正在加载图片...
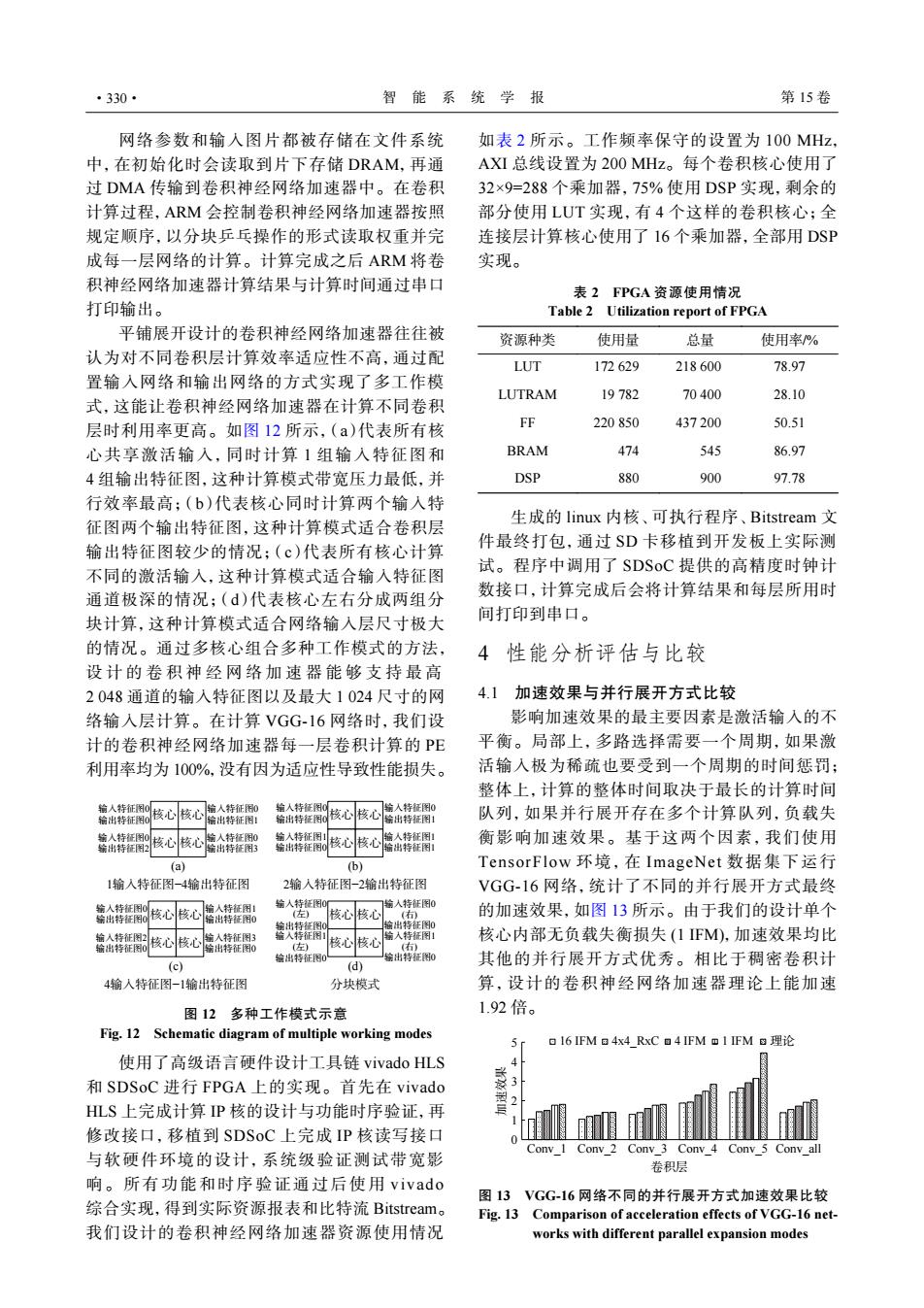
·330· 智能系统学报 第15卷 网络参数和输入图片都被存储在文件系统 如表2所示。工作频率保守的设置为100MHz, 中,在初始化时会读取到片下存储DRAM.再通 AXI总线设置为200MHz。每个卷积核心使用了 过DMA传输到卷积神经网络加速器中。在卷积 32×9=288个乘加器,75%使用DSP实现,剩余的 计算过程,ARM会控制卷积神经网络加速器按照 部分使用LUT实现,有4个这样的卷积核心;全 规定顺序,以分块乒乓操作的形式读取权重并完 连接层计算核心使用了16个乘加器,全部用DSP 成每一层网络的计算。计算完成之后ARM将卷 实现。 积神经网络加速器计算结果与计算时间通过串口 表2FPGA资源使用情况 打印输出。 Table 2 Utilization report of FPGA 平铺展开设计的卷积神经网络加速器往往被 资源种类 使用量 总量 使用率/% 认为对不同卷积层计算效率适应性不高,通过配 LUT 172629 218600 78.97 置输入网络和输出网络的方式实现了多工作模 LUTRAM 19782 70400 28.10 式,这能让卷积神经网络加速器在计算不同卷积 层时利用率更高。如图12所示,(a)代表所有核 FF 220850 437200 50.51 心共享激活输入,同时计算1组输入特征图和 BRAM 474 545 86.97 4组输出特征图,这种计算模式带宽压力最低,并 DSP 880 900 97.78 行效率最高;(b)代表核心同时计算两个输入特 征图两个输出特征图,这种计算模式适合卷积层 生成的linux内核、可执行程序、Bitstream文 输出特征图较少的情况;(c)代表所有核心计算 件最终打包,通过SD卡移植到开发板上实际测 不同的激活输入,这种计算模式适合输入特征图 试。程序中调用了SDSoC提供的高精度时钟计 通道极深的情况;(d)代表核心左右分成两组分 数接口,计算完成后会将计算结果和每层所用时 块计算,这种计算模式适合网络输入层尺寸极大 间打印到串口。 的情况。通过多核心组合多种工作模式的方法, 4性能分析评估与比较 设计的卷积神经网络加速器能够支持最高 2048通道的输入特征图以及最大1024尺寸的网 4.1加速效果与并行展开方式比较 络输入层计算。在计算VGG-16网络时,我们设 影响加速效果的最主要因素是激活输入的不 计的卷积神经网络加速器每一层卷积计算的PE 平衡。局部上,多路选择需要一个周期,如果激 利用率均为100%,没有因为适应性导致性能损失。 活输入极为稀疏也要受到一个周期的时间惩罚: 整体上,计算的整体时间取决于最长的计算时间 装价技心技心的人特 装金裤副核心度心信☆裤 输人特征图0 输出特征图! 队列,如果并行展开存在多个计算队列,负载失 的人棒征闲 编出特征图0 核心核心出特征图 给人棒征闲 衡影响加速效果。基于这两个因素,我们使用 (a) (b) TensorFlow环境,在ImageNet数据集下运行 1输入特征图-4输出特征图 2输入特征图-2输出特征图 VGG-16网络,统计了不同的并行展开方式最终 输人特征图0 给出特心 人营 核心核心 的加速效果,如图13所示。