正在加载图片...
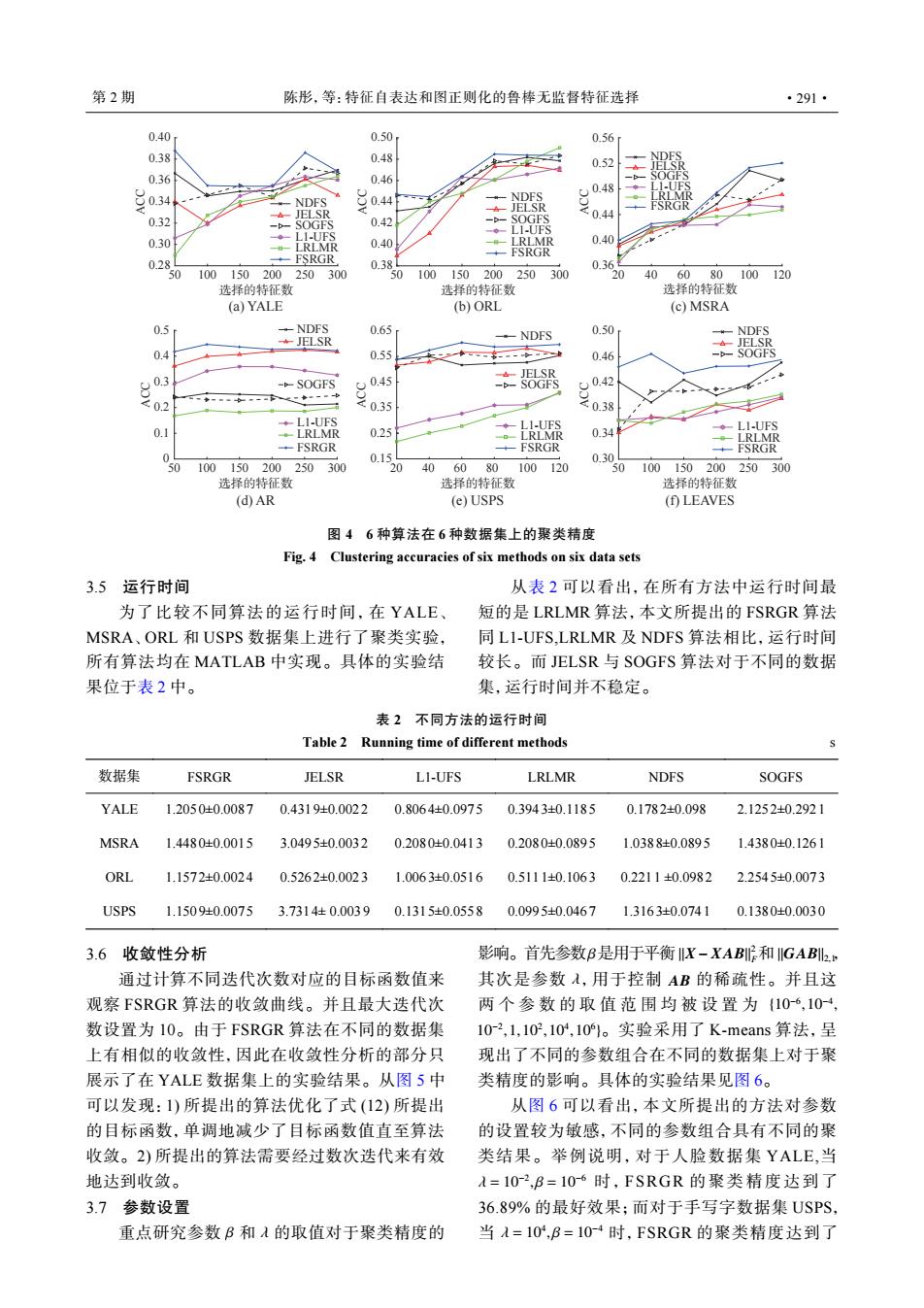
第2期 陈形,等:特征自表达和图正则化的鲁棒无监督特征选择 ·291· 0.40 0.50 0.56 0.38 0.48 0.52 0.36 0.46 NDES NDES 0.44 JFLSR 0.44 0.32 SOGES 0.42 SOGFS I L-TES 0.30 LRLMR 0.40 LRLMR 0.40 FSRGR 0.28 FSRGR 0.38 0.36 0 100150200 250300 0 100150200 250 300 0 406080100120 选择的特征数 选择的特征数 选择的特征数 (a)YALE (b)ORL (c)MSRA 0.5 -NDES 0.65 NDFS 0.50 JELSR 0.4 0.55 、-女 0.46 -b-SOGFS --SOGFS <0.2 当 ” LI-UFS LI-UFS LI-UFS 0.1 LRLMR 0.25 0.34 LRLMR -FSRGR -FSRGR FSRGR 0 0.1 0.30 50 100150200250 300 20 40 6080 100120 50 100150 200250 300 选择的特征数 选择的特征数 选择的特征数 (d)AR (e)USPS (f)LEAVES 图46种算法在6种数据集上的聚类精度 Fig.4 Clustering accuracies of six methods on six data sets 3.5 运行时间 从表2可以看出,在所有方法中运行时间最 为了比较不同算法的运行时间,在YALE、 短的是LRLMR算法,本文所提出的FSRGR算法 MSRA、ORL和USPS数据集上进行了聚类实验, 同L1-UFS.LRLMR及NDFS算法相比,运行时间 所有算法均在MATLAB中实现。具体的实验结 较长。而ELSR与SOGFS算法对于不同的数据 果位于表2中。 集,运行时间并不稳定。 表2不同方法的运行时间 Table 2 Running time of different methods 数据集 FSRGR JELSR L1-UFS LRLMR NDFS SOGFS YALE 1.2050±0.0087 0.4319±0.0022 0.8064±0.0975 0.3943±0.1185 0.1782±0.098 2.1252±0.2921 MSRA 1.4480±0.0015 3.0495±0.0032 0.2080±0.0413 0.2080±0.0895 1.0388±0.0895 1.4380±0.1261 ORL 1.1572±0.0024 0.5262±0.0023 1.0063±0.0516 0.5111±0.1063 0.2211±0.0982 2.2545±0.0073 USPS 1.1509±0.0075 3.7314牡0.0039 0.1315±0.0558 0.0995±0.0467 1.3163±0.0741 0.1380±0.0030 3.6收敛性分析 影响。