正在加载图片...
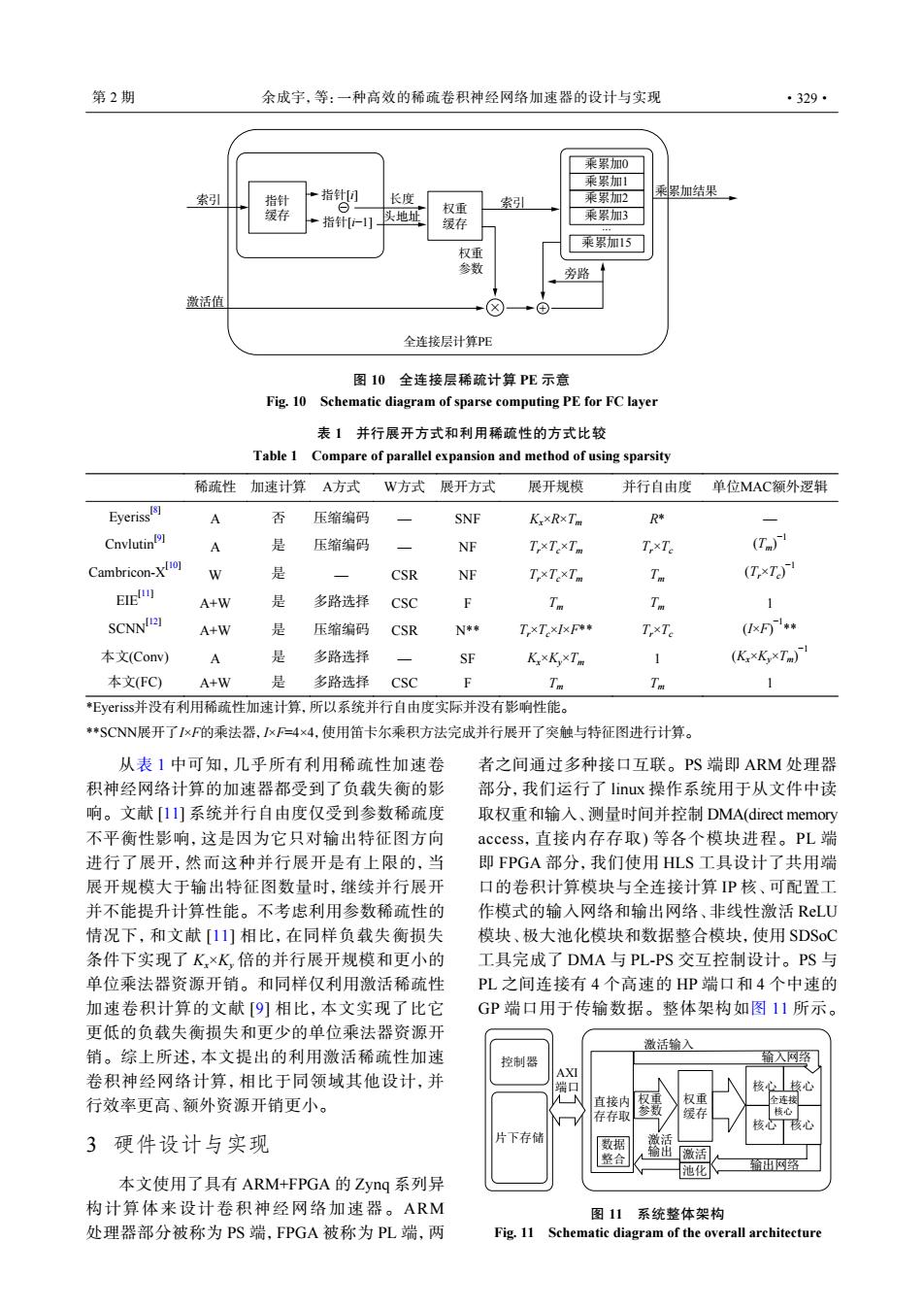
第2期 余成宇,等:一种高效的稀疏卷积神经网络加速器的设计与实现 ·329· 乘累加0 乘累加1 一指针回 长度 乘累加结果 索引 指针 权重 索引 乘累加2 缓存 指针[i-1] 头地址 乘累加3 缓存 乘累加15 权重 参数 旁路 激活值 全连接层计算PE 图10全连接层稀疏计算PE示意 Fig.10 Schematic diagram of sparse computing PE for FC layer 表1并行展开方式和利用稀疏性的方式比较 Table 1 Compare of parallel expansion and method of using sparsity 稀疏性加速计算A方式 W方式展开方式 展开规模 并行自由度 单位MAC额外逻辑 yeriss周 否 压缩编码 SNF KxxRxTm R* Cnvlutin例 是 压缩编码 NF T,×T×Tm T,xTe (T) Cambricon-Xo W 冷 CSR NF T,xTexTm (TxTa ElE A+W 是 多路选择 Csc Ti Tn 1 SCNNI2] A+W 是 压缩编码 CSR N*率 T,×TxxF* T,×Te (F) 本文(Conv) A 是 多路选择 SF K×K,×Tm 1 (K.xKxT) 本文(FC) A+W 多路选择 CSC Tn Tot 1 Eyeriss并没有利用稀疏性加速计算,所以系统并行自由度实际并没有影响性能。 *SCNN展开了IxF的乘法器,IxF=4×4,使用笛卡尔乘积方法完成并行展开了突触与特征图进行计算。 从表1中可知,几乎所有利用稀疏性加速卷 者之间通过多种接口互联。PS端即ARM处理器 积神经网络计算的加速器都受到了负载失衡的影 部分,我们运行了Iiux操作系统用于从文件中读 响。文献[1]系统并行自由度仅受到参数稀疏度 取权重和输入、测量时间并控制DMA(direct memory 不平衡性影响,这是因为它只对输出特征图方向 access,直接内存存取)等各个模块进程。PL端 进行了展开,然而这种并行展开是有上限的,当 即FPGA部分,我们使用HLS工具设计了共用端 展开规模大于输出特征图数量时,继续并行展开 口的卷积计算模块与全连接计算P核、可配置工 并不能提升计算性能。不考虑利用参数稀疏性的 作模式的输入网络和输出网络、非线性激活RLU 情况下,和文献[11]相比,在同样负载失衡损失 模块、极大池化模块和数据整合模块,使用SDSoC 条件下实现了K×K,倍的并行展开规模和更小的 工具完成了DMA与PL-PS交互控制设计。PS与 单位乘法器资源开销。和同样仅利用激活稀疏性 PL之间连接有4个高速的HP端口和4个中速的 加速卷积计算的文献[9]相比,本文实现了比它 GP端口用于传输数据。整体架构如图11所示。 更低的负载失衡损失和更少的单位乘法器资源开 激活输入 销。综上所述,本文提出的利用激活稀疏性加速 控制器 输人网绍 卷积神经网络计算,相比于同领域其他设计,并 AXI 端口 行效率更高、额外资源开销更小。 直接内 权重 存存取 缓存 3硬件设计与实现 片下存储 数据 输出 整合 激活 池化 输网 本文使用了具有ARM+FPGA的Zyng系列异 构计算体来设计卷积神经网络加速器。ARM 图11 系统整体架构 处理器部分被称为PS端,FPGA被称为PL端,两 Fig.11 Schematic diagram of the overall architecture指针 缓存 指针[i] 指针[i−1] − × + 长度 头地址 权重 缓存 索引 权重 参数 索引 激活值 旁路 全连接层计算PE 乘累加结果 乘累加0 乘累加1 乘累加2 乘累加3 乘累加15 ... 