由于我们的设计单个 旋人持用闲核心核心旋人特征闲 核心内部无负载失衡损失(1FM),加速效果均比 输出特征图0 拿出特征图0 左) (c) 输出特征图0 (d) 其他的并行展开方式优秀。相比于稠密卷积计 4输入特征图-1输出特征图 分块模式 算,设计的卷积神经网络加速器理论上能加速 图12多种工作模式示意 1.92倍。 Fig.12 Schematic diagram of multiple working modes aI6IFMa4x4RxCa4IFMm1IFM⑧理论 使用了高级语言硬件设计工具链vivado HLS 和SDSoC进行FPGA上的实现。首先在vivado HLS上完成计算P核的设计与功能时序验证,再 2 修改接口,移植到SDSoC上完成IP核读写接口 Conv 1 Conv 2 Conv 3 Conv_4 Conv_5 Conv_all 与软硬件环境的设计,系统级验证测试带宽影 卷积层 响。所有功能和时序验证通过后使用vivado 图13VGG-16网络不同的并行展开方式加速效果比较 综合实现,得到实际资源报表和比特流Bitstream。 Fig.13 Comparison of acceleration effects of VGG-16 net- 我们设计的卷积神经网络加速器资源使用情况 works with different parallel expansion modes网络参数和输入图片都被存储在文件系统 中,在初始化时会读取到片下存储 DRAM,再通 过 DMA 传输到卷积神经网络加速器中。在卷积 计算过程,ARM 会控制卷积神经网络加速器按照 规定顺序,以分块乒乓操作的形式读取权重并完 成每一层网络的计算。计算完成之后 ARM 将卷 积神经网络加速器计算结果与计算时间通过串口 打印输出。 平铺展开设计的卷积神经网络加速器往往被 认为对不同卷积层计算效率适应性不高,通过配 置输入网络和输出网络的方式实现了多工作模 式,这能让卷积神经网络加速器在计算不同卷积 层时利用率更高。如图 12 所示,(a)代表所有核 心共享激活输入,同时计算 1 组输入特征图和 4 组输出特征图,这种计算模式带宽压力最低,并 行效率最高;(b)代表核心同时计算两个输入特 征图两个输出特征图,这种计算模式适合卷积层 输出特征图较少的情况;(c)代表所有核心计算 不同的激活输入,这种计算模式适合输入特征图 通道极深的情况;(d)代表核心左右分成两组分 块计算,这种计算模式适合网络输入层尺寸极大 的情况。通过多核心组合多种工作模式的方法, 设计的卷积神经网络加速器能够支持最高 2 048 通道的输入特征图以及最大 1 024 尺寸的网 络输入层计算。在计算 VGG-16 网络时,我们设 计的卷积神经网络加速器每一层卷积计算的 PE 利用率均为 100%,没有因为适应性导致性能损失。 核心 核心 核心 核心 核心 核心 核心 核心 核心 核心 核心 核心 核心 核心 核心 核心 (a) 1输入特征图−4输出特征图 4输入特征图−1输出特征图 输入特征图0 输出特征图0 输入特征图0 输出特征图2 输入特征图0 输出特征图1 输入特征图0 输出特征图3 输入特征图0 输出特征图0 输入特征图1 输出特征图0 输入特征图0 输出特征图1 输入特征图1 输出特征图1 输入特征图0 输出特征图0 输入特征图2 输出特征图0 