首先参数B是用于平衡X-XABI和IIGABIL2 通过计算不同迭代次数对应的目标函数值来 其次是参数A,用于控制AB的稀疏性。并且这 观察FSRGR算法的收敛曲线。并且最大迭代次 两个参数的取值范围均被设置为{10-6,10-4, 数设置为10。由于FSRGR算法在不同的数据集 10-2,1,102,10,101。实验采用了K-means算法,呈 上有相似的收敛性,因此在收敛性分析的部分只 现出了不同的参数组合在不同的数据集上对于聚 展示了在YALE数据集上的实验结果。从图5中 类精度的影响。具体的实验结果见图6。 可以发现:1)所提出的算法优化了式(12)所提出 从图6可以看出,本文所提出的方法对参数 的目标函数,单调地减少了目标函数值直至算法 的设置较为敏感,不同的参数组合具有不同的聚 收敛。2)所提出的算法需要经过数次迭代来有效 类结果。举例说明,对于人脸数据集YALE,当 地达到收敛。 A=10-2,B=106时,FSRGR的聚类精度达到了 3.7参数设置 36.89%的最好效果;而对于手写字数据集USPS, 重点研究参数B和入的取值对于聚类精度的 当A=10,B=10~4时,FSRGR的聚类精度达到了NDFS NDFS JELSR SOGFS JELSR SOGFS LRLMR FSRGR L1-UFS LRLMR FSRGR L1-UFS NDFS JELSR SOGFS LRLMR FSRGR L1-UFS NDFS JELSR SOGFS LRLMR FSRGR L1-UFS NDFS JELSR SOGFS LRLMR FSRGR L1-UFS (a) YALE (b) ORL (c) MSRA (d) AR (e) USPS (f) LEAVES 50 100 150 200 250 300 选择的特征数 0 0.1 0.2 0.3 0.4 0.5 ACC NDFS JELSR SOGFS LRLMR FSRGR L1-UFS 50 100 150 200 250 300 选择的特征数 0.30 0.34 0.38 0.42 0.46 0.50 ACC 20 40 60 80 100 120 选择的特征数 0.36 0.40 0.44 0.48 0.52 0.56 ACC 50 100 150 200 250 300 选择的特征数 0.38 0.40 0.42 0.44 0.46 0.48 0.50 ACC 20 40 60 80 100 120 选择的特征数 0.15 0.25 0.35 0.45 0.55 0.65 ACC 50 100 150 200 250 300 选择的特征数 0.28 0.30 0.32 0.34 0.36 0.38 0.40 ACC 图 4 6 种算法在 6 种数据集上的聚类精度 Fig. 4 Clustering accuracies of six methods on six data sets 3.5 运行时间 为了比较不同算法的运行时间,在 YALE、 MSRA、ORL 和 USPS 数据集上进行了聚类实验, 所有算法均在 MATLAB 中实现。