图 10 全连接层稀疏计算 PE 示意 Fig. 10 Schematic diagram of sparse computing PE for FC layer 表 1 并行展开方式和利用稀疏性的方式比较 Table 1 Compare of parallel expansion and method of using sparsity 稀疏性 加速计算 A方式 W方式 展开方式 展开规模 并行自由度 单位MAC额外逻辑 Eyeriss[8] A 否 压缩编码 — SNF Kx×R×Tm R* — Cnvlutin[9] A 是 压缩编码 — NF Tr×Tc×Tm Tr×Tc (Tm) −1 Cambricon-X[10] W 是 — CSR NF Tr×Tc×Tm Tm (Tr×Tc ) −1 EIE[11] A+W 是 多路选择 CSC F Tm Tm 1 SCNN[12] A+W 是 压缩编码 CSR N** Tr×Tc×I×F** Tr×Tc (I×F) −1** 本文(Conv) A 是 多路选择 — SF Kx×Ky×Tm 1 (Kx×Ky×Tm) −1 本文(FC) A+W 是 多路选择 CSC F Tm Tm 1 *Eyeriss并没有利用稀疏性加速计算,所以系统并行自由度实际并没有影响性能。 **SCNN展开了I×F的乘法器,I×F=4×4,使用笛卡尔乘积方法完成并行展开了突触与特征图进行计算。 从表 1 中可知,几乎所有利用稀疏性加速卷 积神经网络计算的加速器都受到了负载失衡的影 响。文献 [11] 系统并行自由度仅受到参数稀疏度 不平衡性影响,这是因为它只对输出特征图方向 进行了展开,然而这种并行展开是有上限的,当 展开规模大于输出特征图数量时,继续并行展开 并不能提升计算性能。不考虑利用参数稀疏性的 情况下,和文献 [11] 相比,在同样负载失衡损失 条件下实现了 Kx×Ky 倍的并行展开规模和更小的 单位乘法器资源开销。和同样仅利用激活稀疏性 加速卷积计算的文献 [9] 相比,本文实现了比它 更低的负载失衡损失和更少的单位乘法器资源开 销。综上所述,本文提出的利用激活稀疏性加速 卷积神经网络计算,相比于同领域其他设计,并 行效率更高、额外资源开销更小。 3 硬件设计与实现 本文使用了具有 ARM+FPGA 的 Zynq 系列异 构计算体来设计卷积神经网络加速器。ARM 处理器部分被称为 PS 端,FPGA 被称为 PL 端,两 者之间通过多种接口互联。PS 端即 ARM 处理器 部分,我们运行了 linux 操作系统用于从文件中读 取权重和输入、测量时间并控制 DMA(direct memory access,直接内存存取) 等各个模块进程。PL 端 即 FPGA 部分,我们使用 HLS 工具设计了共用端 口的卷积计算模块与全连接计算 IP 核、可配置工 作模式的输入网络和输出网络、非线性激活 ReLU 模块、极大池化模块和数据整合模块,使用 SDSoC 工具完成了 DMA 与 PL-PS 交互控制设计。PS 与 PL 之间连接有 4 个高速的 HP 端口和 4 个中速的 GP 端口用于传输数据。整体架构如图 11 所示。 激活 输出 激活输入 权重 缓存 输出网络 核心 核心 核心 核心 全连接 核心 输入网络 权重 参数 直接内 存存取 控制器 片下存储 激活 池化 AXI 端口 数据 整合 图 11 系统整体架构 Fig. 11 Schematic diagram of the overall architecture 第 2 期 余成宇,等:一种高效的稀疏卷积神经网络加速器的设计与实现 ·329·