正在加载图片...
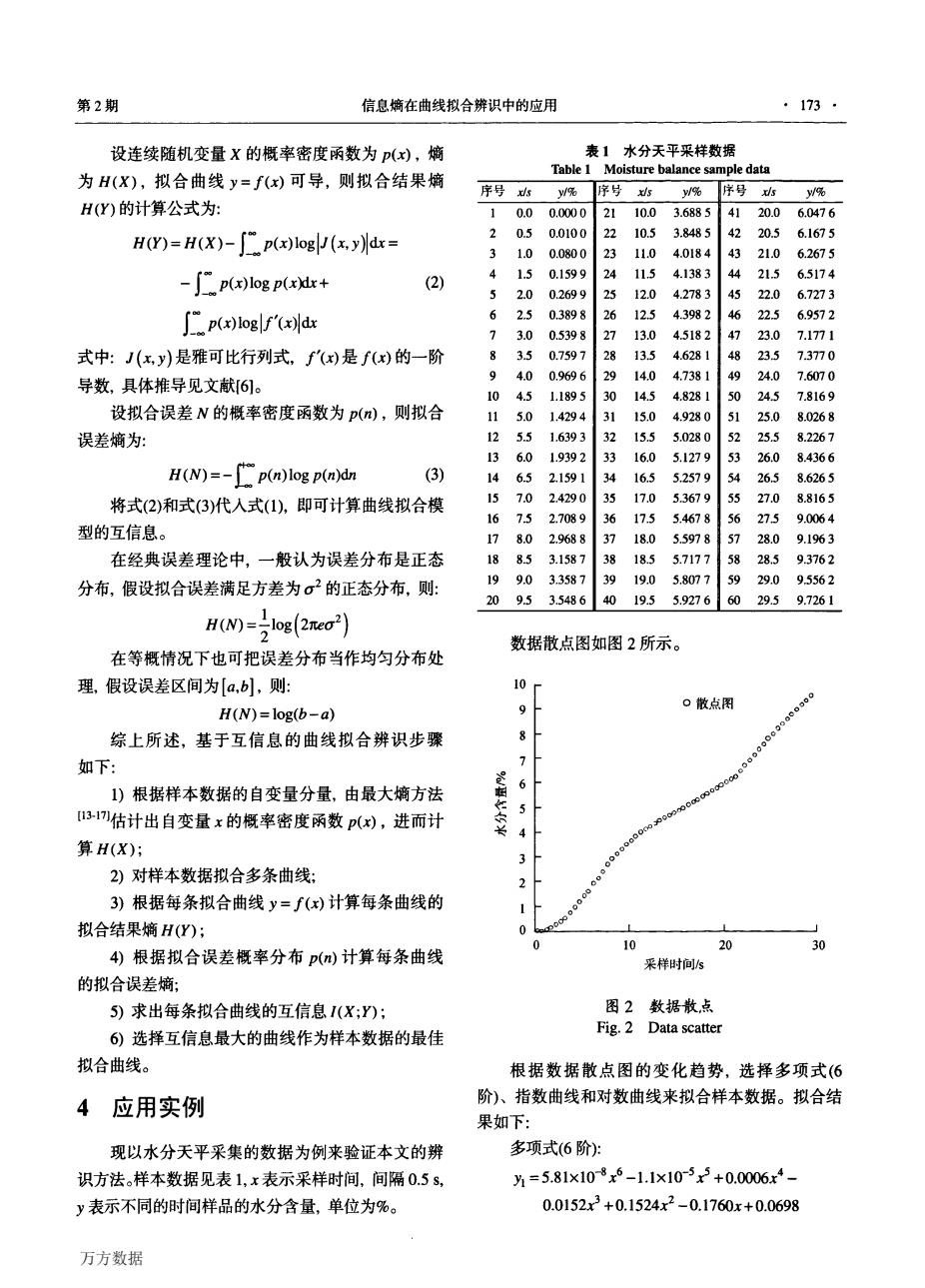
第2期 信息熵在曲线拟合辨识中的应用 ·173· 设连续随机变量X的概率密度函数为p(x),熵 表1水分天平采样数据 为H(X),拟合曲线y=f(x)可导,则拟合结果熵 Table 1 Moisture balance sample data 序号s /% 序号 % 序号s % H(Y)的计算公式为: 1 0.0 0.0000 21 10.0 3.6885 41 20.0 6.0476 H(Y)=H(X)-[p(x)log J(x.y)dx= 20.5 0.0100 3 10.5 3.8485 42 20.5 6.1675 31.0 0.0800 23 11.0 4.0184 43 21.0 6.2675 -∫Cpx)logp(xir+ 4 (2) 1.5 0.1599 24 11.5 4.1383 44 21.5 6.5174 5 2.0 0.2699 12.0 4.2783 45 22.0 6.7273 ∫(of'(xl 6 2.5 0.3898 26 12.5 4.3982 46 22.5 6.9572 7 3.0 0.5398 27 13.0 4.5182 % 23.0 7.1771 式中:J(x,y)是雅可比行列式,'(x)是f(x)的一阶 83.5 0.7597 28 13.5 4.6281 48 23.5 7.3770 9 4.0 0.9696 29 14.0 4.7381 4924.0 7.6070 导数,具体推导见文献6]。 0 4.5 1.1895 30 14.5 4.8281 50 24.5 7.8169 设拟合误差N的概率密度函数为p(),则拟合 11 5.0 1.4294 1 15.0 4.9280 51 25.0 8.0268 误差熵为: 12 5.5 1.6393 15.5 5.0280 内 25.5 8.2267 13 6.0 1.9392 33 16.0 5.1279 53 26.0 8.4366 H(N)=-p(n)log p(n)dn (3) 6.5 2.1591 34 16.5 5.2579 54 26.5 8.6265 将式(2)和式(3)代人式(1),即可计算曲线拟合模 7.0 2.4290 35 17.0 5.3679 55 27.0 8.8165 16 75 2.7089 36 17.5 5.4678 56 275 9.0064 型的互信息。 17 8.0 2.9688 之 18.0 5.5978 28.0 9.1963 在经典误差理论中,一般认为误差分布是正态 伊 8.5 3.1587 38 18.5 5.7177 58 28.5 9.3762 分布,假设拟合误差满足方差为σ2的正态分布,则: 9.0 3.3587 39 19.0 5.8077 59 29.0 9.5562 20 9.5 3.5486 40 19.5 5.92766029.59.7261 Hw=21og(2eo2) 数据散点图如图2所示。 