正在加载图片...
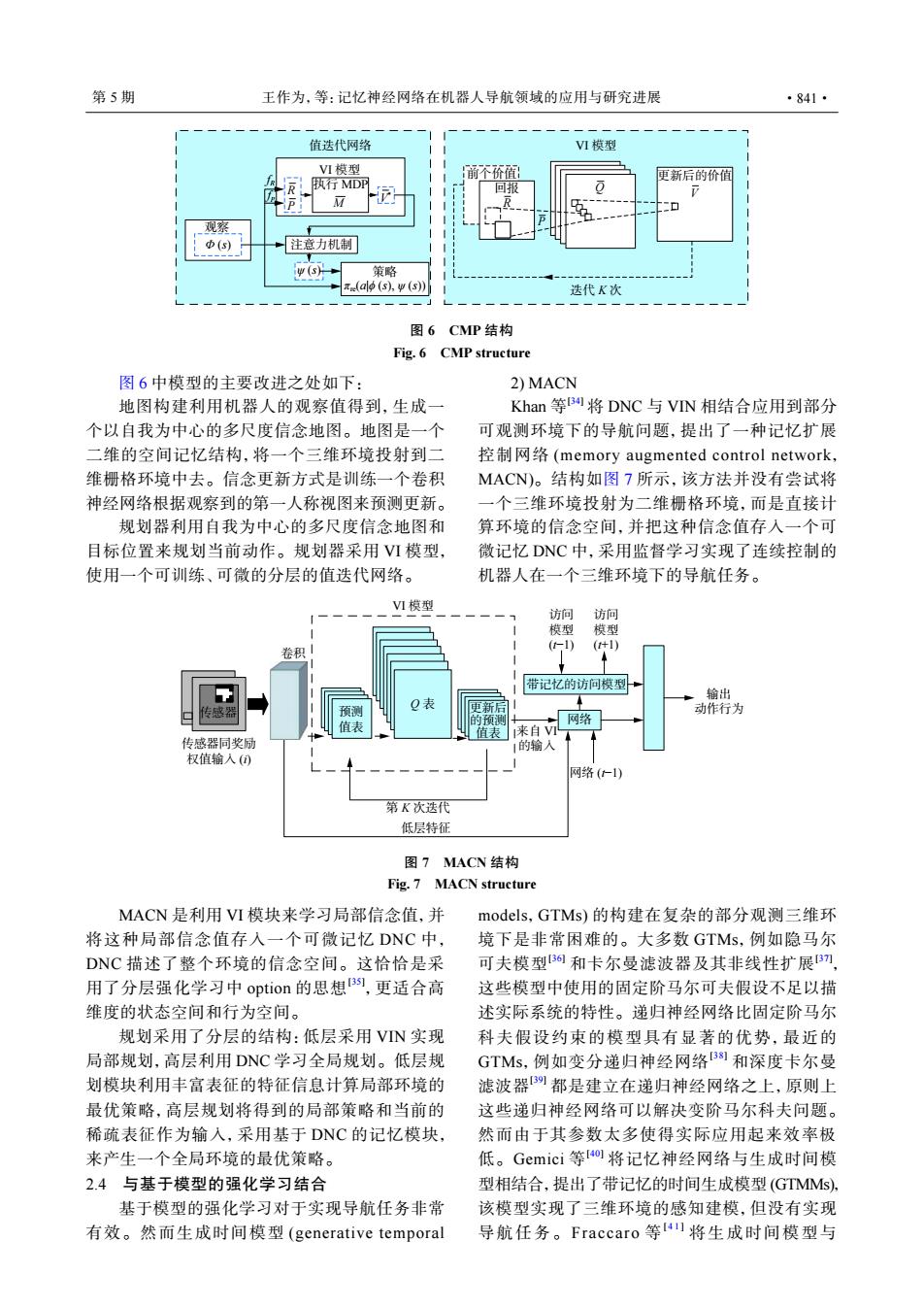
第5期 王作为,等:记忆神经网络在机器人导航领域的应用与研究进展 ·841· 值迭代网络 VⅥ模型 VI模型 前个价值 便新后的价值 R 执行MDP 回报 0 2 矿 观察 Φ(s) 注意力机制 策略 (al (s).w(s)) 迭代K次 图6 CMP结构 Fig.6 CMP structure 图6中模型的主要改进之处如下: 2)MACN 地图构建利用机器人的观察值得到,生成一 Khan等B将DNC与VN相结合应用到部分 个以自我为中心的多尺度信念地图。地图是一个 可观测环境下的导航问题,提出了一种记忆扩展 二维的空间记忆结构,将一个三维环境投射到二 控制网络(memory augmented control network, 维栅格环境中去。信念更新方式是训练一个卷积 MACN)。结构如图7所示,该方法并没有尝试将 神经网络根据观察到的第一人称视图来预测更新。 一个三维环境投射为二维栅格环境,而是直接计 规划器利用自我为中心的多尺度信念地图和 算环境的信念空间,并把这种信念值存入一个可 目标位置来规划当前动作。规划器采用VⅥI模型, 微记忆DNC中,采用监督学习实现了连续控制的 使用一个可训练、可微的分层的值迭代网络。 机器人在一个三维环境下的导航任务。 V1模型 访间 访问 模型 模型 卷积 (1) (+1) 带记忆的访问模型 输出 传感器 Q表 更新后 动作行为 表 的预润 网络 值表 1来自VI 传感器同奖励 1的输入 权值输入() 网络(仁1) 第K次迭代 低层特征 图7MACN结构 Fig.7 MACN structure MACN是利用VI模块来学习局部信念值,并 models,GTMs)的构建在复杂的部分观测三维环 将这种局部信念值存入一个可微记忆DNC中, 境下是非常困难的。大多数GTMs,例如隐马尔 DNC描述了整个环境的信念空间。这恰恰是采 可夫模型3和卡尔曼滤波器及其非线性扩展刀 用了分层强化学习中option的思想B,更适合高 这些模型中使用的固定阶马尔可夫假设不足以描 维度的状态空间和行为空间。 述实际系统的特性。递归神经网络比固定阶马尔 规划采用了分层的结构:低层采用VN实现 科夫假设约束的模型具有显著的优势,最近的 局部规划,高层利用DNC学习全局规划。低层规 GTMs,例如变分递归神经网络B1和深度卡尔曼 划模块利用丰富表征的特征信息计算局部环境的 滤波器都是建立在递归神经网络之上,原则上 最优策略,高层规划将得到的局部策略和当前的 这些递归神经网络可以解决变阶马尔科夫问题。 稀疏表征作为输入,采用基于DNC的记忆模块, 然而由于其参数太多使得实际应用起来效率极 来产生一个全局环境的最优策略。 低。Gemici等o将记忆神经网络与生成时间模 2.4与基于模型的强化学习结合 型相结合,提出了带记忆的时间生成模型(GTMMs), 基于模型的强化学习对于实现导航任务非常 该模型实现了三维环境的感知建模,但没有实现 有效。然而生成时间模型(generative temporal 导航任务。