRA 50 100 150 200 250 300 选择的特征数 0.40 0.50 0.60 0.70 0.80 0.90 ACC 20 40 60 80 100 120 选择的特征数 0.54 0.58 0.62 0.66 0.70 0.74 ACC (d) AR 50 100 150 200 250 300 选择的特征数 0.44 0.46 0.48 0.50 0.52 0.54 0.56 ACC (e) USPS (f) LEAVES 图 3 6 种算法在 6 种数据集上的分类精度 Fig. 3 Classification accuracies of six methods on six data sets ·290· 智 能 系 统 学 报 第 17 卷