在等概情况下也可把误差分布当作均匀分布处 理,假设误差区间为[a,b小,则: 10 口散点图 H(N)=log(b-a)) 9 综上所述,基于互信息的曲线拟合辨识步骤 8 如下: 7 1)根据样本数据的自变量分量,由最大熵方法 6 31估计出自变量x的概率密度函数p(x),进而计 5 算H(X); 2)对样本数据拟合多条曲线: 2 3)根据每条拟合曲线y=f(x)计算每条曲线的 拟合结果熵H(Y); 10 20 30 4)根据拟合误差概率分布p(m)计算每条曲线 采样时间s 的拟合误差熵; 5)求出每条拟合曲线的互信息I(X;Y): 图2数据散点 6)选择互信息最大的曲线作为样本数据的最佳 Fig.2 Data scatter 拟合曲线。 根据数据散点图的变化趋势,选择多项式(6 4 应用实例 阶)、指数曲线和对数曲线来拟合样本数据。拟合结 果如下: 现以水分天平采集的数据为例来验证本文的辨 多项式(6阶): 识方法。样本数据见表1,x表示采样时间,间隔0.5s, 为=5.81×108x5-1.1×105x+0.0006x4 y表示不同的时间样品的水分含量,单位为%。 0.0152x23+0.1524x2-0.1760x+0.0698 万方数据第2期 信息熵在曲线拟合辨识中的应用 ·173· 设连续随机变量x的概率密度函数为p(工),熵 为H(x),拟合曲线Y=,(工)可导,则拟合结果熵 H(y)的计算公式为: 日(y)=(x)一』二p(工)l(,y)ldx=H log J x 日(y)= (x)一I0·∞ p(工) l(, Y Idx —I p(x)log p(x)dx+ (2) 』二p(x)]oglf侧出 ,一∞ I ’(工)I出 式中:.,(x,Y)是雅可比行列式,,’(工)是.厂(工)的一阶 导数,具体推导见文献f6】。 设拟合误差Ⅳ的概率密度函数为p(,z),则拟合 误差熵为: 日(Ⅳ)=一I。p(n)logp∽)曲 (3) 将式(2)和式(3)代入式(1),即可计算曲线拟合模 型的互信息。 在经典误差理论中,一般认为误差分布是正态 分布,假设拟合误差满足方差为仃2的正态分布,则: 日(Ⅳ)=寺log(2舵盯2) 在等概情况下也可把误差分布当作均匀分布处 理,假设误差区间为kb】,则: Ⅳ(Ⅳ)=log(b一口) 综上所述,基于互信息的曲线拟合辨识步骤 如下: 1)根据样本数据的自变量分量,由最大熵方法 [13-171估计出自变量x的概率密度函数p(工),进而计 算日(x); 2)对样本数据拟合多条曲线; 3)根据每条拟合曲线Y=,(工)计算每条曲线的 拟合结果熵日(y); 4)根据拟合误差概率分布p(n)计算每条曲线 的拟合误差熵; 5)求出每条拟合曲线的互信息,(x;',): 6)选择互信息最大的曲线作为样本数据的最佳 拟合曲线。 