Fraccaro等4)将生成时间模型与注意力机制 执行 MDP 观察 fR fP R M V * P 策略 值迭代网络 VI 模型 回报 R P Q V 前个价值 迭代 K 次 更新后的价值 VI 模型 Φ (s) ψ (s) πre(a|ϕ (s), ψ (s)) 图 6 CMP 结构 Fig. 6 CMP structure 图 6 中模型的主要改进之处如下: 地图构建利用机器人的观察值得到,生成一 个以自我为中心的多尺度信念地图。地图是一个 二维的空间记忆结构,将一个三维环境投射到二 维栅格环境中去。信念更新方式是训练一个卷积 神经网络根据观察到的第一人称视图来预测更新。 规划器利用自我为中心的多尺度信念地图和 目标位置来规划当前动作。规划器采用 VI 模型, 使用一个可训练、可微的分层的值迭代网络。 2) MACN Khan 等 [34] 将 DNC 与 VIN 相结合应用到部分 可观测环境下的导航问题,提出了一种记忆扩展 控制网络 (memory augmented control network, MACN)。结构如图 7 所示,该方法并没有尝试将 一个三维环境投射为二维栅格环境,而是直接计 算环境的信念空间,并把这种信念值存入一个可 微记忆 DNC 中,采用监督学习实现了连续控制的 机器人在一个三维环境下的导航任务。 网络 带记忆的访问模型 传感器 传感器同奖励 权值输入 (i) 卷积 预测 值表 Q 表 VI 模型 更新后 的预测 值表 访问 模型 (t−1) 访问 模型 (t+1) 网络 (t−1) 输出 动作行为 低层特征 来自 VI 的输入 第 K 次迭代 图 7 MACN 结构 Fig. 7 MACN structure MACN 是利用 VI 模块来学习局部信念值,并 将这种局部信念值存入一个可微记忆 DNC 中 , DNC 描述了整个环境的信念空间。这恰恰是采 用了分层强化学习中 option 的思想[35] ,更适合高 维度的状态空间和行为空间。 规划采用了分层的结构:低层采用 VIN 实现 局部规划,高层利用 DNC 学习全局规划。低层规 划模块利用丰富表征的特征信息计算局部环境的 最优策略,高层规划将得到的局部策略和当前的 稀疏表征作为输入,采用基于 DNC 的记忆模块, 来产生一个全局环境的最优策略。 2.4 与基于模型的强化学习结合 基于模型的强化学习对于实现导航任务非常 有效。然而生成时间模型 (generative temporal models,GTMs) 的构建在复杂的部分观测三维环 境下是非常困难的。大多数 GTMs,例如隐马尔 可夫模型[36] 和卡尔曼滤波器及其非线性扩展[37] , 这些模型中使用的固定阶马尔可夫假设不足以描 述实际系统的特性。递归神经网络比固定阶马尔 科夫假设约束的模型具有显著的优势,最近的 GTMs,例如变分递归神经网络[38] 和深度卡尔曼 滤波器[39] 都是建立在递归神经网络之上,原则上 这些递归神经网络可以解决变阶马尔科夫问题。 然而由于其参数太多使得实际应用起来效率极 低。Gemici 等 [40] 将记忆神经网络与生成时间模 型相结合,提出了带记忆的时间生成模型 (GTMMs), 该模型实现了三维环境的感知建模,但没有实现 导航任务。Fraccaro 等 [ 4 1 ] 将生成时间模型与 第 5 期 王作为,等:记忆神经网络在机器人导航领域的应用与研究进展 ·841·