输入特征图1 输出特征图0 输入特征图3 输出特征图0 (c) (b) 2输入特征图−2输出特征图 (d) 分块模式 输入特征图0 (左) (左) 输出特征图0 输入特征图1 输出特征图0 输入特征图0 (右) (右) 输出特征图0 输入特征图1 输出特征图0 图 12 多种工作模式示意 Fig. 12 Schematic diagram of multiple working modes 使用了高级语言硬件设计工具链 vivado HLS 和 SDSoC 进行 FPGA 上的实现。首先在 vivado HLS 上完成计算 IP 核的设计与功能时序验证,再 修改接口,移植到 SDSoC 上完成 IP 核读写接口 与软硬件环境的设计,系统级验证测试带宽影 响。所有功能和时序验证通过后使用 vivado 综合实现,得到实际资源报表和比特流 Bitstream。 我们设计的卷积神经网络加速器资源使用情况 如表 2 所示。工作频率保守的设置为 100 MHz, AXI 总线设置为 200 MHz。每个卷积核心使用了 32×9=288 个乘加器,75% 使用 DSP 实现,剩余的 部分使用 LUT 实现,有 4 个这样的卷积核心;全 连接层计算核心使用了 16 个乘加器,全部用 DSP 实现。 表 2 FPGA 资源使用情况 Table 2 Utilization report of FPGA 资源种类 使用量 总量 使用率/% LUT 172 629 218 600 78.97 LUTRAM 19 782 70 400 28.10 FF 220 850 437 200 50.51 BRAM 474 545 86.97 DSP 880 900 97.78 生成的 linux 内核、可执行程序、Bitstream 文 件最终打包,通过 SD 卡移植到开发板上实际测 试。程序中调用了 SDSoC 提供的高精度时钟计 数接口,计算完成后会将计算结果和每层所用时 间打印到串口。 4 性能分析评估与比较 4.1 加速效果与并行展开方式比较 影响加速效果的最主要因素是激活输入的不 平衡。局部上,多路选择需要一个周期,如果激 活输入极为稀疏也要受到一个周期的时间惩罚; 整体上,计算的整体时间取决于最长的计算时间 队列,如果并行展开存在多个计算队列,负载失 衡影响加速效果。基于这两个因素,我们使用 TensorFlow 环境,在 ImageNet 数据集下运行 VGG-16 网络,统计了不同的并行展开方式最终 的加速效果,如图 13 所示。由于我们的设计单个 核心内部无负载失衡损失 (1 IFM),加速效果均比 其他的并行展开方式优秀。相比于稠密卷积计 算,设计的卷积神经网络加速器理论上能加速 1.92 倍。 0 1 2 3 4 5 Conv_1 Conv_2 Conv_3 Conv_4 Conv_5 Conv_all 加速效果 卷积层 16 IFM 4x4_RxC 4 IFM 1 IFM 理论 图 13 VGG-16 网络不同的并行展开方式加速效果比较 Fig. 13 Comparison of acceleration effects of VGG-16 networks with different parallel expansion modes ·330· 智 能 系 统 学 报 第 15 卷