正在加载图片...
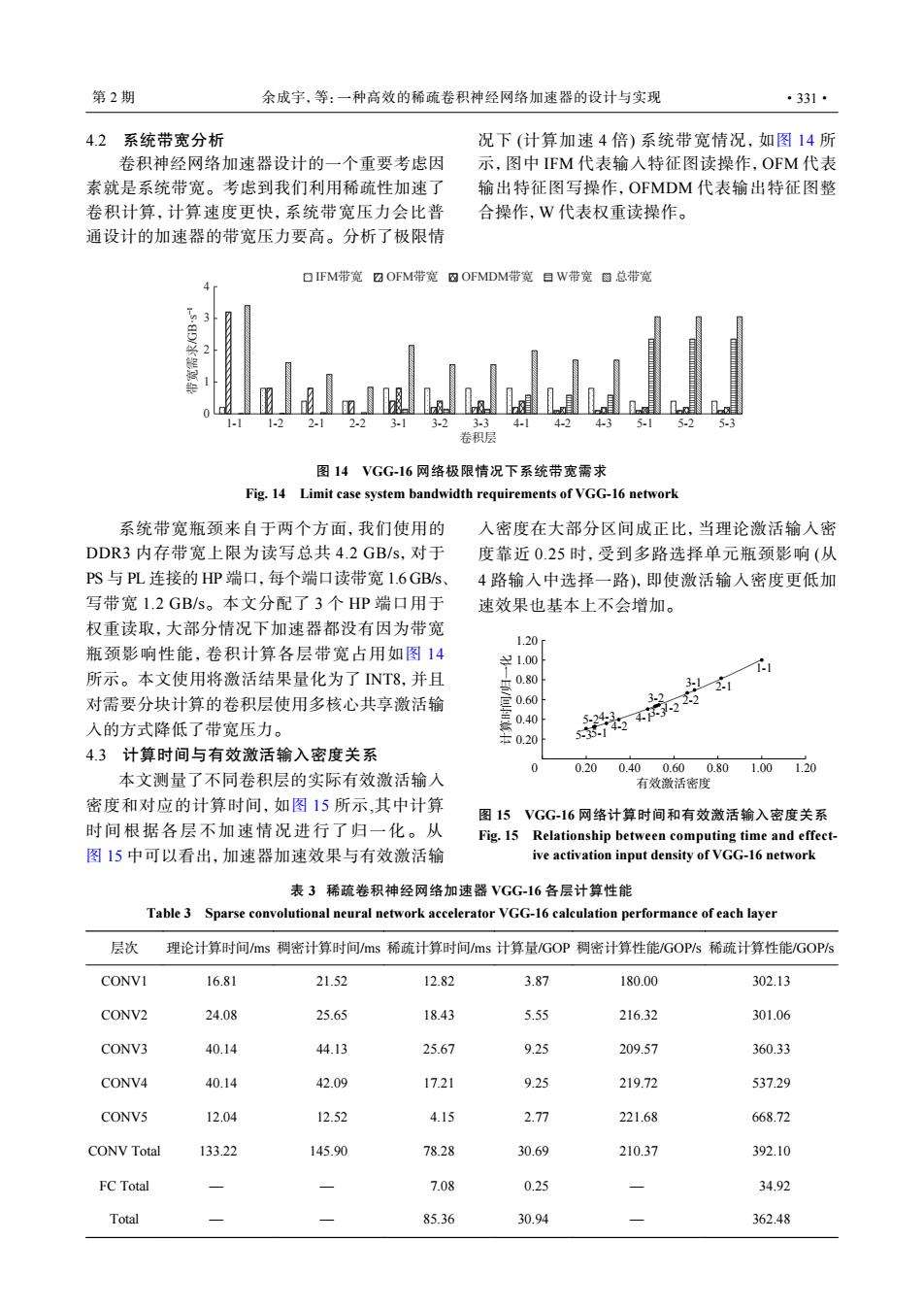
第2期 余成字,等:一种高效的稀疏卷积神经网络加速器的设计与实现 ·331· 4.2系统带宽分析 况下(计算加速4倍)系统带宽情况,如图14所 卷积神经网络加速器设计的一个重要考虑因 示,图中IFM代表输入特征图读操作,OFM代表 素就是系统带宽。考虑到我们利用稀疏性加速了 输出特征图写操作,OFMDM代表输出特征图整 卷积计算,计算速度更快,系统带宽压力会比普 合操作,W代表权重读操作。 通设计的加速器的带宽压力要高。分析了极限情 OIFM带宽☑OFM带宽四OFMDM带宽目W带宽圈总带宽 3 1- 1-2 2-1 2-2 3-1 3-2 3-3 4-1 4-2 43 5-1 5.2 5.3 卷积层 图14VGG-16网络极限情况下系统带宽需求 Fig.14 Limit case system bandwidth requirements of VGG-16 network 系统带宽瓶颈来自于两个方面,我们使用的 入密度在大部分区间成正比,当理论激活输入密 DDR3内存带宽上限为读写总共4.2GB/s,对于 度靠近0.25时,受到多路选择单元瓶颈影响(从 PS与PL连接的HP端口,每个端口读带宽1.6GBs、 4路输入中选择一路),即使激活输人密度更低加 写带宽1.2GB/s。本文分配了3个HP端口用于 速效果也基本上不会增加。 权重读取,大部分情况下加速器都没有因为带宽 1.20 瓶颈影响性能,卷积计算各层带宽占用如图14 ¥1.00 所示。本文使用将激活结果量化为了NT8,并且 g080 对需要分块计算的卷积层使用多核心共享激活输 0.60 入的方式降低了带宽压力。 0.20 4.3计算时间与有效激活输入密度关系 0 0.20 0.400.600.80 1.001.20 本文测量了不同卷积层的实际有效激活输入 有效激活密度 密度和对应的计算时间,如图15所示,其中计算 图15VGG-16网络计算时间和有效激活输入密度关系 时间根据各层不加速情况进行了归一化。从 Fig.15 Relationship between computing time and effect- 图15中可以看出,加速器加速效果与有效激活输 ive activation input density of VGG-16 network 表3稀疏卷积神经网络加速器VGG-16各层计算性能 Table3 Sparse convolutional neural network accelerator VGG-16 calculation performance of each layer 层次 理论计算时间/ms稠密计算时间/ms稀疏计算时间/ms计算量/GOP稠密计算性能/GOPs稀疏计算性能/GOPs CONVI 16.81 21.52 12.82 3.87 180.00 302.13 CONV2 24.08 25.65 18.43 5.55 216.32 301.06 CONV3 40.14 44.13 25.67 9.25 209.57 360.33 CONV4 40.14 42.09 17.21 9.25 219.72 537.29 CONV5 12.04 12.52 4.15 2.77 221.68 668.72 CONV Total 133.22 145.90 78.28 30.69 210.37 392.10 FCTotal -- 7.08 0.25 34.92 Total 85.36 30.94 362.484.2 系统带宽分析 卷积神经网络加速器设计的一个重要考虑因 素就是系统带宽。