具体的实验结 果位于表 2 中。 从表 2 可以看出,在所有方法中运行时间最 短的是 LRLMR 算法,本文所提出的 FSRGR 算法 同 L1-UFS,LRLMR 及 NDFS 算法相比,运行时间 较长。而 JELSR 与 SOGFS 算法对于不同的数据 集,运行时间并不稳定。 表 2 不同方法的运行时间 Table 2 Running time of different methods s 数据集 FSRGR JELSR L1-UFS LRLMR NDFS SOGFS YALE 1.205 0±0.0087 0.4319±0.0022 0.8064±0.0975 0.394 3±0.1185 0.178 2±0.098 2.1252±0.292 1 MSRA 1.448 0±0.0015 3.0495±0.0032 0.2080±0.0413 0.208 0±0.0895 1.0388±0.0895 1.4380±0.126 1 ORL 1.157 2±0.0024 0.5262±0.0023 1.0063±0.0516 0.511 1±0.1063 0.221 1 ±0.098 2 2.2545±0.007 3 USPS 1.150 9±0.0075 3.731 4± 0.003 9 0.1315±0.0558 0.099 5±0.0467 1.3163±0.0741 0.1380±0.003 0 3.6 收敛性分析 通过计算不同迭代次数对应的目标函数值来 观察 FSRGR 算法的收敛曲线。并且最大迭代次 数设置为 10。由于 FSRGR 算法在不同的数据集 上有相似的收敛性,因此在收敛性分析的部分只 展示了在 YALE 数据集上的实验结果。从图 5 中 可以发现:1) 所提出的算法优化了式 (12) 所提出 的目标函数,单调地减少了目标函数值直至算法 收敛。2) 所提出的算法需要经过数次迭代来有效 地达到收敛。 3.7 参数设置 重点研究参数 β 和 λ 的取值对于聚类精度的 β ∥X− XAB∥ 2 F ∥GAB∥2,1 λ AB {10−6 ,10−4 , 10−2 ,1,102 ,104 ,106 } 影响。首先参数 是用于平衡 和 , 其次是参数 ,用于控制 的稀疏性。并且这 两个参数的取值范围均被设置为 。实验采用了 K-means 算法,呈 现出了不同的参数组合在不同的数据集上对于聚 类精度的影响。具体的实验结果见图 6。 λ = 10−2 , β = 10−6 λ = 104 , β = 10−4 从图 6 可以看出,本文所提出的方法对参数 的设置较为敏感,不同的参数组合具有不同的聚 类结果。举例说明,对于人脸数据集 YALE,当 时 , FSRGR 的聚类精度达到了 36.89% 的最好效果;而对于手写字数据集 USPS, 当 时,FSRGR 的聚类精度达到了 第 2 期 陈彤,等:特征自表达和图正则化的鲁棒无监督特征选择 ·291·