4应用实例 现以水分天平采集的数据为例来验证本文的辨 识方法。样本数据见表1,X表示采样时间,间隔0.5 s, Y表示不同的时间样品的水分含量,单位为%。 表1水分天平采样数据 Thbk 1 Moisture balance sample data 弃号耐s y1% 痒号 x}s v|% 昏号】c}s y/% l O.0 O.0000 2l 10.0 3.688 5 4l 20.0 6.0476 2 0.5 0.0100 22 10.5 3.848 5 42 20.5 6.1675 3 1.0 0.0800 23 11.0 4.0184 43 21.0 6.2675 4 1.5 0.1599 24 11.5 4.138 3 44 21.5 6.5174 5 2.O 0.2699 25 12.0 4.278 3 45 22.O 6.727 3 6 2.5 0.389 8 26 12.5 4.398 2 46 22.5 6.957 2 7 3.0 0.539 8 27 13.0 4.518 2 47 23.O 7.177l 8 3.5 0.759 7 28 13.5 4.628 l 48 23.5 7.3770 9 4.0 0.969 6 29 14.0 4.738 1 49 24.0 7.6070 10 4.5 1.189 5 30 14.5 4.828 l 50 24.5 7.8169 ll 5.0 1.4294 3l 15.0 4.928 0 51 25.O 8.026 8 12 5.5 1.639 3 32 15.5 5.028 0 52 25.5 8.2267 13 6.0 1.939 2 33 16.O 5.127 9 53 26.0 8.4366 14 6.5 2.159l 34 16.5 5.257 9 54 26.5 8.6265 15 7.O 2.4290 35 17.O 5.3679 55 27.O 8.816 5 16 7.5 2.708 9 36 17.5 5.467 8 56 27.5 9.0064 17 8.O 2.968 8 37 18.O 5.597 8 57 28.0 9.196 3 18 8.5 3.158 7 38 l&5 5.7177 58 28.5 9.3762 19 9.O 3.358 7 39 19.0 5.807 7 59 29.0 9.5562 20 9.5 3.548 6 40 19.5 5.927 6 60 29.5 9.726l 莲 删 把 糸 * 数据散点图如图2所示。 采样时间/s 图2教据散点 Fig.2 Data scatter 根据数据散点图的变化趋势,选择多项式(6 阶)、指数曲线和对数曲线来拟合样本数据。拟合结 果如下: 多项式(6阶): Yl=5.81x10-Sx6—1.1x10—5x5+O.0006工4— 0.0152x3+0.1524x2—0.1760x+0.0698 O 9 8 7 6 5 4 3 2 l O 万方数据