考虑到我们利用稀疏性加速了 卷积计算,计算速度更快,系统带宽压力会比普 通设计的加速器的带宽压力要高。分析了极限情 况下 (计算加速 4 倍) 系统带宽情况,如图 14 所 示,图中 IFM 代表输入特征图读操作,OFM 代表 输出特征图写操作,OFMDM 代表输出特征图整 合操作,W 代表权重读操作。 0 1 2 3 4 1-1 1-2 2-1 2-2 3-1 3-2 3-3 4-1 4-2 4-3 5-1 5-2 5-3 带宽需求/GB·s−1 卷积层 IFM带宽 OFM带宽 OFMDM带宽 W带宽 总带宽 图 14 VGG-16 网络极限情况下系统带宽需求 Fig. 14 Limit case system bandwidth requirements of VGG-16 network 系统带宽瓶颈来自于两个方面,我们使用的 DDR3 内存带宽上限为读写总共 4.2 GB/s,对于 PS 与 PL 连接的 HP 端口,每个端口读带宽 1.6 GB/s、 写带宽 1.2 GB/s。本文分配了 3 个 HP 端口用于 权重读取,大部分情况下加速器都没有因为带宽 瓶颈影响性能,卷积计算各层带宽占用如图 14 所示。本文使用将激活结果量化为了 INT8,并且 对需要分块计算的卷积层使用多核心共享激活输 入的方式降低了带宽压力。 4.3 计算时间与有效激活输入密度关系 本文测量了不同卷积层的实际有效激活输入 密度和对应的计算时间,如图 15 所示,其中计算 时间根据各层不加速情况进行了归一化。从 图 15 中可以看出,加速器加速效果与有效激活输 入密度在大部分区间成正比,当理论激活输入密 度靠近 0.25 时,受到多路选择单元瓶颈影响 (从 4 路输入中选择一路),即使激活输入密度更低加 速效果也基本上不会增加。 1-1 1-2 2-1 2-2 3-1 3-2 3-3 4-1 4-2 4-3 5-1 5-2 5-3 0.20 0.40 0.60 0.80 1.00 1.20 0 0.20 0.40 0.60 0.80 1.00 1.20 计算时间/归一化 有效激活密度 图 15 VGG-16 网络计算时间和有效激活输入密度关系 Fig. 15 Relationship between computing time and effective activation input density of VGG-16 network 表 3 稀疏卷积神经网络加速器 VGG-16 各层计算性能 Table 3 Sparse convolutional neural network accelerator VGG-16 calculation performance of each layer 层次 理论计算时间/ms 稠密计算时间/ms 稀疏计算时间/ms 计算量/GOP 稠密计算性能/GOP/s 稀疏计算性能/GOP/s CONV1 16.81 21.52 12.82 3.87 180.00 302.13 CONV2 24.08 25.65 18.43 5.55 216.32 301.06 CONV3 40.14 44.13 25.67 9.25 209.57 360.33 CONV4 40.14 42.09 17.21 9.25 219.72 537.29 CONV5 12.04 12.52 4.15 2.77 221.68 668.72 CONV Total 133.22 145.90 78.28 30.69 210.37 392.10 FC Total — — 7.08 0.25 — 34.92 Total — — 85.36 30.94 — 362.48 第 2 期 余成宇,等:一种高效的稀疏卷积神经网络加速器的设计与实现 ·331·